[논문 리뷰] CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
CAS-ViT는 Convolutional Additive Token Mixer (CATM)를 도입해 표준 자기 주의(self-attention)을 대체하고, 모바일 및 엣지 디바이스에 적합한 선형 복잡도에서 경쟁력 있는 정확도를 달성합니다. 분류, 탐지, 세그먼테이션에서 GPU, ONNX, 및 iPhone 배포를 대상으로 평가합니다.
Vision Transformers (ViTs) mark a revolutionary advance in neural networks with their token mixer's powerful global context capability. However, the pairwise token affinity and complex matrix operations limit its deployment on resource-constrained scenarios and real-time applications, such as mobile devices, although considerable efforts have been made in previous works. In this paper, we introduce CAS-ViT: Convolutional Additive Self-attention Vision Transformers, to achieve a balance between efficiency and performance in mobile applications. Firstly, we argue that the capability of token mixers to obtain global contextual information hinges on multiple information interactions, such as spatial and channel domains. Subsequently, we propose Convolutional Additive Token Mixer (CATM) employing underlying spatial and channel attention as novel interaction forms. This module eliminates troublesome complex operations such as matrix multiplication and Softmax. We introduce Convolutional Additive Self-attention(CAS) block hybrid architecture and utilize CATM for each block. And further, we build a family of lightweight networks, which can be easily extended to various downstream tasks. Finally, we evaluate CAS-ViT across a variety of vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our M and T model achieves 83.0\%/84.1\% top-1 with only 12M/21M parameters on ImageNet-1K. Meanwhile, throughput evaluations on GPUs, ONNX, and iPhones also demonstrate superior results compared to other state-of-the-art backbones. Extensive experiments demonstrate that our approach achieves a better balance of performance, efficient inference and easy-to-deploy. Our code and model are available at: \url{https://github.com/Tianfang-Zhang/CAS-ViT}
연구 동기 및 목표
- 자원 제약이 있는 모바일 시나리오에서 ViT의 효율적인 토큰 믹서를 고무한다.
- 합성적 연산을 통한 선형 복잡도 어텐션을 가능하게 하는 Convolutional Additive Token Mixer (CATM)을 제안한다.
- 분류, 탐지, 인스턴스 세그먼트화 및 의미론적 세그먼테이션 작업에서 CAS-ViT의 경쟁력 있는 정확도와 배치(배포) 효율성을 시연한다.
- GPU, ONNX, 및 iPhone 배포에서 처리량을 평가하여 실용성을 보여준다.
제안 방법
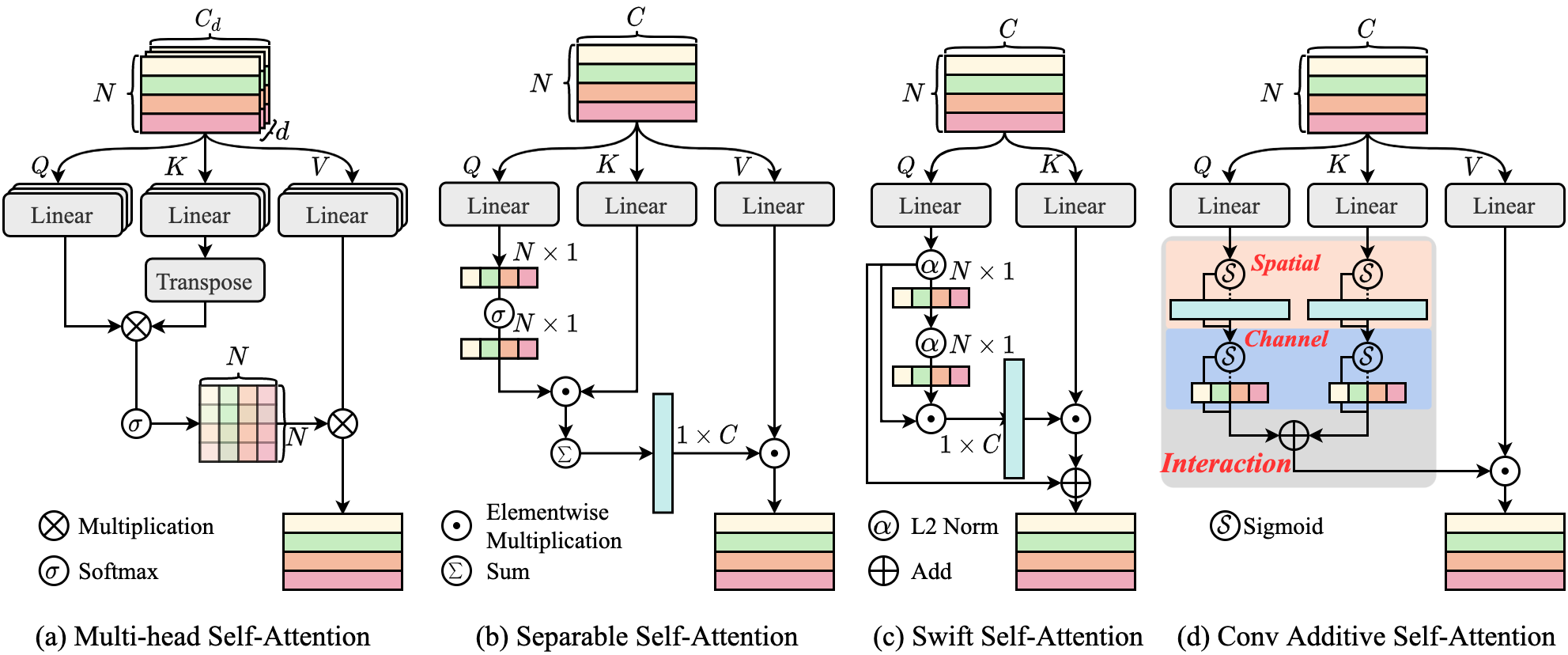
- 공간 및 채널 상호작용을 결합하는 Phi(Q) + Phi(K) 형태의 새로운 덧셈적 유사도 함수 Sim(Q,K)를 정의한다.
- Convolutional Additive Token Mixer (CATM)을 depthwise conv + Sigmoid 공간 주의 및 간소화된 채널 주의로 구현한다.
- CAS-ViT를 네 단계의 경량 ViT로 구성하고 계층 전체에 CATM 기반 블록을 배치하며, 통합 서브넷과 잔차가 있는 MLP를 더한다.
- Omega(CATM) ~ (47+10b)HWC인 입력 크기에 대해 전반적으로 선형 복잡도를 달성하기 위한 계산 복잡성을 분석한다.
- ImageNet-1K에서의 스크래치 학습으로 시작하고, 이후 다운스트림 작업과 CoreML 및 ONNX를 통한 모바일 배포를 수행한다.
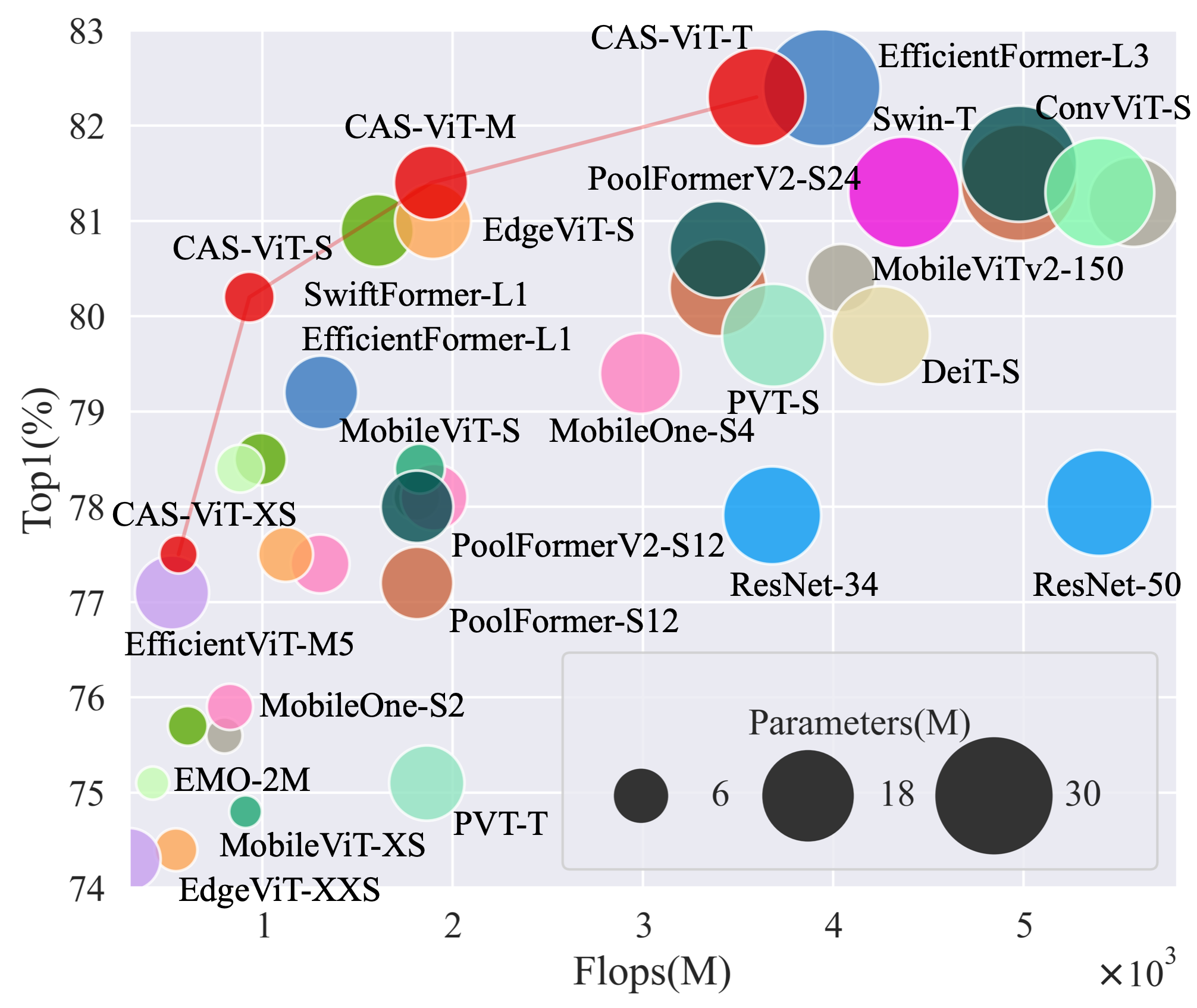
실험 결과
연구 질문
- RQ1모바일 배치를 위한 선형 시간 복잡도를 가진 convolution 기반 덧셈(attention) 메커니즘이 경쟁력 있는 ViT 성능을 달성할 수 있는가?
- RQ2덧셈적 유사도에서 공간 및 채널 상호작용을 통합하는 것이 비전 작업에서 정확도와 효율성에 어떤 영향을 미치는가?
- RQ3GPU, ONNX, iPhone 하드웨어에서 CAS-ViT의 처리량과 정확도 간의 트레이드오프는 어떠한가?
- RQ4CAS-ViT는 탐지, 인스턴스 세그먼테이션 및 의미론적 세그먼테이션에서 최신 백본과 비교하여 어떤 성능을 보이는가?
주요 결과
- CAS-ViT 변형은 ImageNet-1K에서 비교적 낮은 파라미터 수와 FLOPs로 경쟁력 있는 Top-1 정확도를 달성한다.
- CATM은 공간 및 채널 상호작용을 포함하면서도 선형 복잡도를 유지하고 Softmax 기반의 무거운 연산을 피한다.
- 객체 탐지/인스턴스 세그먼테이션에서 CAS-ViT 백본(예: CAS-ViT-S/M)은 유사하거나 더 낮은 FLOPs에서 더 나은 AP 지표를 보인다.
- ADE20K에서 CAS-ViT-M이 상대적으로 낮은 FLOPs로 43.6% mIoU를 달성한다.
- GPU, ONNX, 및 Apple Neural Engine에서의 처리량 분석은 실용적인 모바일 배포 가능성을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.