[논문 리뷰] Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
Cobra는 linear-time Mamba 상태공간 모델과 비전 인코더를 통합하여 멀티모달 LLM을 구축하고, Transformer 기반 베이스라인 대비 3–4x 더 빠른 추론 속도를 달성하며 더 큰 모델의 약 43% 파라미터를 사용하면서도 경쟁력 있는 정확도를 제공합니다.
In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the foundation model for many downstream tasks, current MLLMs are composed of the well-known Transformer network, which has a less efficient quadratic computation complexity. To improve the efficiency of such basic models, we propose Cobra, a linear computational complexity MLLM. Specifically, Cobra integrates the efficient Mamba language model into the visual modality. Moreover, we explore and study various modal fusion schemes to create an effective multi-modal Mamba. Extensive experiments demonstrate that (1) Cobra achieves extremely competitive performance with current computationally efficient state-of-the-art methods, e.g., LLaVA-Phi, TinyLLaVA, and MobileVLM v2, and has faster speed due to Cobra's linear sequential modeling. (2) Interestingly, the results of closed-set challenging prediction benchmarks show that Cobra performs well in overcoming visual illusions and spatial relationship judgments. (3) Notably, Cobra even achieves comparable performance to LLaVA with about 43% of the number of parameters. We will make all codes of Cobra open-source and hope that the proposed method can facilitate future research on complexity problems in MLLM. Our project page is available at: https://sites.google.com/view/cobravlm.
연구 동기 및 목표
- Transformer-based MLLMs의 제곱 복잡도로 인한 효율성 한계 동기부여.
- 멜티모달 처리를 위한 선형 시간 상태공간 모델(Mamba)을 사용하는 Cobra 아키텍처 제안.
- 모달 융합 스키마를 조사해 시각 정보와 언어 정보를 효과적으로 통합.
- 표준 VLM 벤치마크에서 Cobra의 경쟁력 있는 성능 및 뛰어난 속도 시연.
- 성능을 유지하면서 파라미터 수의 잠재적 감소를 보여줌.
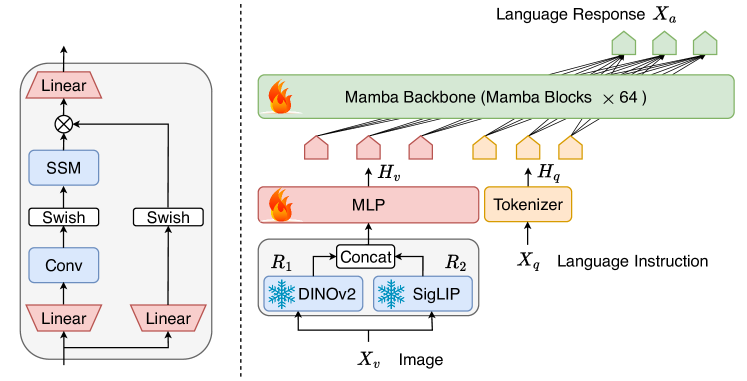
제안 방법
- 이미지에서 시각 표현을 추출하기 위해 비전 인코더 스택(DINOv2 + SigLIP) 사용.
- 시각 토큰을 Mamba 토큰 공간에 맞추기 위한 프로젝터 모듈 도입(MLP 또는 대안).
- 64개 블록으로 구성된 백본으로 Mamba를 채택해 시각 및 텍스트 임베딩을 자동회귀적으로 연결 처리.
- 몰입 모달 표현을 최적화하기 위해 다양한 융합 스키마를 탐색하며 Mamba 내 시각 및 언어 모듈을 융합.
- ~1.2M 이미지-텍스트 샘플을 두 에폭에 걸쳐 전체 LLM 백본과 프로젝터를 미세조정하며 엔드투엔드 학습.
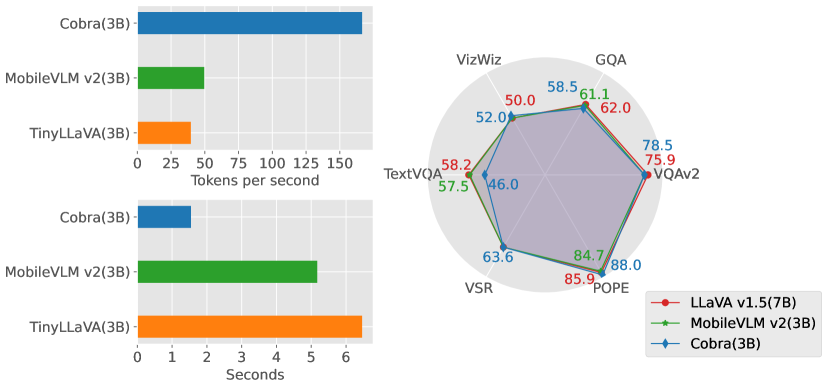
실험 결과
연구 질문
- RQ1선형 시간 상태공간 모델(Mamba)이 시각 인코더와 함께 사용할 때 멀티모달 대형 언어 모델링을 효과적으로 지원할 수 있는가?
- RQ2Cobra 내에서 어떤 비전 인코더와 프로젝션 전략이 시각 정보를 가장 잘 보존하여 정확한 멀티모달 추론에 기여하는가?
- RQ3Cobra는 Transformer 기반 동료들과 비슷한 파라미터 예산에서 개방형 VQA 및 닫힌 집합 공간/현실착실 벤치마크에서 어떻게 성능을 발휘하는가?
- RQ4MLLMs를 위한 상태공간 백본 채택 시 추론 속도 및 메모리 사용 측면에서 Transformer 베이스라인 대비 어떤 이득이 있는가?
주요 결과
| 모델 | LLM | VQA_v2 | GQA | VizWiz | VQA_T | VSR | POPE |
|---|---|---|---|---|---|---|---|
| OpenFlamingo | MPT-7B | 52.7 | - | 27.5 | 33.6 | - | - |
| BLIP-2 | Vicuna-13B | - | 41.0 | 19.6 | 42.5 | 50.9 | - |
| MiniGPT-4 | Vicuna-7B | 32.2 | - | - | - | - | - |
| InstructBLIP | Vicuna-7B | - | 49.2 | 34.5 | 50.1 | 54.3 | - |
| InstructBLIP | Vicuna-13B | - | 49.5 | 33.4 | 50.7 | 52.1 | - |
| Shikra | Vicuna-13B | 77.4 | - | - | - | - | - |
| IDEFICS | LLaMA-7B | 50.9 | - | 35.5 | 25.9 | - | - |
| IDEFICS | LLaMA-75B | 60.0 | - | 36.0 | 30.9 | - | - |
| Qwen-VL | Qwen-7B | 78.2 | 59.3 | 35.2 | 63.8 | - | - |
| LLaVA v1.5 | Vicuna-7B | 78.5 | 62.0 | 50.0 | 58.2 | - | 85.9 |
| Prism | LLaMA-7B | 81.0 | 65.3 | 52.8 | 59.7 | 59.6 | 88.1 |
| ShareGPT4V | Vicuna-7B | 80.6 | 57.2 | - | - | - | - |
| MoE-LLaVA | StableLM-1.6B | 76.7 | 60.3 | 36.2 | 50.1 | - | 85.7 |
| MoE-LLaVA | Phi2-2.7B | 77.6 | 61.4 | 43.9 | 51.4 | - | 86.3 |
| Llava-Phi | Phi2-2.7B | 71.4 | - | 35.9 | 48.6 | - | 85.0 |
| MobileVLM v2 | MobileLLaMA-2.7B | - | 61.1 | - | 57.5 | - | 84.7 |
| TinyLLaVA | Phi2-2.7B | 79.9 | 62.0 | - | 59.1 | - | 86.4 |
| Cobra (ours) | Mamba-2.8B | 75.9 | 58.5 | 52.0 | 46.0 | 63.6 | 88.0 |
- Cobra는 선형 순차 모델링의 이점을 활용하면서 LLaVA-Phi, TinyLLaVA, MobileVLM v2 등과 같은 수준의 효율적인 최첨단 방법과 비교 가능한 성능을 달성.
- Cobra는 공간 관계 판단 및 시각적 환각 감소를 포함한 닫힌 집합 과제에서 강한 강건성을 보여줌.
- 약 43%의 파라미터를 가진 Cobra가 LLaVA v1.5 7B와 유사한 벤치마크에서 비교 가능한 성능을 달성, 효율성 이점 강조.
- 추론 속도는 Cobra에서 크게 빠름(예: 유사한 크기에서 MobileVLM v2 및 TinyLLaVA 대비 3배~4배 빠름).
- 애블레이션 결과 DINOv2와 SigLIP의 결합이 성능을 향상시키며 챗-조정된 Mamba 모델의 미세조정이 지시 준수 성능을 더 낫게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.