[논문 리뷰] ChatSpamDetector: Leveraging Large Language Models for Effective Phishing Email Detection
ChatSpamDetector는 대형 언어 모델을 사용해 이메일을 LLM 친화적 프롬프트로 변환하여 피싱 이메일을 탐지하고, 결정에 대한 자세한 합리화를 제공하며, 다양한 피싱 데이터셋에서 GPT-4로 99.70%의 정확도를 달성한다.
The proliferation of phishing sites and emails poses significant challenges to existing cybersecurity efforts. Despite advances in malicious email filters and email security protocols, problems with oversight and false positives persist. Users often struggle to understand why emails are flagged as potentially fraudulent, risking the possibility of missing important communications or mistakenly trusting deceptive phishing emails. This study introduces ChatSpamDetector, a system that uses large language models (LLMs) to detect phishing emails. By converting email data into a prompt suitable for LLM analysis, the system provides a highly accurate determination of whether an email is phishing or not. Importantly, it offers detailed reasoning for its phishing determinations, assisting users in making informed decisions about how to handle suspicious emails. We conducted an evaluation using a comprehensive phishing email dataset and compared our system to several LLMs and baseline systems. We confirmed that our system using GPT-4 has superior detection capabilities with an accuracy of 99.70%. Advanced contextual interpretation by LLMs enables the identification of various phishing tactics and impersonations, making them a potentially powerful tool in the fight against email-based phishing threats.
연구 동기 및 목표
- 전통적인 필터가 분류에 대한 설명을 제공하지 않는 피싱 이메일에 대한 방어를 촉진한다.
- 피싱 탐지를 위해 이메일을 LLM 분석용 프롬프트로 변환하는 시스템을 제안한다.
- 의심스러운 이메일을 처리하는 방법을 사용자가 결정하도록 돕기 위해 자세하고 합리적 근거가 풍부한 보고서를 가능하게 한다.
제안 방법
- .eml 이메일을 구문 분석하고 해독하여 헤더와 본문을 추출하되 서버 필터링 헤더는 생략한다.
- 롱 이메일을 LLM 토큰 한도(3,000 토큰)에 맞추기 위해 HTML/텍스트 가지치기로 간소화한다.
- 작업별 프롬프트를 생성하고 구조화된 분석을 위한 생각의 사슬(prompting)을 사용한다.
- 함수 호출을 사용해 LLM이 is_phishing, phishing_score, brand_impersonated, rationales, and brief_reason이 포함된 JSON 보고서를 반환하게 한다.
- 피싱/ham 데이터셋에서 다수의 LLM(GPT-4, GPT-3.5, Llama2, Gemini Pro)을 베이스라인과 비교 평가한다.
- 프롬프트 전략(Normal vs Simple) 비교 및 거짓 양성/거짓 음성 분석한다.
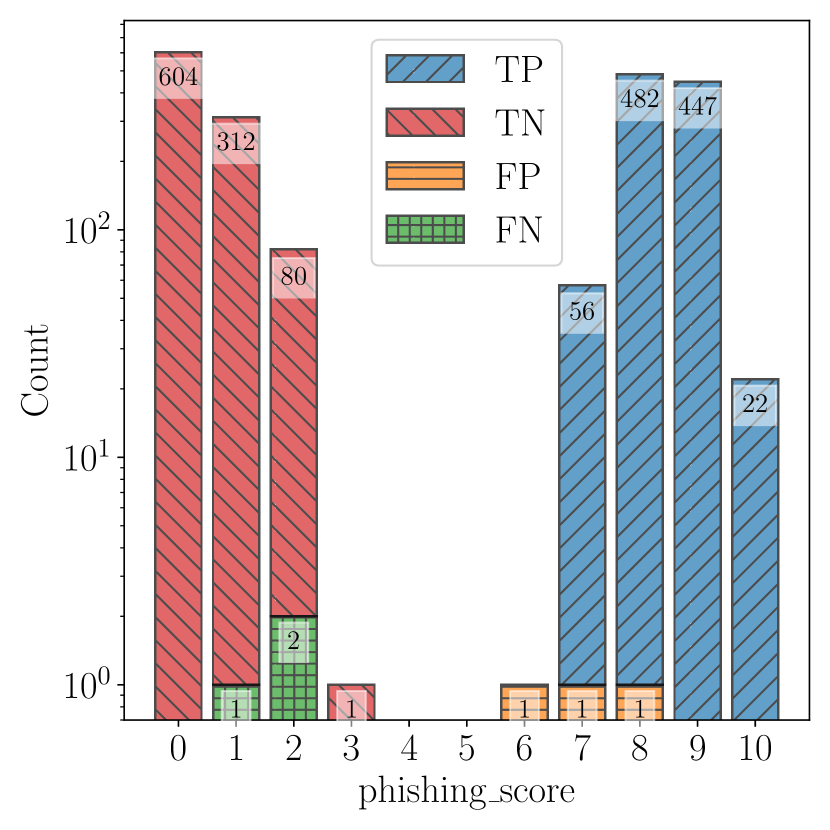
실험 결과
연구 질문
- RQ1이메일 파생 프롬프트로 요청될 때 LLM이 피싱 이메일을 신뢰할 수 있게 탐지할 수 있는가?
- RQ2현재 데이터셋에서 서로 다른 LLM(GPT-4, GPT-3.5, Llama2, Gemini Pro)의 피싱 탐지 성능은 어떻게 비교되는가?
- RQ3구조화된 합리화 및 브랜드 사칭 정보 제공이 사용자의 신뢰와 의사결정에 도움이 되는가?
- RQ4프롬프트 디자인(Normal vs Simple)이 정밀도, 재현율 및 거짓 양성에 미치는 영향은 무엇인가?
- RQ5현대 피싱 이메일에서 시스템 출력이 전통적인 베이스라인 분류기와 어떻게 비교되는가?
주요 결과
| System | Model | Prompt | TP | FP | TN | FN | Precision | Recall | Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| ChatSpamDetector | GPT-4 | Normal | 1,007 | 3 | 997 | 3 | 99.70% | 99.70% | 99.70% |
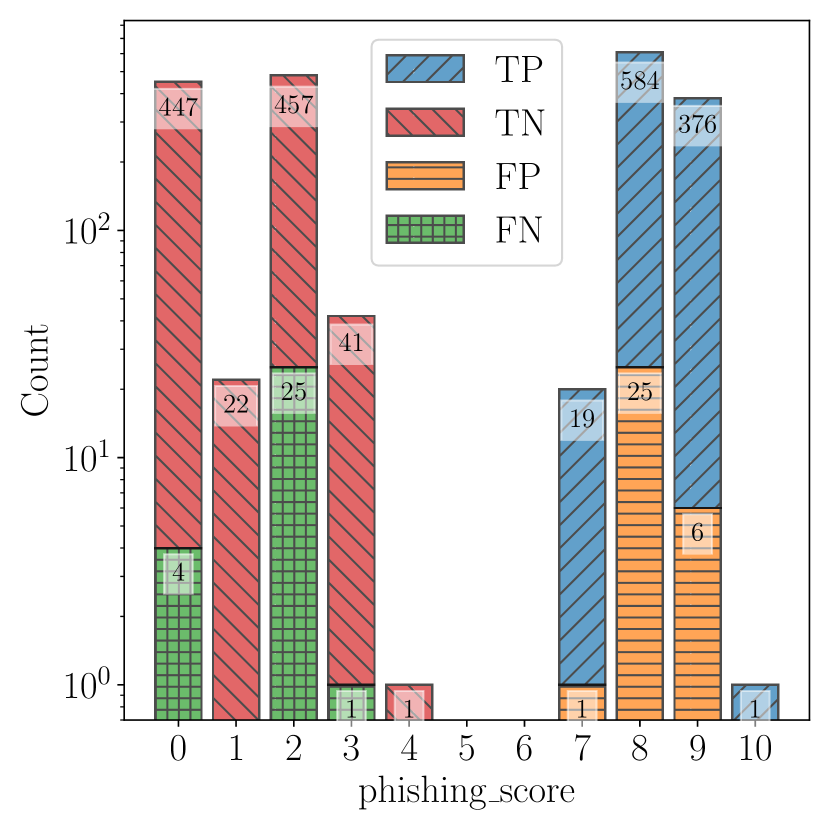
| ChatSpamDetector | GPT-4 | Simple | 1,001 | 4 | 996 | 9 | 99.60% | 99.11% | 99.35% |
| ChatSpamDetector | GPT-3.5 | Normal | 980 | 32 | 968 | 30 | 96.84% | 97.03% | 96.92% |
| ChatSpamDetector | GPT-3.5 | Simple | 697 | 6 | 994 | 313 | 99.15% | 69.01% | 84.13% |
| ChatSpamDetector | Llama2 | Normal | 950 | 361 | 639 | 60 | 72.46% | 94.06% | 79.05% |
| ChatSpamDetector | Llama2 | Simple | 790 | 9 | 991 | 220 | 98.87% | 78.22% | 88.61% |
| ChatSpamDetector | Gemini Pro | Normal | 991 | 21 | 979 | 19 | 97.92% | 98.12% | 98.01% |
| ChatSpamDetector | Gemini Pro | Simple | 977 | 6 | 994 | 33 | 99.39% | 96.73% | 98.06% |
| Baseline A | - | - | 580 | 374 | 626 | 430 | 60.80% | 57.43% | 60.00% |
| Baseline B | - | - | 564 | 413 | 587 | 446 | 57.73% | 55.84% | 57.26% |
| Baseline C | - | - | 923 | 827 | 173 | 87 | 52.74% | 91.39% | 54.53% |
| Baseline D | - | - | 941 | 208 | 792 | 69 | 81.90% | 93.17% | 86.22% |
- GPT-4 with a normal prompt achieved 99.70% accuracy, outperforming other models and baselines.
- Simple prompts reduced false positives but lowered recall for several models; normal prompts improved phishing identification and reduced false positives overall.
- GPT-4 generally provided the strongest performance (accuracy, precision, recall) among evaluated models (GPT-4 > GPT-3.5 > Gemini Pro > Llama2).
- The system achieved high phishing detection while extracting and reporting key indicators from headers and body, including brand impersonation and SE techniques.
- Compared to baselines, ChatSpamDetector substantially outperformed traditional feature-based methods on the same dataset.
- Reported latency and cost varied by model, with GPT-4 averaging ~12.5s per request and GPT-3.5 ~2.5s, and GPT-4 costing more.]
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.