[논문 리뷰] BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
BLIP-Diffusion은 제로샷 및 소수-shot 주제 구동 텍스트-투-이미지 생성을 가능하게 하는 사전 학습된 다중 모달 주제 표현을 도입하고, 효율적인 미세 조정과 ControlNet 및 prompt-to-prompt와의 편집 호환성을 제공합니다.
Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications. Code and models will be released at https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion. Project page at https://dxli94.github.io/BLIP-Diffusion-website/.
연구 동기 및 목표
- 효율적이고 확장 가능한 주제 구동 생성을 촉진하여 광범위한 미세 조정 없이도 주제 충실성을 보존합니다.
- 텍스트에 정렬된 주제를 안내하기 위한 일반적인 사전 학습 주제 표현을 개발합니다.
- 주제에 대해 제로샷 및 소수-shot 개인화를 가능하게 하여 미세 조정 단계를 크게 줄입니다.
제안 방법
- 두 단계의 사전 학습: (1) BLIP-2 스타일 인코더를 사용하여 이미지 특징을 텍스트와 정렬하는 다중 모달 표현 학습; (2) 확산 모델이 시각적 특징에서 주제 재현을 생성하는 방법으로 주제 표현 학습.
- BLIP-2 다중 모달 인코더를 사용하여 주제 이미지와 카테고리 텍스트로부터 텍스트에 정렬된 주제 표현을 생성합니다.
- BLIP-2 출력물을 투영하고 텍스트 프롬프트와 연결하여 확산 모델에 부드러운 시각적 주제 프롬프트를 주입합니다(예: 템플릿 “[text prompt], the [subject text] is [subject prompt]”).
- 미세 조정 중 확산 모델의 텍스트 인코더를 고정하여 과적합을 방지하고, 주제 특정 생성에 대해 적은 수의 스텝(40-120)으로 미세 조정합니다.
- 구조 제어를 위한 ControlNet 및 프롬프트-투-프롬프트 스타일 편집으로 교차 주의 맵을 조작하는 모듈식 확장을 가능하게 합니다.]
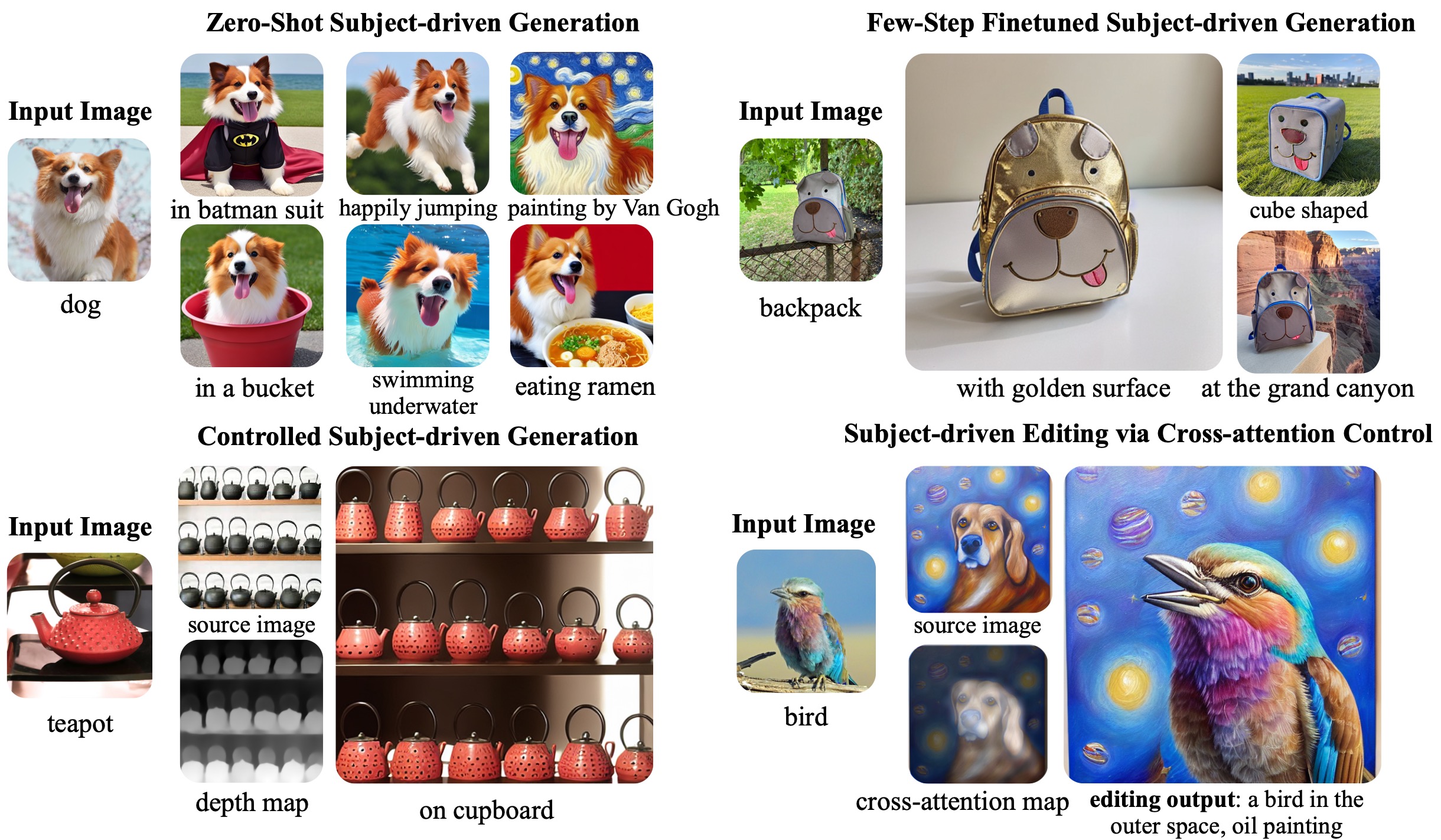
실험 결과
연구 질문
- RQ1사전 학습된 다중 모달 주제 표현이 고충실도 제로샷 주제 구동 생성을 가능하게 하나요?
- RQ2새로운 주제에 대한 특수화를 위해 필요한 미세 조정 스텝 수는 기존 방법과 비교하여 얼마나 되나요?
- RQ3주제 표현을 기존 편집/구조 제어 기술(ControlNet, prompt-to-prompt)과 재학습 없이 효과적으로 결합할 수 있나요?
- RQ4모델은 다중 모달 제어를 제공하면서도 기본 확산 모델의 핵심 기능을 보존하나요?
- RQ5두 단계 사전 학습이 주제 비주얼과 텍스트 프롬프트 간 정렬에 어떤 영향을 미치나요?
주요 결과
| 방법 | DINO | CLIP-I | CLIP-T |
|---|---|---|---|
| Real Images (Oracle) | 0.774 | 0.885 | - |
| Textual Inversion | 0.569 | 0.780 | 0.255 |
| Re-Imagen | 0.600 | 0.740 | 0.270 |
| DreamBooth | 0.668 | 0.803 | 0.305 |
| – 100 fine-tuning steps | 0.396 | 0.698 | 0.322 |
| – 300 fine-tuning steps | 0.500 | 0.733 | 0.319 |
| Ours (ZS) | 0.594 (±0.004) | 0.779 (±0.003) | 0.300 (±0.002) |
| Ours (FT, avg. < 80 steps) | 0.670 (±0.004) | 0.805 (±0.002) | 0.302 (±0.001) |
- BLIP-Diffusion은 고충실도의 제로샷 주제 구동 생성을 달성합니다.
- 미세 조정은 40-120 스텝이 필요하며 DreamBooth와 같은 기존 방법에 비해 최대 20x 더 빠릅니다.
- ControlNet 또는 prompt-to-prompt와 결합될 때 모델은 주제 시각 자료를 활용한 구조 제어 생성 및 편집을 지원합니다.
- 정량적 지표는 Textual Inversion 및 Re-Imagen에 비해 경쟁력 있거나 더 우수한 성능을 보여주며, 더 적은 미세 조정으로 DreamBooth에 버금가는 결과를 제공합니다.
- 멀티모달 사전 학습과 고정 선택의 중요성을 보여주는 제거 실험은 텍스트 제어를 유지하면서 주제 표현을 활용하는 데 도움을 줍니다.
- 주제 표현은 로컬 및 전체 주제 특징을 모두 포착하여 다양한 편집 및 스타일 전이 기능을 가능하게 합니다.
![Figure 2: Illustration of the two-staged pre-training for BLIP-Diffusion. Left : in the multimodal representation learning stage, we follow prior work [ 12 ] and pretrain BLIP-2 encoder to obtain text-aligned image representation. Right : in the subject representation learning stage, we synthesize i](https://ar5iv.labs.arxiv.org/html/2305.14720/assets/x1.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.