[논문 리뷰] Automatic acoustic detection of birds through deep learning: the first Bird Audio Detection challenge
논문은 공개 데이터 챌린지를 통해 심층 학습이 미지의 음향 조건에서 일반 목적 새 탐지에서 높은 일반화 성능을 달성할 수 있음을 보여주며, 최고 AUC는 약 88%이고 다양한 데이터셋에 걸친 강한 일반화를 보인다.
Assessing the presence and abundance of birds is important for monitoring specific species as well as overall ecosystem health. Many birds are most readily detected by their sounds, and thus passive acoustic monitoring is highly appropriate. Yet acoustic monitoring is often held back by practical limitations such as the need for manual configuration, reliance on example sound libraries, low accuracy, low robustness, and limited ability to generalise to novel acoustic conditions. Here we report outcomes from a collaborative data challenge showing that with modern machine learning including deep learning, general-purpose acoustic bird detection can achieve very high retrieval rates in remote monitoring data --- with no manual recalibration, and no pre-training of the detector for the target species or the acoustic conditions in the target environment. Multiple methods were able to attain performance of around 88% AUC (area under the ROC curve), much higher performance than previous general-purpose methods. We present new acoustic monitoring datasets, summarise the machine learning techniques proposed by challenge teams, conduct detailed performance evaluation, and discuss how such approaches to detection can be integrated into remote monitoring projects.
연구 동기 및 목표
- 원격 음향 모니터링에서 종 특이적 조정이나 환경 특이 보정을 필요로 하지 않는 견고하고 일반-purpose한 새 탐지 성능을 촉진한다.
- 일반화를 테스트하기 위해 원격 모니터링 및 크라우드소스 소스에서 다양한 주석 데이터셋을 생성한다.
- 공통적이고 비편향 탐지 작업을 AUC로 평가하여 베이스라인과 딥러닝 방법을 벤치마크한다.
- 현장 배치 deployment를 위한 보정(calibration) 및 실환경 모니터링 그리드에서의 오차 유형을 분석한다.
제안 방법
- 다중 소스 데이터셋(Chernobyl CEZ, Warblr 크라우드소싱, freefield1010, PolandNFC)을 수집하고 10초 클립에 새가 있는지/없는지 라벨링한다.
- 일반 탐지 작업 정의: 각 10초 클립을 새의 존재 여부로 라벨링하여 ±10초의 정확한 시간 위치화를 가능하게 한다.
- 참가자에게 개발 데이터를 제공하고 과적합을 방지하기 위해 개인 테스트 데이터를 제공하며 일반화 테스트를 위한 별도 데이터셋을 마련한다.
- 베이스라인 분류기: smacpy(MFCCs와 가우시안 혼합 모델)와 skfl(Mel 스펙rogram에 대한 비지도 특징 학습과 랜덤 포레스트)이다.
- 참가자들은 스펙트로그램(Mel) 입력과 데이터 증강을 사용한 딥러닝 접근법(CNN이 주를 이룸)을 활용했고, 출력은 AUC를 계산하는 확률 점수로 사용된다.
- 평가는 보지 않은 조건과 사이트 전반의 일반화 및 보정 도표(calibration plots)를 통한 보정 분석에 중점을 두었다.
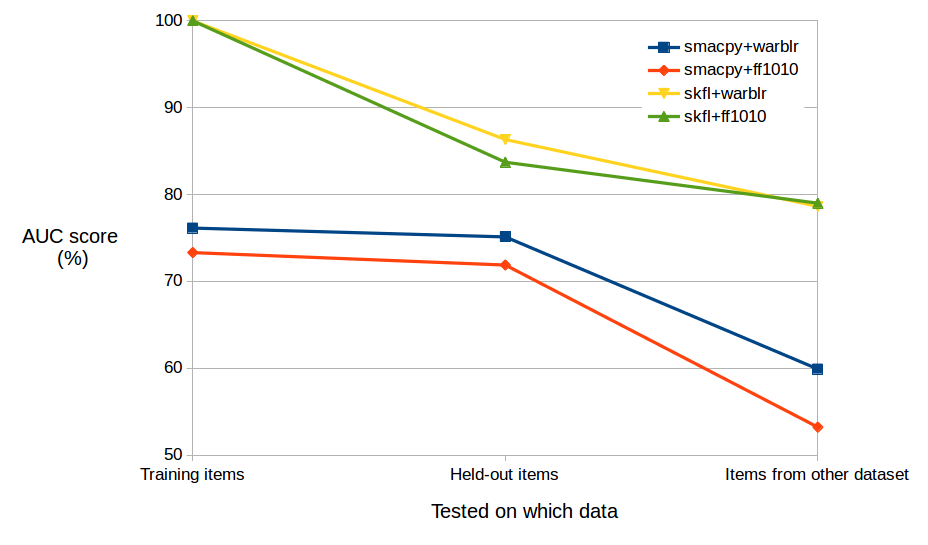
실험 결과
연구 질문
- RQ1일반 목적의 종-무관 탐지기가 환경 특이 조정 없이도 높은 새 탐지 성능을 달성할 수 있는가?
- RQ2탐지 방법이 보지 않은 음향 환경 및 데이터 소스에 얼마나 잘 일반화되는가?
- RQ3딥러닝 기반 탐지기의 보정 특성은 어떤지, 사이트(예: Warblr vs. Chernobyl) 간에 어떻게 달라지는가?
- RQ4도전적인 녹음(저 SNR, 바람, 곤충 소음, 인간 활동 등)에서 일반적으로 나타나는 오류 원인은 무엇이며 탐지를 제한하는가?
주요 결과
- 딥러닝 방법은 강한 성능을 달성했으며 대부분의 팀이 80%를 초과했고 최고 점수는 88.7%의 AUC에 도달했다.
- 재검증된 테스트 세트에서의 평가자 간 신뢰도는 높았으며(AUC 96.7%) 재검증 프로토콜 하에서 인간과 기계 판단 간에 상당한 합의가 나타났다.
- 사이트별 성능 변화가 있었다. Warblr 데이터는 쉽게 탐지되었고(AUC > 95%), 일부 CEZ 위치는 도전적하여 주요 방법에서 AUC가 약 80%대까지 떨어졌다.
- 탐지의 보정은 데이터셋에 따라 달랐으며, 일부 최상위 방법은 보인 데이터에서의 보정은 좋았으나 보지 않은 CEZ 데이터에서의 보정은 다소 미흡하여 배치 시 보정이 별도의 고려사항임이 드러났다.
- 대다수 제출물은 스펙트로그램/멜 표현과 데이터 증강을 사용했고, CNN 기반 딥러닝 접근이 상위 결과를 주도했다.
- 가장 우수한 탐지는 사이트 기반 분석에서 여전히 강한 일반화 경향을 보였으나, 사이트별 평가 시 정확한 순위는 다소 달랐다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.