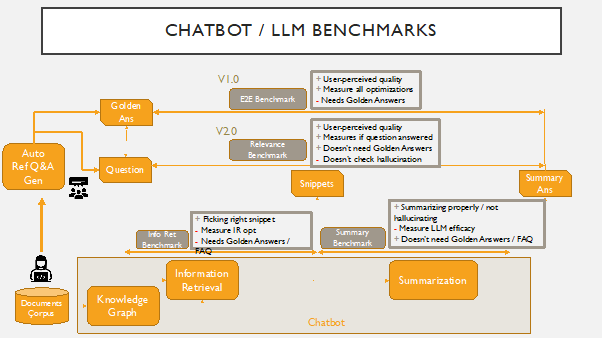
[논문 리뷰] Benchmarking LLM powered Chatbots: Methods and Metrics
논문은 End-to-End (E2E) 챗봇 벤치마크를 도입하며 텍스트 임베딩(USE와 ST)을 통한 챗봇 답변과 골든 인간 답변 간의 의미적 유사성으로 정확도와 유용성을 평가하고 이를 ROUGE 메트릭과 비교합니다.
Autonomous conversational agents, i.e. chatbots, are becoming an increasingly common mechanism for enterprises to provide support to customers and partners. In order to rate chatbots, especially ones powered by Generative AI tools like Large Language Models (LLMs) we need to be able to accurately assess their performance. This is where chatbot benchmarking becomes important. In this paper, we propose the use of a novel benchmark that we call the E2E (End to End) benchmark, and show how the E2E benchmark can be used to evaluate accuracy and usefulness of the answers provided by chatbots, especially ones powered by LLMs. We evaluate an example chatbot at different levels of sophistication based on both our E2E benchmark, as well as other available metrics commonly used in the state of art, and observe that the proposed benchmark show better results compared to others. In addition, while some metrics proved to be unpredictable, the metric associated with the E2E benchmark, which uses cosine similarity performed well in evaluating chatbots. The performance of our best models shows that there are several benefits of using the cosine similarity score as a metric in the E2E benchmark.
연구 동기 및 목표
- 대형 언어 모델(LLM)로 구동되는 엔터프라이즈 챗봇의 견고한 평가를 촉진한다.
- 챗봇 답변과 전문가 골든 답변 간의 의미적 유사성을 측정하는 End-to-End(E2E) 벤치마크를 제안한다.
- ROUGE와 같은 전통적인 지표와 E2E를 비교하고 임베딩 기반 유사성의 이점을 입증한다.
- 프롬프트 엔지니어링이 E2E 성능에 미치는 영향을 탐색하고 ROUGE 결과와의 비교를 제시한다.
제안 방법
- 골든 답변과 챗봇 답변의 임베딩 벡터 간 코사인 유사성으로 E2E 벤치마크를 정의한다.
- 문장 임베딩을 얻기 위해 Universal Sentence Encoder (USE)와 Sentence Transformer (ST) 두 개의 임베딩 라이브러리를 사용한다.
- 골든 답변과 챗봇 답변 간의 코사인 유사도 S(G,A) = (X_G · X_A) / (|X_G||X_A|) 를 계산한다.
- 동일한 답변 쌍에서 E2E 결과를 ROUGE 점수(ROUGE-1, ROUGE-2, ROUGE-LCS)와 비교한다.
- 제품 지원 챗봇에서 평가하고 임베딩 기반 점수와 ROUGE 점수 간의 상관관계를 분석한다.
- E2E 및 ROUGE 지표에 대한 프롬프트 엔지니어링(표준 프롬프트 vs 향상된 프롬프트)의 효과를 검토한다.
실험 결과
연구 질문
- RQ1코사인 유사성을 이용한 문장 임베딩 기반의 E2E 벤치마크가 LLM 기반 챗봇의 ROUGE 기반 평가에 비해 어떤 성능을 보이는가?
- RQ2임베딩 기반 E2E 점수가 ROUGE 점수보다 프롬프트 엔지니어링의 개선을 더 잘 반영하는가?
- RQ3USE와 ST 임베딩 간의 관계가 챗봇 성능 측정에 어떤 영향을 미치는가?
- RQ4E2E가 평가에서 의미 있는 개선과 무작위 단어 같은 노이즈를 구분할 수 있는가?
- RQ5다양한 임베딩 모델에 대해 E2E 벤치마크가 얼마나 민감한가?
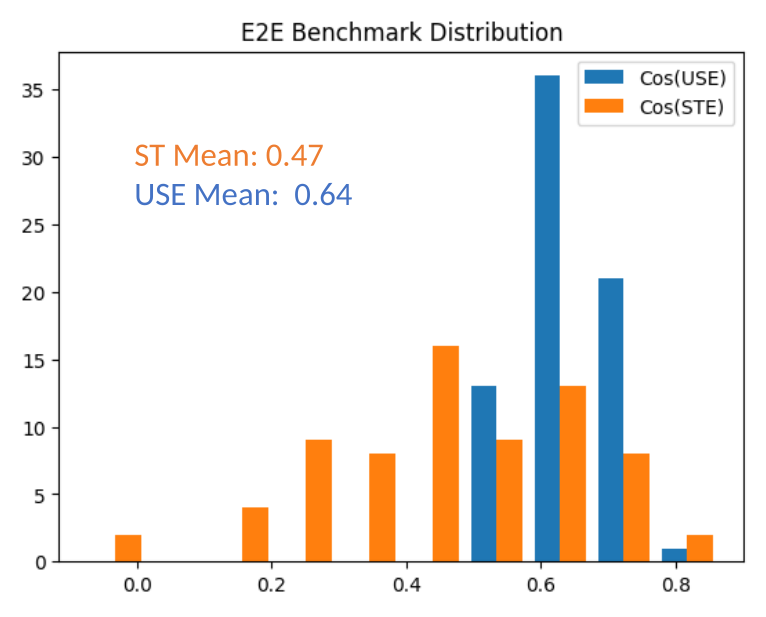
주요 결과
- USE 기반 E2E의 평균 코사인 유사도는 약 0.64이고; 평가된 챗봇에 대해 ST 기반 E2E는 약 0.47이다.
- USE 기반과 ST 기반 E2E 결과 사이에 강한 상관관계(R^2 ≈ 0.7)가 있다.
- ROUGE 지표는 임베딩 기반 E2E 결과와의 상관관계가 제한적이며 프롬프트 엔지니어링의 개선을 일관되게 반영하지 못했다.
- ST 임베딩을 이용한 E2E 벤치마크는 엔지니어링된 프롬프트를 적용할 때 더 날카로운 개선을 보였고, 프롬프트 설계에 더 높은 민감성을 시사한다.
- 임의의 단어를 대상으로 테스트하면 E2E 점수가 거의 무작위에 가까워지며 이때 ST가 USE보다 성능이 더 우수하다.
- 향상된 프롬프트를 사용하는 프롬프트 엔지니어링은 ST 기반 E2E 결과를 USE 기반 결과보다 현저히 개선한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.