[논문 리뷰] AtMan: Understanding Transformer Predictions Through Memory Efficient Attention Manipulation
AtMan은 주의 점수를 조작하여 트랜스포머 예측을 조향하는 메모리 효율적인扰 perturbation 기반 XAI 방법으로, 대형 다중모달 모델에 대해 추가 메모리 최소화와 텍스트 및 이미지-텍스트 작업에서 그래디언트 기반 기법 대비 향상된 정확도를 가능하게 하는 설명을 제공합니다.
Generative transformer models have become increasingly complex, with large numbers of parameters and the ability to process multiple input modalities. Current methods for explaining their predictions are resource-intensive. Most crucially, they require prohibitively large amounts of extra memory, since they rely on backpropagation which allocates almost twice as much GPU memory as the forward pass. This makes it difficult, if not impossible, to use them in production. We present AtMan that provides explanations of generative transformer models at almost no extra cost. Specifically, AtMan is a modality-agnostic perturbation method that manipulates the attention mechanisms of transformers to produce relevance maps for the input with respect to the output prediction. Instead of using backpropagation, AtMan applies a parallelizable token-based search method based on cosine similarity neighborhood in the embedding space. Our exhaustive experiments on text and image-text benchmarks demonstrate that AtMan outperforms current state-of-the-art gradient-based methods on several metrics while being computationally efficient. As such, AtMan is suitable for use in large model inference deployments.
연구 동기 및 목표
- 대규모 생성형 트랜스포머에서 역전파 기반 XAI가 메모리 소모가 많다는 점을 고려한 확장 가능한 설명 필요성 제시.
- 입력 레벨이 아닌 임베딩 토큰 공간에서 perturbation을 일으켜 입력의 관련성 맵을 생성하는 메모리 효율적 주의 조작 교란 방법 AtMan 제안.
- 추가 메모리 오버헤드 없이 AtMan이 perturbation 요구를 줄이고 대형 모델로 확장될 수 있음을 보여줌.
- 텍스트 및 이미지-텍스트 벤치마크에서 AtMan이 그래디언트 기반 XAI 방법과 비교해 경쟁력 있거나 우수한 성능을 보임.
제안 방법
- 설명 가능성을 모델의 출력에 가장 큰 영향을 주는 입력 부분을 교란을 통해 식별하는 문제로 정의.
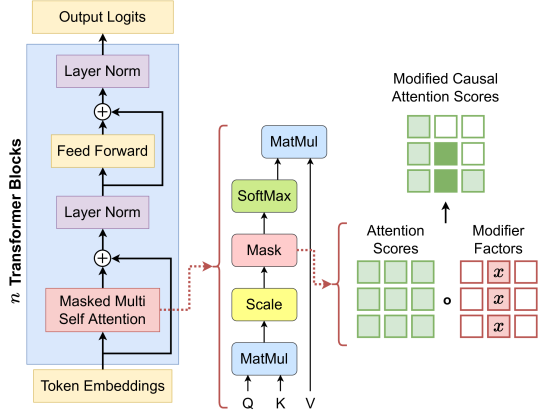
- 가중치가 아니라 주의 점수를 교란하여 입력 공간에서 임베딩 토큰 공간으로 perturbation 공간을 이동시킴.
- 주어진 토큰의 주의 기여도를 스케일링하여 예측을 조정하는 단일 토큰 주의 억제를 정의(스케일링 계수 f).
- 임베딩 공간에서 코사인 유사도를 사용하여 상관 토큰 억제를 확장하여 토큰 간 중복 정보를 억제.
- 전처-softmax 주의 H를 토큰별 억제 매트릭스로 수정하는 닫힌 형식의 식(Eq. 4)과 영향 점수 벡터로 누적되는 설명(Eq. 5)을 제공.
- 토큰 이웃 관계를 고려하고 노이즈가 많은 할당을 줄이기 위해 상관 토큰 억제(Eq. 6) 적용.
- 텍스트 및 이미지-언어 모델에서의 실험을 통해 확장성과 메모리 효율성을 입증하고 그레이디언트 기반 XAI 기법과 비교.

실험 결과
연구 질문
- RQ1AtMan이 언어 모델 및 비전-언어 모델에서 그래디언트 기반 XAI 방법과 비교해 경쟁력 있는 설명을 제공할 수 있는가?
- RQ2AtMan이 대형 자기회귀 트랜스포머 및 다중모달 모델에 대해 비례하는 메모리 비용 없이 확장 가능한가?
- RQ3상관 토큰 억제가 다중모달 설정에서 설명의 강건성을 향상시키는가?
- RQ4AtMan 설명이 QA/VQA 벤치마크에서 인간 주석 또는 실제 설명 신호와 일치하는가?
주요 결과
- AtMan은 텍스트 QA 및 이미지-텍스트 VQA 벤치마크에서 그래디언트 기반 기법 대비 평균 정밀도(Mean Average Precision) 및 관련 지표에서 우수한 성과를 보임.
- AtMan은 순방향 패스와 비슷한 메모리 사용량을 유지하여 그래디언트 기반 XAI가 메모리 제약으로 실패하는 대형 모델의 배포를 가능하게 함.
- AtMan은 MAGMA 변형(6B, 13B, 30B) 및 BLIP에서 경쟁력 있는 성능을 보여 모델에 구애받지 않는 적용 가능성을 시사.
- 상관 토큰 억제가 임베딩 공간의 코사인 유사도를 활용해 중복 정보를 억제함으로써 설명 품질을 향상시킴.
- SQuAD(텍스트) 및 OpenImages(시각)에서 AtMan이 IxG, IG, GradCAM, Chefer보다 대부분의 평가 설정에서 더 높은 정밀도/재현율을 보임.
- 대규모 하드웨어(80GB A100)에서 그래디언트 기반 방법이 메모리 한계를 넘길 때도 AtMan은 실행 가능성을 유지하여 확장성을 보여줌.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.