[논문 리뷰] Be Your Own Prada: Fashion Synthesis with Structural Coherence
이 논문은 입력 이미지와 자연어 설명을 조건으로 하여 착용자의 신체 자세와 체형을 유지하면서 구조적으로 일관되고 영역별로 특정된 옷 텍스처를 생성하는 이단계 GAN 프레임워크를 제안한다. 먼저 공간 제약 조건을 적용한 세그멘테이션 맵을 생성한 후, 구성적 매핑 레이어를 사용해 텍스처를 렌더링함으로써, 정량적 지표와 평균 순위 1.544를 기록한 사용자 연구를 통해 기존 방법들에 비해 뛰어난 구조적 일관성과 시각적 품질을 달성한다.
We present a novel and effective approach for generating new clothing on a wearer through generative adversarial learning. Given an input image of a person and a sentence describing a different outfit, our model "redresses" the person as desired, while at the same time keeping the wearer and her/his pose unchanged. Generating new outfits with precise regions conforming to a language description while retaining wearer's body structure is a new challenging task. Existing generative adversarial networks are not ideal in ensuring global coherence of structure given both the input photograph and language description as conditions. We address this challenge by decomposing the complex generative process into two conditional stages. In the first stage, we generate a plausible semantic segmentation map that obeys the wearer's pose as a latent spatial arrangement. An effective spatial constraint is formulated to guide the generation of this semantic segmentation map. In the second stage, a generative model with a newly proposed compositional mapping layer is used to render the final image with precise regions and textures conditioned on this map. We extended the DeepFashion dataset [8] by collecting sentence descriptions for 79K images. We demonstrate the effectiveness of our approach through both quantitative and qualitative evaluations. A user study is also conducted. The codes and the data are available at http://mmlab.ie.cuhk. edu.hk/projects/FashionGAN/.
연구 동기 및 목표
- 입력 이미지와 자연어 설명을 조건으로 하여 착용자의 신체 자세와 체형을 유지하면서 새로운 옷을 생성하는 것을 목표로 한다.
- 입력 이미지와 자연어 설명을 동시에 조건으로 하여 패션 생성에서의 구조적 일관성 문제를 해결하는 것.
- 이미지 생성 과정에서 전반적인 구조 유지와 뿌연 아티팩트 방지를 위해 기존 GAN의 한계를 극복하는 것.
- 결손된 신체 부위(예: 팔)를 환영할 수 있도록 하되, 신체 부위의 일관된 가시성을 보장하는 방법을 개발하는 것.
- 정량적 지표와 사용자 연구를 통해 모델 성능을 평가하는 것 — 세그멘테이션 현실성과 이미지 품질을 중심으로.
제안 방법
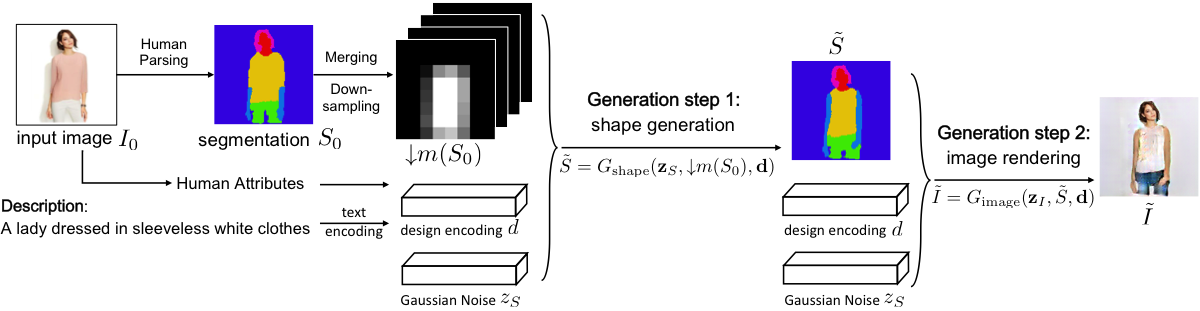
- 이 방법은 이단계 GAN을 사용한다: 첫 번째 단계에서 입력 이미지와 텍스트를 조건으로 세그멘테이션 맵을 생성하고, 두 번째 단계에서 맵과 텍스트를 이용해 최종 이미지를 렌더링한다.
- 입력 이미지로부터 유도된 새로운 공간 제약 조건을 제안하여 첫 번째 단계 GAN이 착용자의 자세와 신체 구조를 텍스트 설명과 모순되지 않도록 유지하도록 이끈다.
- 두 번째 단계 생성자는 영역별 텍스처 합성 기능을 향상시키기 위해 새로운 구성적 매핑 레이어를 사용하여, 비구성적 GAN에 비해 일관성 향상과 뿌연 아티팩트 감소를 달성한다.
- 79,000장의 상체 이미지로 구성된 확장된 DeepFashion 데이터셋을 사용하여 학습하며, 문장 기반 설명과 신체 부위 레이블이 부여되어 있다.
- 첫 번째 단계 GAN은 신체 부위와 의류 영역을 정의하는 세그멘테이션 맵을 생성하여 입력 이미지와의 구조적 일관성을 확보한다.
- 두 번째 단계 GAN은 세그멘테이션 맵과 텍스트 임bedding을 동시에 사용하여 정밀한 텍스처와 일관된 신체 부위 가시성을 가진 사진 수준의 이미지를 생성한다.

실험 결과
연구 질문
- RQ1단일 입력 이미지와 텍스트 설명을 조건으로 하여 착용자의 신체 자세와 체형을 유지하면서도 높은 구조적 일관성을 가지는 패션 이미지를 생성할 수 있는가?
- RQ2입력 이미지에서 유도된 공간 제약 조건이 텍스트 설명과 충돌하지 않으면서도 타당한 세그멘테이션 맵 생성에 얼마나 효과적인가?
- RQ3비구성적 GAN에 비해 구성적 매핑 레이어가 패션 생성에서 영역별 텍스처 렌더링에 얼마나 효과적인가?
- RQ4사용자 참여자가 생성된 세그멘테이션 맵의 현실성과 최종 이미지의 시각적 품질을 기존 방법들과 비교해 얼마나 잘 인식하는가?
- RQ5모델이 평탄한 배경 외의 다양한 배경 타입과 새로운 의상 유형으로 일반화 가능한가? 특히 평탄한 배경만 포함된 데이터셋으로 훈련한 경우에 대해.
주요 결과
- 사용자 연구에서 제안된 방법은 평균 순위 1.544를 기록하여 모든 기준 방법들(비모수적 2D 방법, 평균 순위 2.286)을 뛰어넘는 성능을 보였다.
- 모델이 생성한 세그멘테이션 맵은 참가자 42%가 실제 이미지로 오인할 정도로 높은 현실성과 타당성을 보였으며, 중간 출력의 질적 수준이 높음을 시사한다.
- 구성적 매핑 레이어가 비구성적 기준 방법과의 정성적 비교를 통해 뿌연 아티팩트 감소와 영역별 텍스처 일관성 향상을 효과적으로 달성했다.
- 공간 제약 조건이 적용된 이단계 프레임워크는 아티팩트를 크게 줄이고 특히 결손된 신체 부위를 환영해야 하는 경우의 구조적 일관성을 향상시켰다.
- 사용자 순위와 정성적 결과를 바탕으로 볼 때, 모델은 한 단계 GAN 기준 방법들(예: One-Step-8-7 및 One-Step-8-4)보다 시각적 품질과 형태 일관성에서 뛰어난 성능을 보였다.
- 훈련 데이터에 무늬 배경이 포함된 경우, 잠재 벡터가 배경 분포를 포괄하므로 별도의 배경 모델링 없이도 모델이 무늬 배경으로 일반화 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.