[논문 리뷰] BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
BOLAA는 다양한 LAA 아키텍처를 다양한 LLM 백본으로 벤치마크하고 전문 LAAs를 조정하는 다중 에이전트 컨트롤러를 도입하여 의사결정 및 지식 추론 작업에서 평가한다.
The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs). An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions. Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones. Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, extit{i.e.} BOLAA, where a controller manages the communication among multiple agents. We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs. Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both. We release our implementation code of LAAs to the public at \url{https://github.com/salesforce/BOLAA}.
연구 동기 및 목표
- 다양한 LLM 백본 범위에서 LAA 아키텍처의 성능을 평가한다.
- 아키텍처와 LLM의 조합 중 어떤 조합이 작업 성능이 가장 우수한지 식별한다.
- 컨트롤러를 통해 다수의 특화된 LAA를 조정하는 이점을 조사한다.
- 확장 가능한 LAA 시스템을 위한 아키텍처 설계 선택에 대한 가이드를 제공한다.
- 재현성을 촉진하기 위한 오픈 소스 구현을 공개한다.
제안 방법
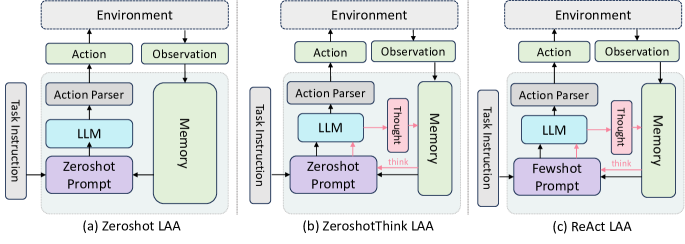
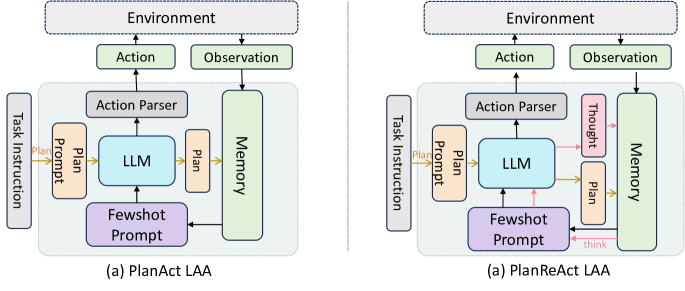
- 프롬프트, 자가사고(self-thinking), 계획(plan) 변형을 포괄하는 6개의 단독 LAA 아키텍처를 구성한다.
- 복수의 백본 LLM과 아키텍처를 쌍으로 매칭하여 광범위한 평가 매트릭스를 만든다.
- 특화된 노동 LAAs로 행동을 라우팅하는 컨트롤러 기반 아키텍처인 BOLAA를 제안한다(예: 검색/클릭 에이전트 분리).
- WebShop(웹 네비게이션) 및 HotPotQA(다중 호핑 지식 추론) 환경에서 평가한다.
- 효능과 의사소통 품질을 평가하기 위해 최종 보상과 중간 리콜을 보고한다.
실험 결과
연구 질문
- RQ1다양한 LAA 아키텍처가 웹 네비게이션 및 추론 작업에서 서로 다른 LLM 백본으로 어떻게 성능을 발휘하는가?
- RQ2컨트롤러(BOLAA)를 통해 다수의 특화된 LAA를 조정하는 것이 단일 에이전트에 비해 성능을 향상시키는가?
- RQ3맥락 길이와 모델 크기가 아키텍처 전반의 LAA 효과에 어떤 영향을 미치는가?
- RQ4어떤 LLM 백본과 아키텍처가 오픈 도메인 작업 및 계획 시나리오에 가장 잘 일반화되는가?
주요 결과
| LLM | Len. | LAA Architecture | ZS | ZST | ReAct | PlanAct | PlanReAct | BOLAA |
|---|---|---|---|---|---|---|---|---|
| fastchat-t5-3b | 2k | 0.3971 | 0.2832 | 0.3098 | 0.3837 | 0.1507 | 0.5169 | |
| vicuna-7b | 2k | 0.0012 | 0.0002 | 0.1033 | 0.0555 | 0.0674 | 0.0604 | |
| vicuna-13b | 2k | 0.0340 | 0.0451 | 0.1509 | 0.3120 | 0.4127 | 0.5350 | |
| vicuna-33b | 2k | 0.1356 | 0.2049 | 0.1887 | 0.3692 | 0.3125 | 0.5612 | |
| llama-2-7b | 4k | 0.0042 | 0.0068 | 0.1248 | 0.3156 | 0.2761 | 0.4648 | |
| llama-2-13b | 4k | 0.0662 | 0.0420 | 0.2568 | 0.4892 | 0.4091 | 0.3716 | |
| llama-2-70b | 4k | 0.0122 | 0.0080 | 0.4426 | 0.2979 | 0.3770 | 0.5040 | |
| mpt-7b-instruct | 8k | 0.0001 | 0.0001 | 0.0573 | 0.0656 | 0.1574 | 0.0632 | |
| mpt-30b-instruct | 8k | 0.1664 | 0.1255 | 0.3119 | 0.3060 | 0.3198 | 0.4381 | |
| xgen-8k-7b-instruct | 8k | 0.0001 | 0.0015 | 0.0685 | 0.1574 | 0.1004 | 0.3697 | |
| longchat-7b-16k | 16k | 0.0165 | 0.0171 | 0.0690 | 0.0917 | 0.1322 | 0.1964 | |
| longchat-13b-16k | 16k | 0.0007 | 0.0007 | 0.2373 | 0.3978 | 0.4019 | 0.3205 | |
| text-davinci-003 | 4k | 0.5292 | 0.5395 | 0.5474 | 0.4751 | 0.4912 | 0.6341 | |
| gpt-3.5-turbo | 4k | 0.5061 | 0.5057 | 0.5383 | 0.4667 | 0.5483 | 0.6567 | |
| gpt-3.5-turbo-16k | 16k | 0.5657 | 0.5642 | 0.4898 | 0.4565 | 0.5607 | 0.6541 |
- BOLAA는 테스트된 LLM들 전반에서 일반적으로 가장 높은 보상을 달성하며, 특화되고 조정된 에이전트의 이점을 시사한다.
- LLM과 아키텍처의 최적 매칭은 작업 및 모델에 따라 다르며(예: PlanAct, PlanReAct, 또는 BOLAA가 모델별로 서로 다른 성능을 보인다).
- 더 크고 더 능력 있는 LLM은 종종 더 작 은 모델보다 우수하지만, 매우 긴 컨텍스트는 환각을 더 많이 유발하고 항상 결과를 개선하지는 않는다.
- Plan 흐름은 오픈소스 LLM에 도움이 되는 반면, 선행 계획과의 불일치로 인해 일부 지식 추론 작업에서 계획이 해로울 수 있다.
- WebShop에서 특화된 노동 LAAs(검색 및 클릭)와 함께한 BOLAA는 일관되게 강한 성능과 리콜을 보인다; HotPotQA에서는 ReAct 기반 아키텍처가 소수-shot 프롬프트와 함께 뛰어나다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.