[논문 리뷰] Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
이 논문은 LLM-Augmenter를 제시한다. 이는 외부 지식으로 고정된 LLM을 보강하는 플러그-앤-플레이 시스템이며, 자동 피드백을 통한 반복 프롬프트 수정, 그리고 유창성은 유지하면서 환각을 줄이는 학습 가능한 정책을 갖는다. 정보 탐색 대화 및 오픈 도메인 위키 QA에서 효과를 검증한다.
Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge. This paper proposes a LLM-Augmenter system, which augments a black-box LLM with a set of plug-and-play modules. Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of a LLM-generated response. The effectiveness of LLM-Augmenter is empirically validated on two types of scenarios, task-oriented dialog and open-domain question answering. LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. We make the source code and models publicly available.
연구 동기 및 목표
- 임무가 중요한 작업에 배치된 대형 언어 모델에서 환각 및 지식 격차를 줄이는 것을 목표로 한다.
- 외부 지식으로 LLM 응답을 구체화하기 위한 플러그-앤-플레이 아키텍처(LLM-Augmenter)를 제안한다.
- 응답 품질을 향상시키기 위해 자동 피드백을 통한 반복 프롬프트 개선을 가능하게 한다.
- 전체 미세 조정 없이 고정된 LLM과 함께 작동하도록 정책 및 모듈의 학습 전략을 탐구한다.
제안 방법
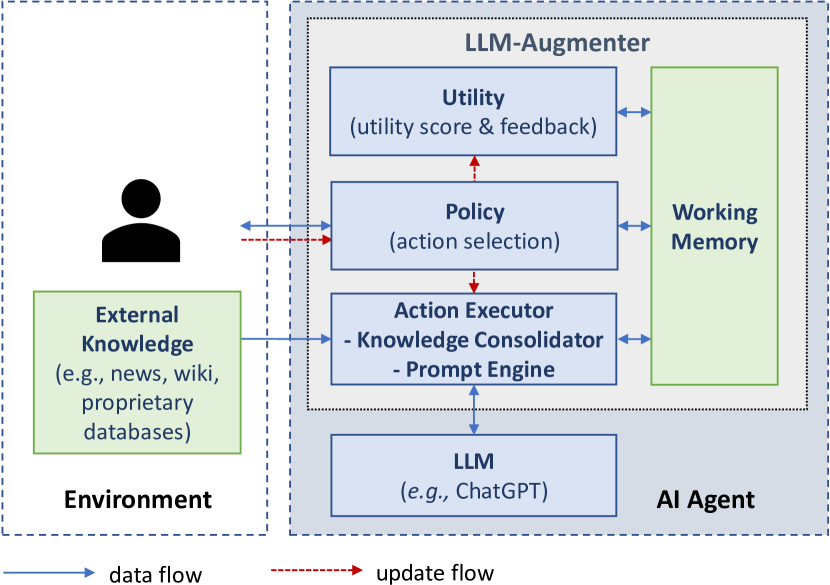
- 고정된 LLM에 외부 지식과 자동 피드백을 보강하는 플러그-앤-플레이 모듈 시스템으로 LLM-Augmenter를 소개한다.
- 모듈 간 상호 작용을 가이드하기 위해 인간-시스템 대화를 마르코프 의사 결정 과정(MDP)으로 모델링한다.
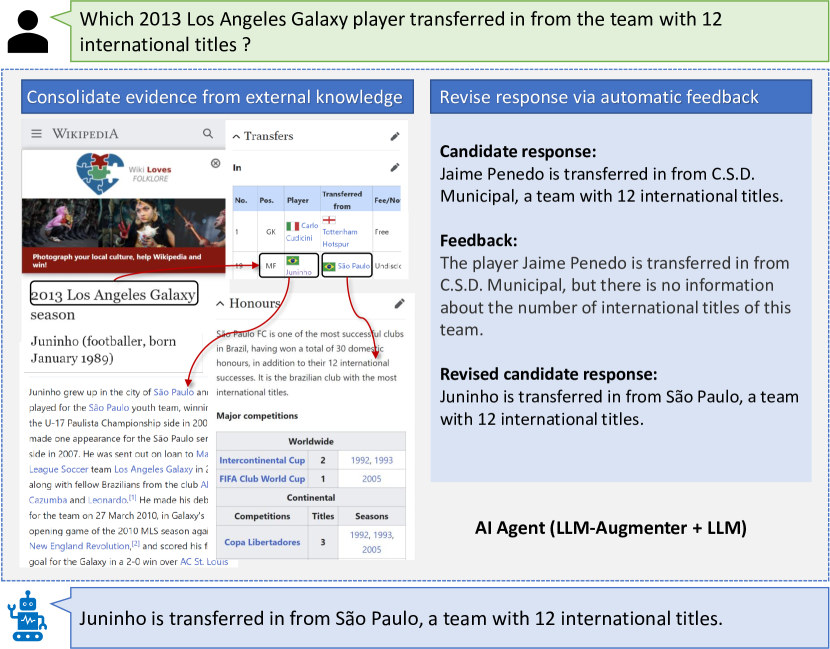
- 외부 증거를 검색하고 연결하는 지식 응집기와 근거를 위한 증거 체인기를 구현한다.
- 지식과 피드백을 반영한 프롬프트를 생성하는 프롬프트 엔진을 사용한다.
- 프롬프트 수정에 필요한 점수와 피드백을 생성하는 유틸리티 모듈을 개발한다.
- 근거화와 유용성에 기반한 보상을 극대화하기 위해 REINFORCE를 통해 정책(pi)을 학습한다.
실험 결과
연구 질문
- RQ1외부 지식 grounding이 고정된 LLM의 환각을 유창성을 잃지 않으면서 감소시킬 수 있는가?
- RQ2자동 피드백 및 반복 프롬프트 수정이 응답의 사실적 근거와 유용성을 향상시키는가?
- RQ3지식 소스를 사용할지 여부를 결정하는 데 있어 학습 가능한 정책의 효과는 어떠한가?
- RQ4지식 응집 및 피드백이 오픈 도메인 위키 QA 및 대화 과제에 미치는 영향은 무엇인가?
주요 결과
- LLM-Augmenter는 News Chat 및 고객 서비스 과제에서 ChatGPT만 사용할 때보다 grounding을 크게 개선하고 환각을 줄인다.
- 골든 지식을 사용하는 것이 큰 성능 향상을 가져와, grounding을 위한 특정 작업의 외부 지식의 가치가 있음을 강조한다.
- 자동 피드백과 증거 응집을 함께 사용하면 KF1 및 관련 지표가 베이스라인 대비 크게 향상된다.
- 지식 응집을 가진 학습 가능한 정책은 무지식 응집자나 자체-질문 변형(self-ask)보다 더 나은 grounding을 달성하고 항상 지식을 사용하는 경우보다 효율성이 더 높다.
- 위키 QA에서 CORE 기반 응집과 피드백은 원시 DPR 증거 및 비상책(ch) 대비 재현율과 F1을 크게 향상시킨다.
- 인간 평가에 따르면 LLM-Augmenter는 고객 서비스 시나리오에서 ChatGPT alone보다 더 유용하고 인간과 비슷하다고 평가된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.