[논문 리뷰] BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
BioMedLM은 PubMed 초록 및 기사에만 학습된 27억 파라미터의 GPT-스타일 모델로, 파인튜닝 후 생물의학 QA 성능이 경쟁력 있으며 온디바이스 추론과 오픈 데이터 기원성을 가능하게 한다.
Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
연구 동기 및 목표
- 대형 모델의 프라이버시, 비용 및 투명성 문제를 해결하기 위해 의생물 분야에 특화된 더 작고 도메인 전문적인 LLM 개발을 촉진한다.
제안 방법
- 2.7B 파라미터를 가진 자동회귀 디코더-전용 Transformer(GPT-2 스타일).
- 생물의학 용어 토큰화를 개선하기 위해 PubMed 초록을 바탕으로 학습된 도메인 특화 바이트 페어 인코딩 토크나이저.
- PubMed 초록과 기사에 대한 사전 학습(34.6B 토큰; 8.67 패스; 약 300B 토큰 탐색)을 혼합 정밀도, 최종 학습은 bf16, 그리고 Decoupled AdamW 옵티마이저를 사용.
- 다지선다형 프롬프트에 특화된 아키텍처를 가진 다운스트림 생물의학 QA 태스크를 위한 파인튜닝(작업별 프롯프트 구성과 답변 점수에 대한 최종 선형 분류기).
- 웹에서 파생된 QA 쌍을 사용한 소비자 건강 질문에 대한 생성 스타일의 파인튜닝(장문 응답).

실험 결과
연구 질문
- RQ1Compact하고 도메인 특화된 모델(2.7B 파라미터)이 생물의학 QA 태스크에서 더 큰 모델의 성능에 근접하거나 도달할 수 있는가?
- RQ2PubMed 데이터만으로 학습하고 생물의학 토크나이저를 사용하는 것이 일반 도메인 기준과 비교해 다운스트림 태스크 성능을 향상시키는가?
- RQ3작고 오픈된 생물의학 LLM을 배포할 때의 프라이버시, 비용 및 접근성의 트레이드오프는 비공개 대형 모델과 비교해 어떠한가?
주요 결과
| 데이터셋 | 모델 | 파라미터 | 방법 | 정확도 |
|---|---|---|---|---|
| MedMCQA | GPT-4 | – | few-shot | 72.4 |
| MedMCQA | Flan-PaLM | 540B | few-shot | 57.6 |
| MedMCQA | BioMedLM | 2.7B | fine-tune | 57.3 |
| MedMCQA | Galactica | 120B | zero-shot | 52.9 |
| MedMCQA | GPT-3.5 | 175B | few-shot | 51.0 |
| MedQA | Med-PaLM 2 | – | closed, few-shot | 85.4 |
| MedQA | GPT-4 | – | closed, few-shot | 81.4 |
| MedQA | Flan-PaLM | 540B | closed, few-shot | 67.2 |
| MedQA | BioMedLM (MedMCQA data + classifier) | 2.7B | fully open, fine-tune | 54.7 |
| MedQA | GPT-3.5 | 175B | closed, few-shot | 53.6 |
| MedQA | BioMedLM (classifier) | 2.7B | fully open, fine-tune | 50.3 |
| MedQA | DRAGON | 360M | fully open, fine-tune | 47.5 |
| MedQA | BioLinkBERT | 340M | fully open, fine-tune | 45.1 |
| MedQA | Galactica | 120B | open weights, zero-shot | 44.4 |
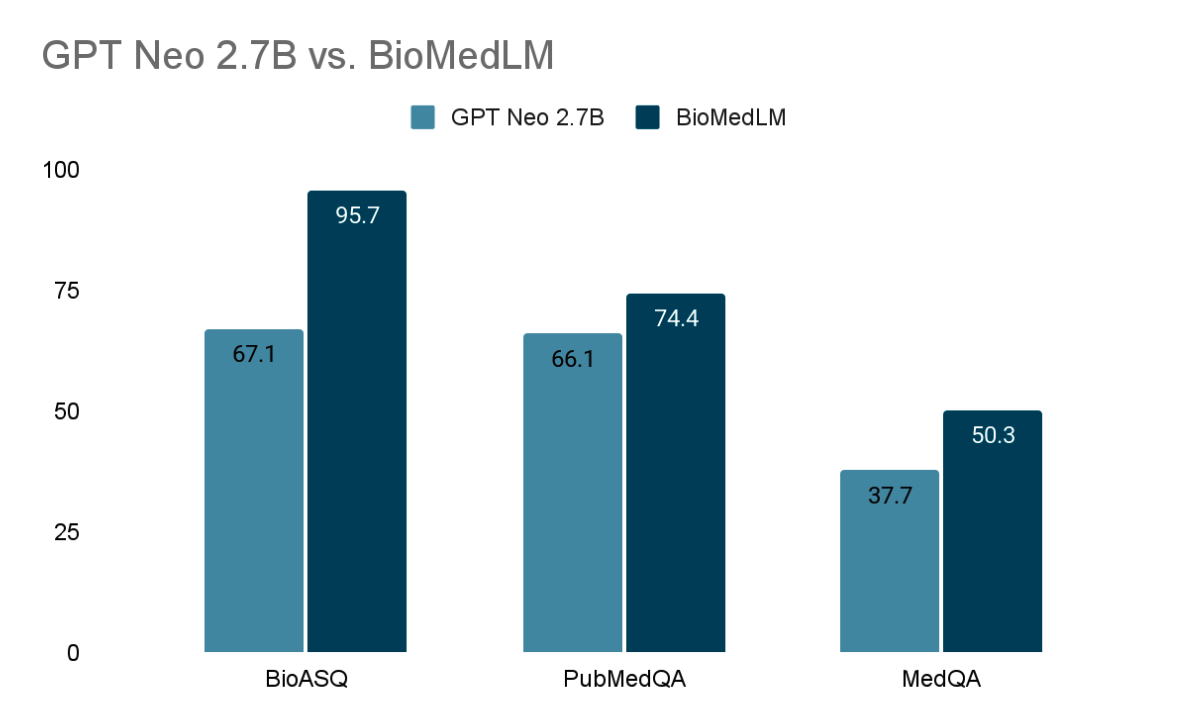
| MedQA | GPT-Neo 2.7B | 2.7B | fully open, fine-tune | 37.7 |
| BioASQ | BioMedLM | 2.7B | fine-tune | 95.7 |
| BioASQ | DRAGON | 360M | fine-tune | 96.4 |
| BioASQ | BioLinkBERT | 340M | fine-tune | 94.9 |
| BioASQ | Galactica | 120B | zero-shot | 94.3 |
| BioASQ | GPT-Neo 2.7B | 2.7B | fine-tune | 67.1 |
| PubMedQA | BioMedLM | 2.7B | fine-tune | 74.4 |
- BioMedLM은 파인튜닝 후 여러 생물의학 QA 벤치마크에서 경쟁력 있는 결과를 달성하며, 다수의 태스크에서 더 큰 모델에 근접하거나 이를 능가한다(예: MedMCQA 57.3%, MMLU Medical Genetics 69.0%).
- PubMed에 대한 도메인 특화 사전학습과 특수 토크나이저가 GPT-2/토크나이저 기준에 비해 눈에 띄는 이점을 제공한다(예: MedQA에서 125M 규모에서 33.05에서 34.98로 개선).
- 일반 영어 데이터로 학습된 GPT-Neo 2.7B에 비해 BioMedLM은 특정 QA 태스크에서 상당히 우수한 성능을 보인다(예: BioASQ에서 27 포인트의 개선).
- BioMedLM은 온디바이딩 추론을 지원하며, 교육 데이터와 아키텍처에 대한 투명성을 제공하면서 보통의 하드웨어로도 파인튜닝 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.