[논문 리뷰] Benchmarking Large Language Models for News Summarization
이 논문은 뉴스 요약에 대해 열 개의 LLM을 대상으로 포괄적인 인간 평가를 수행하고, 지시 미세 조정이 모델 크기보다 제로샷 성능에 더 큰 영향을 미친다는 것을 발견하며, 고품질 프리랜스 요약이 참조 기반 지표의 한계를 드러낸다.
Large language models (LLMs) have shown promise for automatic summarization but the reasons behind their successes are poorly understood. By conducting a human evaluation on ten LLMs across different pretraining methods, prompts, and model scales, we make two important observations. First, we find instruction tuning, and not model size, is the key to the LLM's zero-shot summarization capability. Second, existing studies have been limited by low-quality references, leading to underestimates of human performance and lower few-shot and finetuning performance. To better evaluate LLMs, we perform human evaluation over high-quality summaries we collect from freelance writers. Despite major stylistic differences such as the amount of paraphrasing, we find that LMM summaries are judged to be on par with human written summaries.
연구 동기 및 목표
- LLMs의 제로샷 뉴스 요약 성능에 기여하는 설계 결정 식별.
- 모델 규모, 프롬프트, 지시 미세 조정이 요약 품질에 미치는 영향 평가.
- LLM 요약에 대한 표준 참조 기반 지표의 신뢰성 평가.
- LLM 출력과 프리랜스 작가의 고품질 인간 요약 비교.
- 향후 벤치마킹을 위한 고품질 평가 데이터 및 리소스 제공.
제안 방법
- CNN/Daily Mail 및 XSUM 데이터세트에 걸친 열 가지 다양한 LLM에 대한 체계적 인간 평가.
- 세 가지 어노테이터 평가 기준 사용: 성실성(이진), 일관성(1–5), 관련성(1–5).
- 제로샷과 소샷 프롬프트 비교, 파인튜닝 기준선(Pegasus, BRIO) 포함.
- Upwork에서 고품질 프리랜스 요약을 모집하여 인간 수준의 성능과 지표 신뢰성 평가.
- 잘라내기/붙여넣기 작업 분류를 통한 추출성 대 추상적 스타일 분석.
- 17개 모델 설정 및 두 데이터세트에 대한 평가 데이터 공개.
실험 결과
연구 질문
- RQ1지시 조정된 LLM이 제로샷 뉴스 요약에서 규모 중심의 비지시 조정 모델을 능가하는가?
- RQ2고품질 인간 참조가 LLM 및 파인튜닝 모델의 인식된 성능과 실제 성능에 어떤 영향을 미치는가?
- RQ3참조 기반 자동 지표가 CNN/Daily Mail 및 XSUM에서 고품질 LLM 출력 평가에 신뢰할 수 있는가?
- RQ4LLM 요약이 프리랜스 인간 요약과 비교할 때 충실도, 일관성, 정보 전달력 면에서 어떤 차이가 있는가?
주요 결과
| Model | Faithfulness CNN/DM | Coherence CNN/DM | Relevance CNN/DM | Faithfulness XSUM | Coherence XSUM | Relevance XSUM |
|---|---|---|---|---|---|---|
| GPT-3 (350M) | 0.29 | 1.92 | 1.84 | 0.26 | 2.03 | 1.90 |
| GPT-3 (6.7B) | 0.29 | 1.77 | 1.93 | 0.77 | 3.16 | 3.39 |
| GPT-3 (175B) | 0.76 | 2.65 | 3.50 | 0.80 | 2.78 | 3.52 |
| Ada Instruct v1 (350M*) | 0.88 | 4.02 | 4.26 | 0.81 | 3.90 | 3.87 |
| Curie Instruct v1 (6.7B*) | 0.97 | 4.24 | 4.59 | 0.96 | 4.27 | 4.34 |
| Davinci Instruct v2 (175B*) | 0.99 | 4.15 | 4.60 | 0.97 | 4.41 | 4.28 |
| Anthropic-LM (52B) Five-shot | 0.94 | 3.88 | 4.33 | 0.70 | 4.77 | 4.14 |
| Cohere XL (52.4B) | 0.99 | 3.42 | 4.48 | 0.63 | 4.79 | 4.00 |
| GLM (130B) | 0.94 | 3.69 | 4.24 | 0.74 | 4.72 | 4.12 |
| OPT (175B) | 0.96 | 3.64 | 4.33 | 0.67 | 4.80 | 4.01 |
| GPT-3 (350M) – (repeat) | 0.86 | 3.73 | 3.85 | - | - | - |
| GPT-3 (6.7B) – (repeat) | 0.97 | 3.87 | 4.17 | 0.75 | 4.19 | 3.36 |
| GPT-3 (175B) – (repeat) | 0.99 | 3.95 | 4.34 | 0.69 | 4.69 | 4.03 |
| Ada Instruct v1 (350M*) – (repeat) | 0.84 | 3.84 | 4.07 | 0.63 | 3.54 | 3.07 |
| Curie Instruct v1 (6.7B*) – (repeat) | 0.96 | 4.30 | 4.43 | 0.85 | 4.28 | 3.80 |
| Davinci Instruct (175B*) – (repeat) | 0.98 | 4.13 | 4.49 | 0.77 | 4.83 | 4.33 |
| Brio (Fine-tuned) | 0.94 | 3.94 | 4.40 | 0.58 | 4.68 | 3.89 |
| Pegasus (Fine-tuned) | 0.97 | 3.93 | 4.38 | 0.57 | 4.73 | 3.85 |
| Existing references | 0.84 | 3.20 | 3.94 | 0.37 | 4.13 | 3.00 |
- 지시 미세 조정이 데이터 세트 전반에 걸쳐 제로샷 요약 성능의 핵심 추진 요인이며 모델 크기가 큰 역할을 하지 않는다.
- 가장 큰 모델들(예: 175B)이 일관성 및 관련성에서 더 작은 지시 미세 조정 모델에 의해 능가될 수 있다.
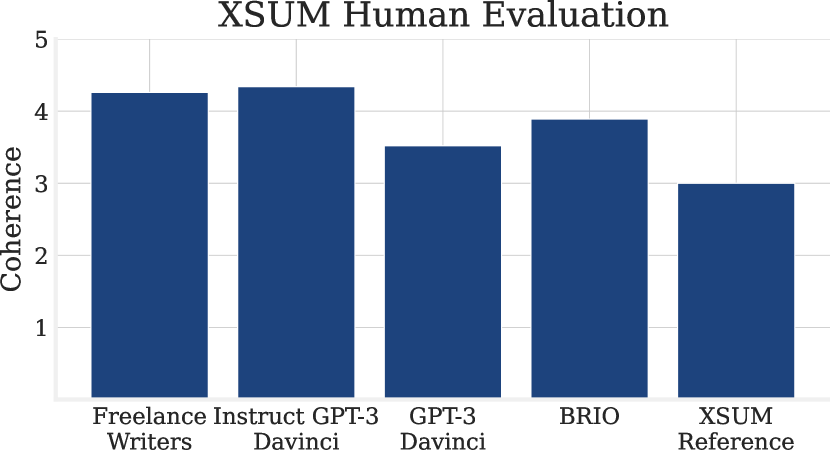
- XSUM의 참조 요약은 인간에 의해 LLM의 최상 outputs보다 더 나쁘다고 평가되며 참조 기반 지표의 신뢰성에 의문을 제기한다.
- 프리랜스 작가가 CNN/DM 및 XSUM 기준선보다 더 높은 품질의 참조를 제공하며, Instruct Davinci가 종종 프리랜스 작가에 비견된다.
- 더 나은 품질의 참조가 있을 때 XSUM에서 인간의 성실도와 Rouge-L의 상관관계가 개선된다.
- LLM 요약과 프리랜스 요약 간의 선호도에 상당한 주관적 편차가 있어 스타일 차이가 큼을 시사한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.