[논문 리뷰] Attacking Large Language Models with Projected Gradient Descent
논문은 LLM에 대해 연속적으로 이완된 토큰 시퀀스에서 작동하는 Projected Gradient Descent (PGD) 공격을 제시하여 이산 최적화 방식과 비슷한 공격 강도를 달성하면서 실행 시간이 최대 10x 빠르다.
Current LLM alignment methods are readily broken through specifically crafted adversarial prompts. While crafting adversarial prompts using discrete optimization is highly effective, such attacks typically use more than 100,000 LLM calls. This high computational cost makes them unsuitable for, e.g., quantitative analyses and adversarial training. To remedy this, we revisit Projected Gradient Descent (PGD) on the continuously relaxed input prompt. Although previous attempts with ordinary gradient-based attacks largely failed, we show that carefully controlling the error introduced by the continuous relaxation tremendously boosts their efficacy. Our PGD for LLMs is up to one order of magnitude faster than state-of-the-art discrete optimization to achieve the same devastating attack results.
연구 동기 및 목표
- 효율적인 자동적 레드 팀 구축 LLMS를 동기부여하고 가능하게 한다.
- 연속 이완을 통한 그래디언트 기반 최적화가 이산 공격과 효과성에서 동등하게 맞출 수 있음을 보여준다.
- 최적화가 확률적 단순체 위에 머무르도록 제어하고 이완 오차를 관리하는 프로젝션 기반 프레임워크를 개발한다.
- 대규모 평가 및 적대적 학습에 대해 최신 공격 대비 효율 gains를 입증한다.
제안 방법
- 확률적 단순체 위의 원-핫 입력 토큰의 연속 이완을 공식화한다.
- 각 단계 후 이완된 입력에 그래디언트 기반 업데이트를 적용하고 다시 단순체에 투영한다.
- 이완 오차를 한정하고 이산성을 장려하기 위해 엔트로피(Gini) 투영을 사용한다.
- 토큰 마스크를 통해 differentiable 길이 유연성을 도입하여 주의에서 토큰의 매끄러운 삽입/제거를 가능하게 한다.
- 이완 후 토큰별 argmax를 취해 이완된 시퀀스에서 공격 목적을 평가한다.
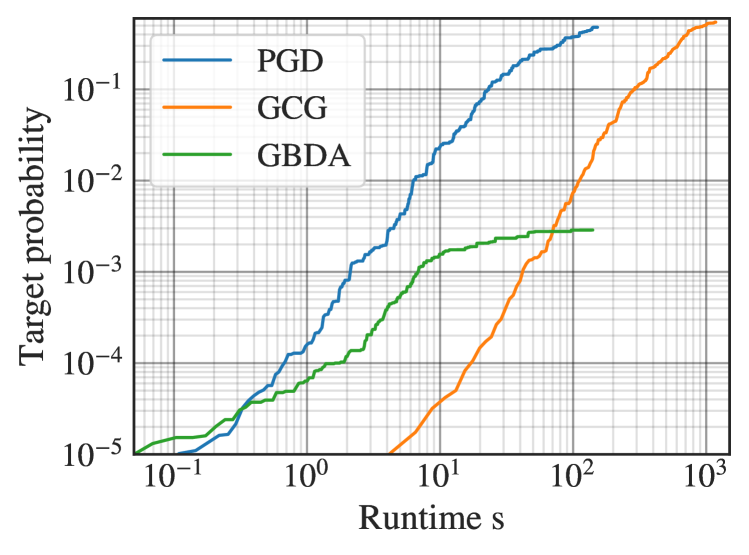
실험 결과
연구 질문
- RQ1연속 이완을 통한 그래디언트 기반 최적화가 Jailbreaking 작업에서 정렬된 LLM에 효과적으로 공격할 수 있는가?
- RQ2PGD가 공격 효과성과 계산 효율성 면에서 이산 최적화 방법과 어떻게 비교되는가?
- RQ3엔트로피 기반 투영이 이완 오차에 대항하여 신뢰성을 향상시키는가?
- RQ4가변 시퀀스 길이를 허용하는 것이 공격 성능을 더 개선하는가?
주요 결과
| Attack | ASR @ 60 s | Iter. / s |
|---|---|---|
| PGD | 87 % | 28.2 |
| GCG | 83 % | 0.3 |
| GBDA | 40 % | 29.3 |
- PGD는 이산 최적화 최신 방법과 동일하거나 더 강력한 공격 강도를 달성하면서 실행 시간이 최대 한 자릿수로 감소하는 이점을 보인다.
- 행동 jailbreaking 태스크에서 PGD는 60초 시점에서 87%의 공격 성공률을 달성했고, GCG는 83%, GBDA는 40%를 보였다.
- PGD는 탐색 공간을 대략 65,000개에서 각 위치당 약 10개의 후보 토큰으로 축소한다.
- ablation의 교차 엔트로피 결과는 개선을 보여준다: 0.092±0.014(비이완), 0.085±0.010(Entropy 투영 없는 이완), 0.078±0.009(Entropy 투영 있는 이완).
- PGD의 효율성 우위는 Vicuna 7B, Falcon 7B 및 Falcon 7B Instruct 모델 전반에 걸쳐 입증된다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.