[논문 리뷰] CLUSTSEG: Clustering for Universal Segmentation
ClustSeg는 세분화를 반복적 클러스터링으로 재구성하고, 작업별 비모수적 순환 교차 주의를 사용하여 단일 아키텍처 내에서 초분할(superpixel), 의미론적(semantic), 인스턴스(instance), 팬옵틱(panoptic) 세분화를 다루는 트랜스포머 기반의 보편적 세분화 프레임워크를 제시한다.
We present CLUSTSEG, a general, transformer-based framework that tackles different image segmentation tasks (i.e., superpixel, semantic, instance, and panoptic) through a unified neural clustering scheme. Regarding queries as cluster centers, CLUSTSEG is innovative in two aspects:1) cluster centers are initialized in heterogeneous ways so as to pointedly address task-specific demands (e.g., instance- or category-level distinctiveness), yet without modifying the architecture; and 2) pixel-cluster assignment, formalized in a cross-attention fashion, is alternated with cluster center update, yet without learning additional parameters. These innovations closely link CLUSTSEG to EM clustering and make it a transparent and powerful framework that yields superior results across the above segmentation tasks.
연구 동기 및 목표
- 작업별 아키텍처에 의존하지 않는 다중 세분화 패러다임을 처리할 수 있는 보편적 세분화 프레임워크를 동기 부여한다.
- 세분화를 서로 다른 태스크로 통합하기 위해 세분화를 클러스터링 문제로 재구성한다.
- 태스크에 따라 군집 중심을 시드하기 위한 태스크 인지 초기화(Dreamy-Start)를 도입한다.
- 학습 가능한 매개변수를 추가하지 않고도 반복적 EM 유사 클러스터링을 수행하는 비모수적 순환 교차 주의 메커니즘을 개발한다.
- 핵심 세분화 벤치마크에서 우수한 성능을 보여준다.
제안 방법
- 쿼리를 군집 중심으로 간주하고 태스크 인지 의미를 가진 초기값으로 초기화한다: 의미론/스루(stuff)에는 클래스 중심의 시드; 인스턴스/물체(thing)에는 이미지에서 파생된 시드; 초분할에는 그리드 기반 시드를 사용한다.
- 교차 주의가 군집 멤버십(E-단계)과 중심(M-단계)을 학습 가능한 매개변수 없이 업데이트하는 EM-inspired 반복 체계를 채택한다.
- 다중 EM 유사 반복을 효율적으로 수행하기 위해 순환 교차 주의(RCross_Attention)를 구현한다(복잡도는 O(TKHW D)로, 무의미한 교차 주의의 경우 O(HW D)보다 효율적이다).
- 의미론 초기화를 위한 메모리-뱅크 지원 Dreamy-Start를 사용하여 전역 클래스 통계치를 인코딩한다; 인스턴스 세분화를 위한 이미지 맥락 적응 시드를 사용한다; 초분할 세분화를 위한 그리드 기반 시드를 사용한다.
- 해상도 및 태스크 간 군집화를 개선하기 위해 계층화된 RCross_Attention 디코더를 활용한다.
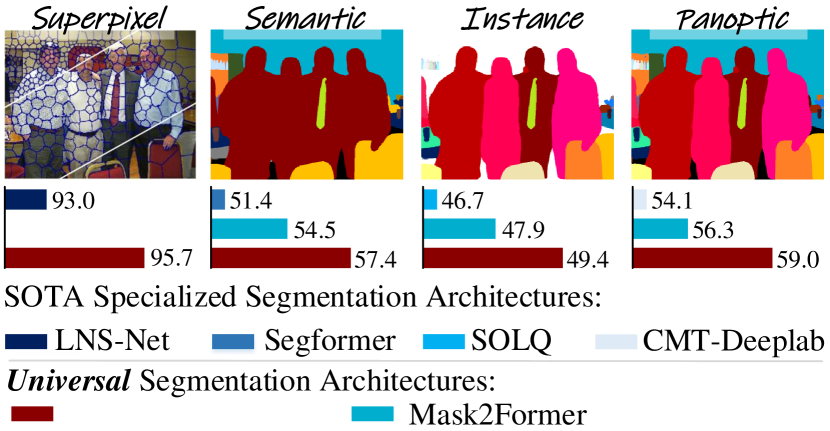
실험 결과
연구 질문
- RQ1단일 트랜스포머 기반 프레임워크가 세그먼테이션을 클러스터링으로 형상화하여 초분할, 의미론, 인스턴스, 팬옵틱 세분화를 통합할 수 있는가?
- RQ2태스크별 의미를 존중하기 위해(의미론 vs. 인스턴스 vs. 초분할) 군집 중심을 아키텍처를 바꾸지 않고 초기화하는 방법은 무엇인가?
- RQ3EM-inspired 비모수적 순환 교차 주의 전략이 다양한 태스크에서 고품질 세분화로 효율적으로 수렴할 수 있는가?
- RQ4Dreamy-Start 초기화가 벤치마크에서 세분화 성능에 미치는 영향은 무엇인가?
- RQ5ClustSeg 설계가 표준 데이터셋에서 태스크별 및 다른 보편적 모델에 비해 얼마나 잘 수행하는가?
주요 결과
| Algorithm | Backbone | Epoch | PQ ↑ | PQ^Th ↑ | PQ^St ↑ | AP^Th_pan ↑ | mIoU_pan ↑ |
|---|---|---|---|---|---|---|---|
| ClustSeg (ours) | ResNet-50 | 50 | 54.3 ±0.20 | 60.4 ±0.22 | 45.8 ±0.23 | 42.2 ±0.18 | 63. |
- ClustSeg는 COCO 팬옵틱 세분화에서 PQ 59.0, COCO 인스턴스 세분화에서 AP 49.1, ADE20K 의미론적 세분화에서 mIoU 57.4, BSDS500 초분할에서 최고 ASA/CO 등 핵심 네 가지 태스크에서 높은 세분화 성능을 달성한다.
- 태스크 인지 쿼리 초기화(Dreamy-Start)를 도입하여 아키텍처 변경 없이도 다양한 태스크에 대해 정보에 유용한 클러스터 시드를 제공한다.
- 학습 가능한 매개변수를 추가하지 않고 이터레이티브 E- 및 M-단계가 가능한 EM 클러스터링을 모방하는 비모수적 순환 교차 주의 모듈을 제시하여 클러스터링 품질을 향상시킨다.
- 통합 트랜스포머 프레임워크 내의 클러스터링 기반 세분화가 핵심 벤치마크에서 특화된 모델 및 기존의 보편적 모델보다 우수하다는 것을 보여준다.
- ClustSeg 설계가 팬옵틱 COCO에서 PQ 및 AP 지표와 의미론/인스턴스/팬옵틱 품질 지표에서 established 데이터셋 전반에 걸쳐 강력한 결과를 낳는다는 것을 보여준다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.