[논문 리뷰] Better & Faster Large Language Models via Multi-token Prediction
본 연구는 언어 모델이 동시에 다수의 미래 토큰을 예측하도록 학습시켜 샘플 효율성을 향상시키고 self-speculative decoding으로 더 빠른 추론을 가능하게 하며, 코드 작업에서 주목할 만한 이점과 최대 13B 파라미터까지의 확장 이점을 보인다.
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
연구 동기 및 목표
- 다음 토큰 예측을 넘어서 LLM에 대해 더 샘플 효율적인 학습 목표로 다중 토큰 예측을 고무한다.
- 공유 트렁크와 다중 헤드를 갖는 메모리 효율적인 다중 토큰 예측 아키텍처를 제안한다.
- 다중 토큰 예측을 사용할 때 특히 코드 작업에서 확장 이점과 더 빠른 추론을 입증한다.
- 미세 조정 후 자연어 생성 및 다운스트림 작업에서 다중 토큰 예측이 성능을 보존하거나 향상시키는 것을 보인다.
제안 방법
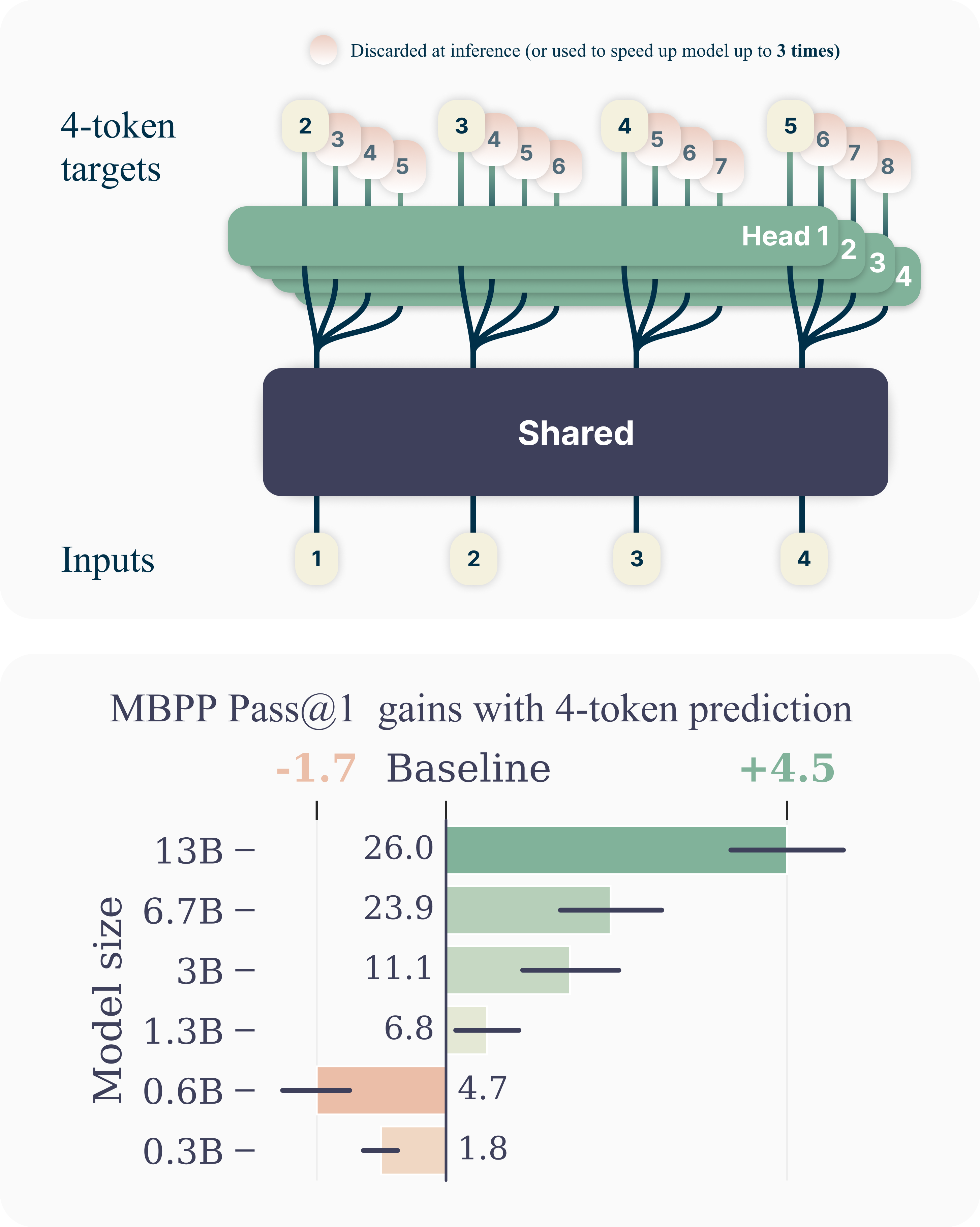
- 모델이 공유 트렁크에서 n 독립 헤드를 사용하여 각 위치에서 n 개의 미래 토큰을 예측하는 다중 토큰 예측 목표를 도입한다.
- 공유 표현과 헤드별 예측으로 분해되는 L_n이라는 계산 가능한 교차 엔트로피 손실을 도출한다.
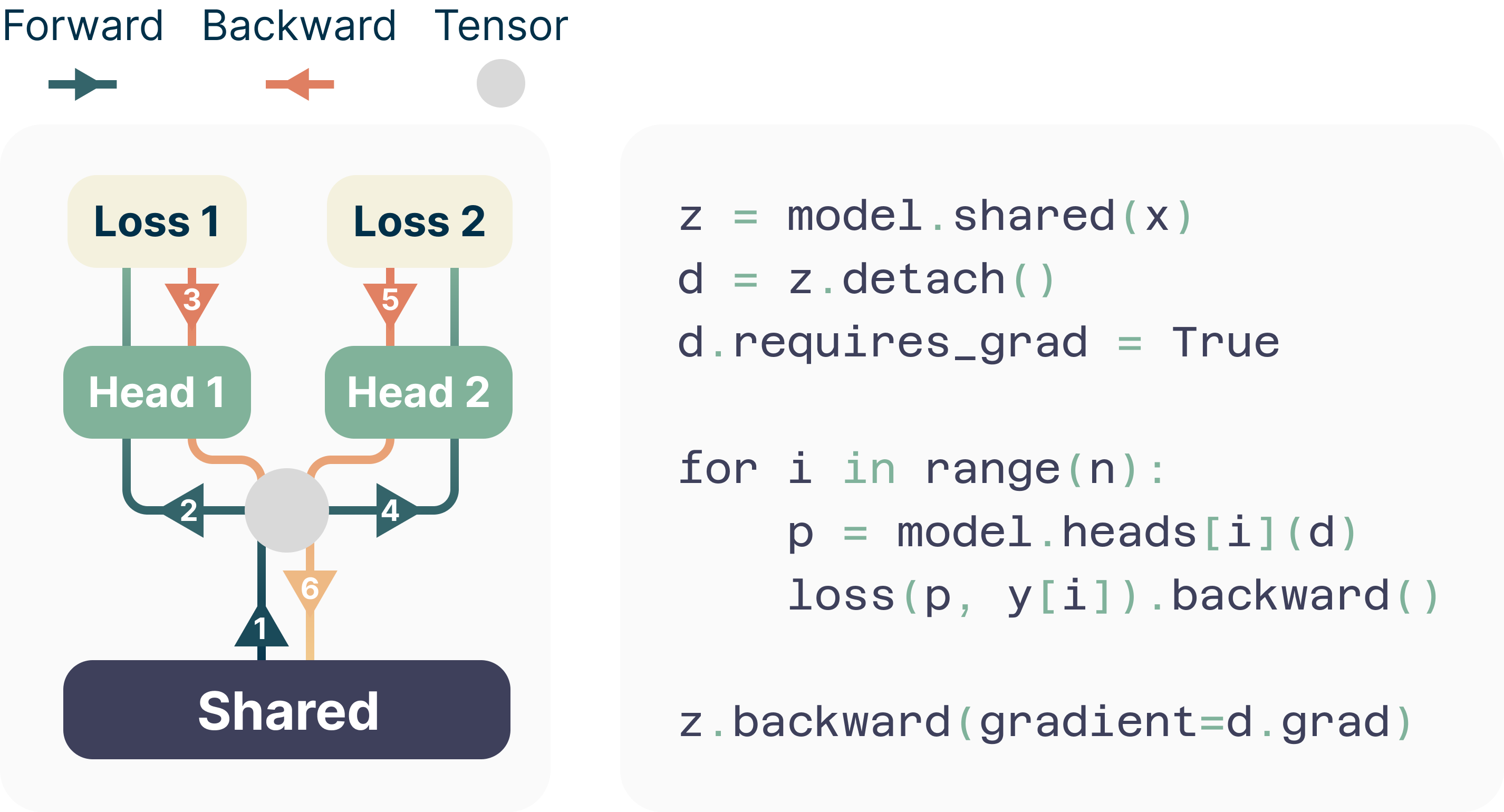
- 피크 메모리를 O(nV+d)에서 O(V+d)로 줄이는 메모리 효율적인 순전파/역전파 스킴을 설명한다.
- 추가 드래프트 모델 없이 추가 헤드를 활용하여 self-speculative decoding으로 추론 속도를 높인다.
- 바이트 수준 토큰화 포함, varying 모델 크기(최대 13B 파라미터) 및 데이터 규모에서 코드 및 자연어 벤치마크를 평가한다.
실험 결과
연구 질문
- RQ1학습 시 다중 미래 토큰을 예측하는 것이 표준 다음 토큰 예측과 비교하여 다운스트림 성능을 향상시키는가?
- RQ2코드와 자연어 작업에서 모델 크기 및 학습 데이터에 따라 다중 토큰 예측의 확장성은 어떠한가?
- RQ3추가 계산 비용 없이 speculative decoding을 통해 다중 토큰 학습이 더 빠른 추론을 가능하게 하는가?
- RQ4다른 예측 창 크기(n)가 작업 및 데이터 설정 전반에 걸친 성능에 미치는 영향은 무엇인가?
주요 결과
- 다중 토큰 예측은 샘플 효율성을 높이며, 13B 파라미터 모델은 HumanEval에서 다음 토큰 baselines보다 약 12% 더 많은 문제를 해결하고 MBPP에서 17% 더 많다.
- 4-token 예측으로 학습하면 상당한 이점을 얻고 self-speculative decoding을 통해 최대 3배 빠른 추론이 가능하며, 특히 코드 벤치마크에서 그렇다.
- 이점은 모델 크기에 따라 확장되고 여러 에포크에서도 지속되며, 코드 작업 및 바이트 수준 모델링에서 뚜렷한 개선이 있다.
- 2-token 예측은 표준 NLP 벤치마크에서 종종 다음 토큰 baselines와 일치하고, 4-token 예측은 일부 언어 작업에서 성능 저하를 유발할 수 있어 작업 및 데이터 의존적 효과를 시사한다.
- CodeContests에서 사전 학습된 다중 토큰 모델을 미세 조정하면 설정에 따라 pass@k가 향상되며, 4-token 사전훈련 위에 next-token 미세 조정이 때때로 가장 강력한 전체 성능을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.