[논문 리뷰] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
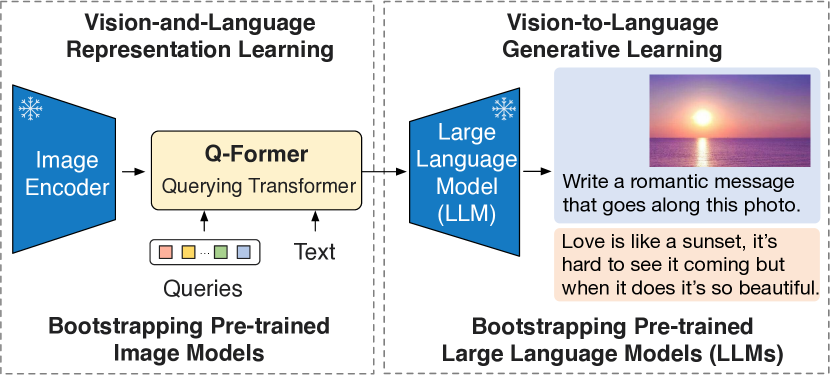
BLIP-2는 고정된 사전 학습 이미지 인코더와 고정된 대형 언어 모델을 기반으로 경량의 Querying Transformer를 사용해 제로샷 및 지시형 이미지-텍스트 생성에서 강력한 성능을 달성하며 학습 가능한 매개변수는 훨씬 적다.
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
연구 동기 및 목표
- 단일 모달 모델을 동결하고 경량 Q-Former로 모달리티를 연결하여 비전-언어 사전학습 비용을 줄인다.
- 동결된 이미지 인코더로 표현 학습과 동결된 LLM으로 생성 학습의 2단계 사전학습을 통해 교차 모달 정렬을 학습한다.
- 개선된 효율성과 함께 제로샷 지시형 이미지-텍스트 생성 및 더 넓은 VLP 기능을 입증한다.
- BLIP-2가 비전 및 언어 모델의 발전을 활용해 학습 가능한 매개변수를 적게 사용하고도 강력한 성능을 달성할 수 있음을 보인다.
제안 방법
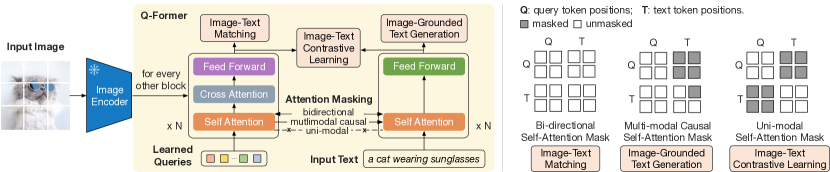
- 동결된 이미지 인코더와 동결된 LLM을 연결하는 학습 가능한 질의를 갖는 소형 트랜스포머인 Q-Former를 제안한다.
- 1단계: 동결된 이미지 인코더와 모달리티 마스크된 어텐션을 사용하여 ITC, ITG, ITM 목표로 비전-언어 표현 학습.
- 2단계: Q-Former 출력을 LLM으로 투사하고 언어 생성 손실(디코더 기반 LLM) 또는 접두사 언어 모델링(인코더-디코더 LLM)을 사용하여 비전에서 언어로의 생성 학습.
- LLM을 고정한 채 Q-Former와 이미지 인코더를 업데이트하면서 Downstream 태스크(VQA, 캡션 생성, 검색 등)에 대해 BLIP-2를 미세조정한다.
- CapFilt+정제 및 배치 내 음수를 사용해 다양한 소스로부터 129M 이미지-텍스트 쌍을 학습에 활용한다.
실험 결과
연구 질문
- RQ1고정된 이미지 인코더와 고정된 대형 언어 모델로 구성된 비전-언어 사전학습 프레임워크가 하나의 경량 다리 모듈에서 최첨단 성능을 달성할 수 있는가?
- RQ2대형 백본을 업데이트하지 않고 최소한의 질의 메커니즘(Q-Former)이 효과적인 교차 모달 정렬을 가능하게 할 수 있는가?
- RQ3고정된 단일 모달 모델을 사용할 때 제로샷 지시형 이미지-텍스트 생성의 emergent 능력은 무엇인가?
- RQ4BLIP-2의 효율성은 학습 가능한 매개변수와 계산 측면에서 엔드 투 엔드 대형 비전-언어 사전학습 방법과 어떻게 비교되는가?
주요 결과
- BLIP-2는 엔드 투 엔드 방법에 비해 훨씬 적은 학습 가능한 매개변수(188M)로 강력한 제로샷 비전-언어 성능을 달성하고 제로샷 VQAv2에서 Flamingo80B를 8.7%포인트 앞선다.
- 두 단계 사전학습(표현 학습과 비전-언어 생성)이 동결된 이미지 인코더와 동결된 LLM 간의 효과적인 연계를 가능하게 한다.
- BLIP-2는 지시된 제로샷 이미지-텍스트 생성을 지원하여 시각적 지식 추론 및 시각적 대화와 같은 태스크를 가능하게 한다.
- 예: 단일 16-에이당(A100, 40GB) 머신으로 대형 변형의 사전학습 단계를 며칠 안에 완료하는 등 계산 효율성을 보여준다.
- BLIP-2의 결과는 더 큰 비전 인코더와 더 큰 LLM이 VQA, 캡션 생성 및 검색 태스크 전반에서 성능을 지속적으로 개선함을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.