[논문 리뷰] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models
논문은 Chain-of-Symbol(CoS) 프롬프팅을 도입하여 공간 관계의 응축된 기호 표현을 사용해 LLM의 계획을 유도하고, 세 가지 공간 작업 및 공간 QA 벤치마크에서 Chain-of-Thought(CoT)보다 우수하며 입력 토큰을 줄인다.
In this paper, we take the initiative to investigate the performance of LLMs on complex planning tasks that require LLMs to understand a virtual spatial environment simulated via natural language and act correspondingly in text. We propose a benchmark named Natural Language Planning and Action (Natala) composed of a set of novel tasks: Brick World, NLVR-based Manipulations, and Natural Language Navigation. We found that current popular LLMs such as ChatGPT still lack abilities in complex planning. This arises a question -- do the LLMs have a good understanding of the environments described in natural language, or maybe other alternatives such as symbolic representations are neater and hence better to be understood by LLMs? To this end, we propose a novel method called CoS (Chain-of-Symbol Prompting) that represents the complex environments with condensed symbolic spatial representations during the chained intermediate thinking steps. CoS is easy to use and does not need additional training on LLMs. Extensive experiments indicate that CoS clearly surpasses the performance of the Chain-of-Thought (CoT) Prompting in all three planning tasks with even fewer tokens used in the inputs compared with CoT on ChatGPT and InstructGPT. The performance gain is strong, by up to 60.8% accuracy (from 31.8% to 92.6%) on Brick World for ChatGPT. CoS also reduces the number of tokens in the prompt obviously, by up to 65.8% of the tokens (from 407 to 139) for the intermediate steps from demonstrations on Brick World. Code and data available at: https://github.com/hanxuhu/chain-of-symbol-planning
연구 동기 및 목표
- 자연어로 설명된 복잡한 공간 이해 및 계획 작업에서 LLM 평가.
- 공간 작업에 대해 기호 표현이 자연어 중간 단계(CoT)보다 우수할 수 있는지 평가.
- 프롬프트 길이를 줄이는 학습 없이(CoS 프롬프팅) 방법을 제안하고 검증.
- 다양한 모델, 언어, 기호 선택에 걸친 CoS의 강건성 분석.
제안 방법
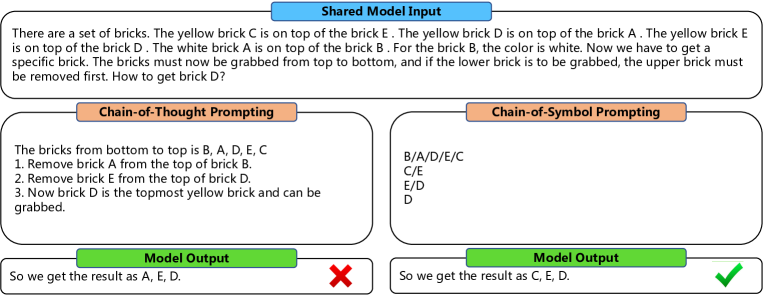
- 자연어 중간 단계 대신 공간 관계를 나타내는 응축된 기호를 사용하는 Chain-of-Symbol(CoS) 프롬프팅을 제안한다.
- 공식 CoT 시연을 자동으로 생성하고 오류를 수정한 뒤 공간 관계를 기호로 바꾸고 비핵심 텍스트를 제거하여 CoS로 변환한다.
- CoS 시연을 사용한 소수 예시 프롬프팅으로 세 가지 공간 계획 작업에서 LLM을 안내한다.
- (ChatGPT(gpt-3.5-turbo) 및 Text-Davinci-003)에서 제로샷 CoT, 소수샷 CoT, 소수샷 CoS 베이스라인의 호환성 및 성능을 평가한다.
- 계획 작업의 정확도, 정밀도, 재현율(일부 작업은 LCS 기반 유사도 포함)을 측정하고, 공간 QA의 경우 정확도를 평가한다.
실험 결과
연구 질문
- RQ1공간 관계의 기호 표현이 텍스트로 설명된 환경에서의 계획을 자연어 CoT와 비교해 개선될 수 있는가?
- RQ2CoS 프롬프트가 서로 다른 작업, 언어 및 모델 유형에 일반화될 수 있는가?
- RQ3CoS가 CoT에 비해 토큰 효율성 및 추론 비용에 어떤 영향을 미치는가?
- RQ4기호 선택 및 작업 난이도에 대해 CoS의 이점이 강건한가?
주요 결과
- CoS는 Brick World, NLVR 기반 Manipulation, Natural Language Navigation에서 일관되게 CoT를 능가한다.
- Brick World 1D Shuffle Label의 1D 시나리오에서 CoS가 92.6% 정확도를 달성해 베이스라인 CoT(31.8%에서 92.6%로)의 60.8포인트 향상을 기록했다.
- CoS는 중간 단계 토큰을 대폭 줄인다(예: Brick World 1D에서 407에서 139 토큰으로).
- CoS는 언어 간 강건성을 유지하며(중국어에서 CoT보다 향상된 성능) 및 서로 다른 기호에서도 잘 작동하며, 쉼표를 유효한 선택으로 활용하는 경우가 많다.
- SPARTUN에서 CoS는 GPT-3.5-Turbo 및 GPT-4에 대해 CoT보다 더 높은 정확도와 더 적은 중간 토큰을 기록한다.
- CoS는 여러 실험에서 CoT에 비해 출력 변동성(표준 편차)이 더 작다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.