[논문 리뷰] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
저자들은 대규모 연구에서 LLM이 생성한 연구 아이디어와 인간 전문가 아이디어를 비교했다; AI 아이디어는 더 참신하게 평가되지만 실행 가능성은 비슷하며, 100명이 넘는 NLP 연구자들의 블라인드 리뷰를 기반으로 한다.
Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autonomously generate and validate new ideas. Despite this, no evaluations have shown that LLM systems can take the very first step of producing novel, expert-level ideas, let alone perform the entire research process. We address this by establishing an experimental design that evaluates research idea generation while controlling for confounders and performs the first head-to-head comparison between expert NLP researchers and an LLM ideation agent. By recruiting over 100 NLP researchers to write novel ideas and blind reviews of both LLM and human ideas, we obtain the first statistically significant conclusion on current LLM capabilities for research ideation: we find LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility. Studying our agent baselines closely, we identify open problems in building and evaluating research agents, including failures of LLM self-evaluation and their lack of diversity in generation. Finally, we acknowledge that human judgements of novelty can be difficult, even by experts, and propose an end-to-end study design which recruits researchers to execute these ideas into full projects, enabling us to study whether these novelty and feasibility judgements result in meaningful differences in research outcome.
연구 동기 및 목표
- 최신형 LLM이 대규모로 참신하고 전문가 수준의 연구 아이디어를 생성할 수 있는지 평가한다.
- 아이디어 도출, 작성 형식, 평가 과정의 교란 요인을 통제하여 인간 전문가와의 공정한 비교를 가능하게 한다.
- 향후 아이데이션 에이전트 연구를 위한 표준화된 평가 프로토콜과 벤치마크 데이터를 제공한다.
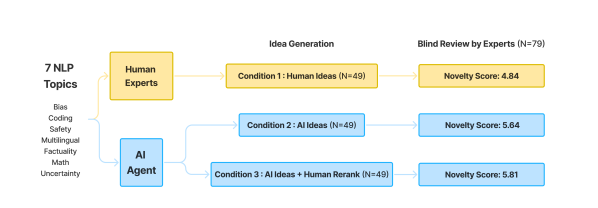
- 세 가지 조건을 비교한다: 인간이 작성한 아이디어, AI가 생성한 아이디어, 인간 전문가에 의해 재순위가 매겨진 AI 생성 아이디어.
- LLM 아이데이션 에이전트의 한계를 조사하고 실제 세계 결과를 연구하기 위한 엔드투엔드 후속 연구를 제안한다.
제안 방법
- 주제당 최대 120편의 인용된 논문으로 AI 아이디어를 뒷받침하기 위해 검색 보강 생성(RAG)을 사용하고, 논문의 관련성, 경험적 내용, 새로운 연구 아이디어를 자극할 가능성을 점수화한다.
- 주제당 4000개의 시드 아이디어를 생성하여 후보 품질을 극대화하고, 이후 중복 제거 및 최상-N 선택을 수행한다.
- 공개 학술대회 심사 데이터를 기반으로 한 스위스 제도식 페어와이즈 비교 기반 LLM 랭커를 사용하여 아이디어를 순위화하고, 사람의 재랭크 옵션(AI 아이디어 + 사람 재랭크)을 제공합니다.
- 고정된 템플릿과 스타일 정규화 모듈로 아이디어 작성물을 표준화하여 글쓰기 스타일에서 신호 단서를 제거한다.
- 아이디어 작성 및 블라인드 리뷰를 위한 전문가로 100명 이상 NLP 연구원을 모집하고, 조건 간 비교 가능성과 심사자와 저자 간의 기관적 분리를 보장한다.
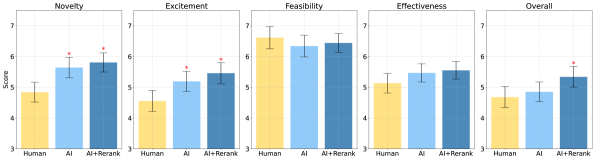
- 네 가지 지표(참신성, 흥미, 실행 가능성, 예상 효과)과 전체 점수를 포함하는 블라인드 리뷰 양식으로 아이디어를 평가하고, 근거를 제시하며 1–10 척도를 사용한다.
실험 결과
연구 질문
- RQ1현 시점의 LLM이 인간 전문가의 참신성과 비교하여 전문 수준의 참신한 연구 아이디어를 생성할 수 있는가, 혹은 이를 능가하는가?
- RQ2AI가 생성한 아이디어는 인간이 작성한 아이디어에 비해 인지된 참신성, 흥미, 실행 가능성 및 기대 효과에서 차이가 있는가?
- RQ3아이디어 품질의 LLM 기반 순위화의 신뢰성은 얼마나 되며, 자기평가 및 생성의 다양성에 어떤 한계가 있는가?
- RQ4AI가 생성한 아이디어의 품질과 참신성에 인간 재랭크가 어떤 영향을 미치는가?
- RQ5아이데이션 에이전트의 엔드투엔드 실행 연구에 대한 인간의 참신성 판단의 함의는 무엇인가?
주요 결과
- AI가 생성한 아이디어는 여러 테스트에서 인간 전문가 아이디어보다 더 참신하다고 평가된다(p<0.05).
- AI 생성 아이디어는 인간 아이디어와 비교해 실행 가능성이 약간 낮게 평가되지만, 전체 점수는 일관되게 더 나쁘지 않다.
- AI 아이디어에 인간 재랭크를 더하면 인간 아이디어보다 더 높은 참신성과 전체 점수를 보여주며, 인간의 개입이 포함된 순위의 가치가 있음을 시사한다.
- 리뷰어 분석은 참신성과 흥미가 실행 가능성보다 전체 점수를 좌우하는 경향이 있음을 보여주며, 참신성 판단의 주관성을 강조한다.
- 에이전트를 통한 LMM 기반 아이디어 순위 매김은 대규모에서 다양성 부족과 평가자로서의 자기 평가 불완전성 등 한계가 있음을 보여준다.
- 본 연구는 향후 엔드투엔드 아이디어 연구를 지원하기 위한 표준화된 프로토콜과 에이전트 구현 및 리뷰의 공개를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.