[논문 리뷰] Can multiple-choice questions really be useful in detecting the abilities of LLMs?
본 논문은 LLM 평가를 위한 MCQ의 효능을 분석하여 순서 민감성과 장문 생성과의 불일치를 드러내고, QA 형식 전반에서 일관성과 확신도를 측정하는 방법을 제시한다.
Multiple-choice questions (MCQs) are widely used in the evaluation of large language models (LLMs) due to their simplicity and efficiency. However, there are concerns about whether MCQs can truly measure LLM's capabilities, particularly in knowledge-intensive scenarios where long-form generation (LFG) answers are required. The misalignment between the task and the evaluation method demands a thoughtful analysis of MCQ's efficacy, which we undertake in this paper by evaluating nine LLMs on four question-answering (QA) datasets in two languages: Chinese and English. We identify a significant issue: LLMs exhibit an order sensitivity in bilingual MCQs, favoring answers located at specific positions, i.e., the first position. We further quantify the gap between MCQs and long-form generation questions (LFGQs) by comparing their direct outputs, token logits, and embeddings. Our results reveal a relatively low correlation between answers from MCQs and LFGQs for identical questions. Additionally, we propose two methods to quantify the consistency and confidence of LLMs' output, which can be generalized to other QA evaluation benchmarks. Notably, our analysis challenges the idea that the higher the consistency, the greater the accuracy. We also find MCQs to be less reliable than LFGQs in terms of expected calibration error. Finally, the misalignment between MCQs and LFGQs is not only reflected in the evaluation performance but also in the embedding space. Our code and models can be accessed at https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
연구 동기 및 목표
- MCQ가 중국어와 영어 및 데이터셋에서 LLM 능력을 정확하게 측정하는지 평가한다.
- MCQ의 선택지 순서가 LLM 출력에 어떤 편향을 주는지 검토한다.
- 직접 출력, 토큰 로짓, 임베딩 간에 MCQ와 장문 생성(LFGQ) 형식을 비교한다.
- 출력의 일관성과 모델 확신도를 정량화하는 방법을 제시한다.
- QA 벤치마크에서 MCQ와 LFGQ 중 어느 것을 사용할지에 대한 가이드를 제공한다.
제안 방법
- 네 가지 QA 데이터셋에서 아홉 개 LLM을 평가한다 (CARE-MI는 중국어, M3KE는 중국어, ARC는 영어, MATH는 영어).
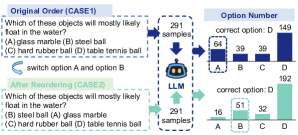
- MCQ 옵션을 재배열하고 분포 변화 탐지에 카이제곱 검정을 적용하여 순서 민감성을 테스트한다.
- 직접 출력, 토큰 로짓, 숨겨진 임베딩 공간에서 MCQ와 LFGQ 형식을 비교한다(일관된 확신 및 ECE와 같은 분석 포함).
- 형식 간 상관관계와 일관성과 정확도 간의 상관관계를 분석한다.
- 사전 프롬프트와 사후 프롬프트를 사용하여 간결한 응답을 이끌고 자동 확신도 계산을 가능하게 한다.
실험 결과
연구 질문
- RQ1MCQ 선택지의 배열이 이중 언어 데이터셋에서 LLM의 응답에 어떤 영향을 미치는가?
- RQ2직접 출력, 토큰 로짓, 임베딩 공간에서 MCQ와 LFGQ를 비교하는 데 적합한 방법론은 무엇인가?
- RQ3MCQ와 LFGQ 사이의 불일치 수준은 어느 정도이며, 형식 간 보정(calibration) 및 일관성에서 어떤 차이가 있는가?
주요 결과
- LLMs은 이중 언어 MCQ에서 순서 민감성을 보이며, 첫 번째 위치의 답을 선호한다.
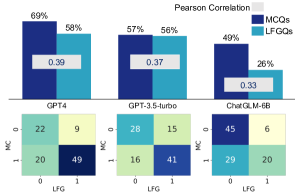
- 동일 질문에 대한 MCQ와 LFGQ의 답은 형식 간 상관관계가 낮게 나타난다.
- 더 높은 응답 일관성이 반드시 더 높은 정확도로 이어지지 않는다.
- MCQs yield poorer calibration (higher ECE) than LFGQs and TFQs, and embedding spaces show misalignment between formats in several layers.
- Embeddings from MCQs and LFGQs are separable in some layers but converge in later layers for some models.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.