[논문 리뷰] CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X
CodeGeeX는 23개 언어에 걸쳐 850B 토큰으로 학습된 13B 다국어 코드 생성 모델로, 코드 생성 및 번역에서 유사 규모의 베이스라인보다 성능을 앞서며, 오픈 소스 릴리스와 HumanEval-X 벤치마크를 제공합니다.
Large pre-trained code generation models, such as OpenAI Codex, can generate syntax- and function-correct code, making the coding of programmers more productive and our pursuit of artificial general intelligence closer. In this paper, we introduce CodeGeeX, a multilingual model with 13 billion parameters for code generation. CodeGeeX is pre-trained on 850 billion tokens of 23 programming languages as of June 2022. Our extensive experiments suggest that CodeGeeX outperforms multilingual code models of similar scale for both the tasks of code generation and translation on HumanEval-X. Building upon HumanEval (Python only), we develop the HumanEval-X benchmark for evaluating multilingual models by hand-writing the solutions in C++, Java, JavaScript, and Go. In addition, we build CodeGeeX-based extensions on Visual Studio Code, JetBrains, and Cloud Studio, generating 4.7 billion tokens for tens of thousands of active users per week. Our user study demonstrates that CodeGeeX can help to increase coding efficiency for 83.4% of its users. Finally, CodeGeeX is publicly accessible and in Sep. 2022, we open-sourced its code, model weights (the version of 850B tokens), API, extensions, and HumanEval-X at https://github.com/THUDM/CodeGeeX.
연구 동기 및 목표
- 폭넓은 언어 지원(23개 언어)과 강력한 교차 언어 능력을 갖춘 다국어 코드 생성 모델을 개발한다.
- 생성 및 번역 작업에서 기능적 정확성을 평가하기 위해 다국어 코드 모델을 평가하는 HumanEval-X를 만들고 공개한다.
- 현업에 도입 가능한 영향력을 보여주고 코딩 생산성을 높이기 위한 실용 도구(IDE 확장)를 제공한다.
- 재현성과 추가 연구를 가능하게 하도록 모델, 가중치, API 및 평가 벤치마크를 오픈 소스한다.
제안 방법
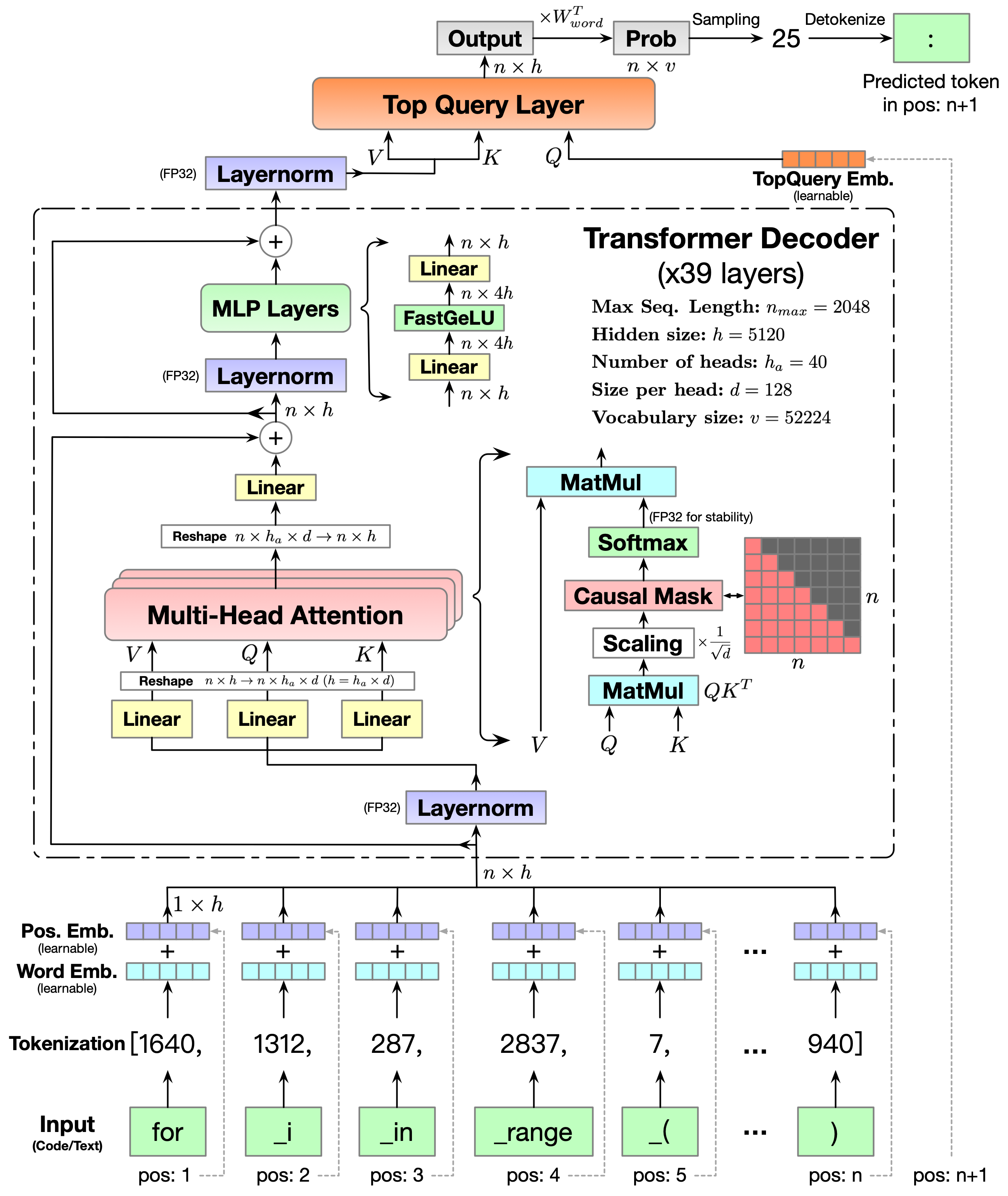
- 자회귀 코드 모델링을 위해 39개의 트랜스포머 계층을 가진 GPT-스타일 디코더 아키텍처를 채택한다.
- CodeGeeX(13B 파라미터)를 23개 언어에 걸친 코드 말뭉치에서 850B 토큰으로 학습하며, 두 달간 Ascend 910 클러스터로 실행한다.
- 훈련 중 언어 구분을 돕기 위해 입력 시퀀스에 언어 지시자를 태깅한다.
- 최종 토큰 예측을 위한 Top Query Layer를 사용하고 탐욕적, top-k, 핵심(nucleus), 빔 탐색 등 여러 디코딩 전략을 공개한다.
- HumanEval-X 벤치마크의 pass@k와 다국어 예산 할당을 통해 교차 언어 해결률을 최적화하여 평가한다.
- FP16/FP32 정밀도 튜닝, 사후 훈련 양자화 INT8, NVIDIA FasterTransformer를 통한 가속화 등 추론 최적화를 제공한다.
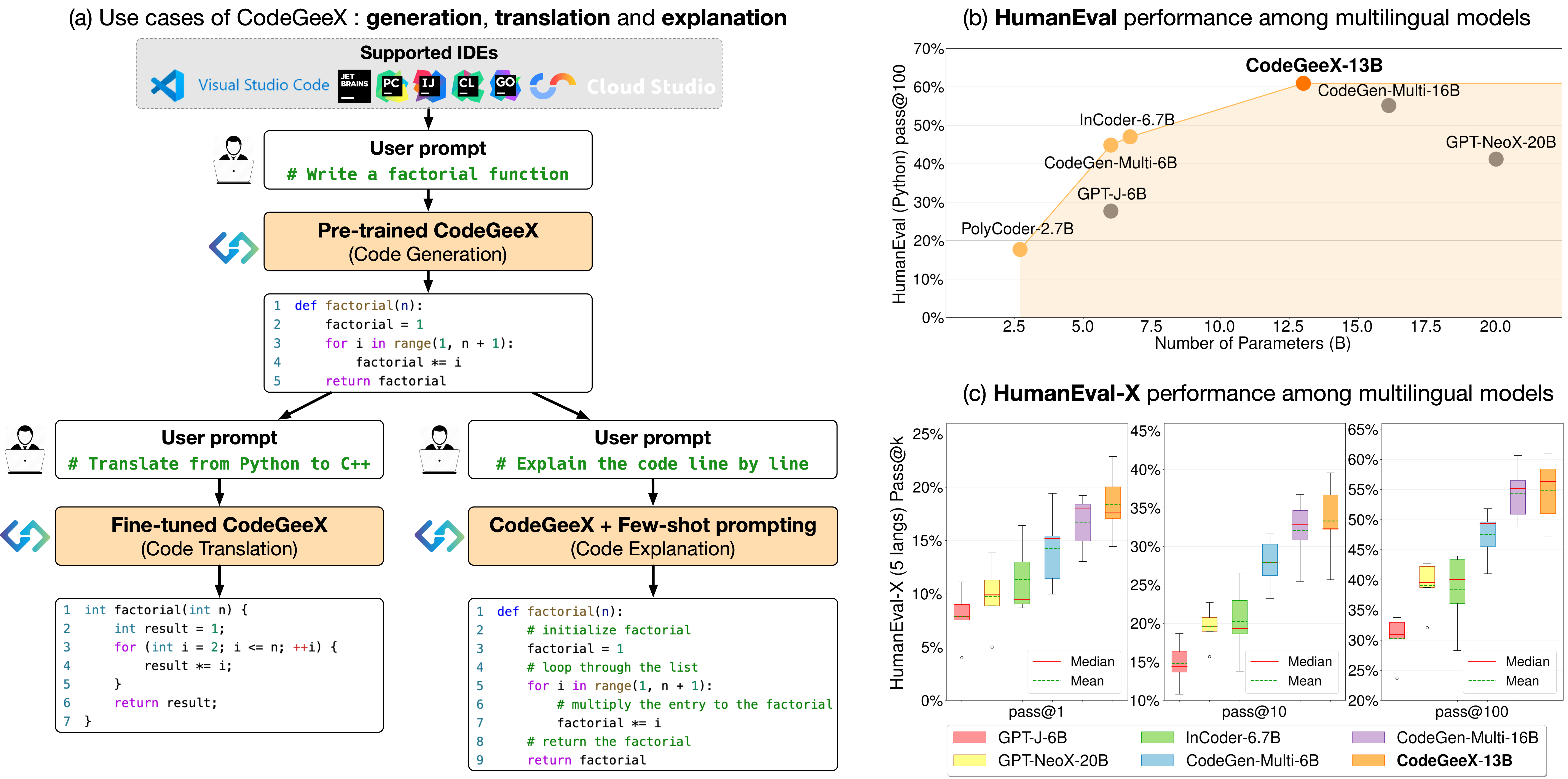
실험 결과
연구 질문
- RQ1CodeGeeX가 Python, C++, Java, JavaScript, Go에서 다국어 규모의 베이스라인과 비교하여 코드 생성에서 어떤 성과를 보이나?
- RQ25개 언어 간(20개 소스-타깃 쌍) 코드 번역에서 기능적 정확성 측면에서 CodeGeeX가 얼마나 잘 작동하는가?
- RQ3다수의 언어에 걸쳐 생성 예산을 분배하는 것이 다국어 모델의 해결 성능(pass@k)에 어떤 영향을 미치는가?
- RQ4현실적인 코딩 작업에서 CodeGeeX 확장(VS Code, JetBrains, Cloud Studio)이 어떤 실용적 이점을 제공하는가?
주요 결과
- CodeGeeX는 HumanEval-X에서 코드 생성과 번역 작업 모두에서 유사 규모의 다국어 베이스라인 모델을 능가한다.
- CodeGeeX는 언어 전반에서 최고의 평균 성능을 달성하고, 여러 베이스라인 대비 이득을 보이며 더 큰 CodeGen-Multi-16B와도 경쟁력 있는 결과를 보인다.
- HumanEval-X는 164개 문제와 820개의 언어별 해답으로 구성되어 있으며, 테스트 케이스를 통한 기능적 정확성으로 크로스-언어 생성과 번역을 평가할 수 있게 한다.
- IDE의 CodeGeeX 확장은 코드 완성, 생성, 번역 및 설명을 지원하고, 사용자 설문에서 효율성 향상이 83.4%로 보고된다.
- 이 프로젝트는 850B-토큰 버전의 모델 가중치, API, 확장 및 HumanEval-X를 오픈 소스했으며 2022년 9월에 공개되었고, 실제 사용이 상당하다고 보고되었다(주당 4.7B 토큰 생성).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.