[논문 리뷰] Collaborating with language models for embodied reasoning
본 논문은 사전 학습된 언어 모델과 구현된 RL 에이전트를 결합하여 2D 격자 세계에서 다단계 추론과 정보 수집을 수행하는 Planner-Actor-Reporter 아키텍처를 제안하며, 제로샷 일반화 및 협업 향상을 위한 RL 학습 보고를 시연한다.
Reasoning in a complex and ambiguous environment is a key goal for Reinforcement Learning (RL) agents. While some sophisticated RL agents can successfully solve difficult tasks, they require a large amount of training data and often struggle to generalize to new unseen environments and new tasks. On the other hand, Large Scale Language Models (LSLMs) have exhibited strong reasoning ability and the ability to to adapt to new tasks through in-context learning. However, LSLMs do not inherently have the ability to interrogate or intervene on the environment. In this work, we investigate how to combine these complementary abilities in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command. We present a set of tasks that require reasoning, test this system's ability to generalize zero-shot and investigate failure cases, and demonstrate how components of this system can be trained with reinforcement-learning to improve performance.
연구 동기 및 목표
- 사전 학습된 언어 모델이 자연어 지시를 발행하는 플래너로 작동하여 구현된 에이전트(액터)와 상호 작용하는 방법을 demonstrable로 보여준다.
- Reporter가 Actor의 관찰을 다시 Planner로 번역하여 지시를 다듬는 폐회로를 형성하는지 보여준다.
- 플래너의 크기와 작업 변형에 따른 제로샷 일반화 및 강건성을 평가한다.
- Hand-crafted 피드백의 의존도를 줄이고 협업을 개선하기 위해 Reporter를 강화 학습으로 학습시키는 가능성을 조사한다.
- 불완전한 보고에서 시스템의 실패 모드와 강건성을 분석한다.
제안 방법
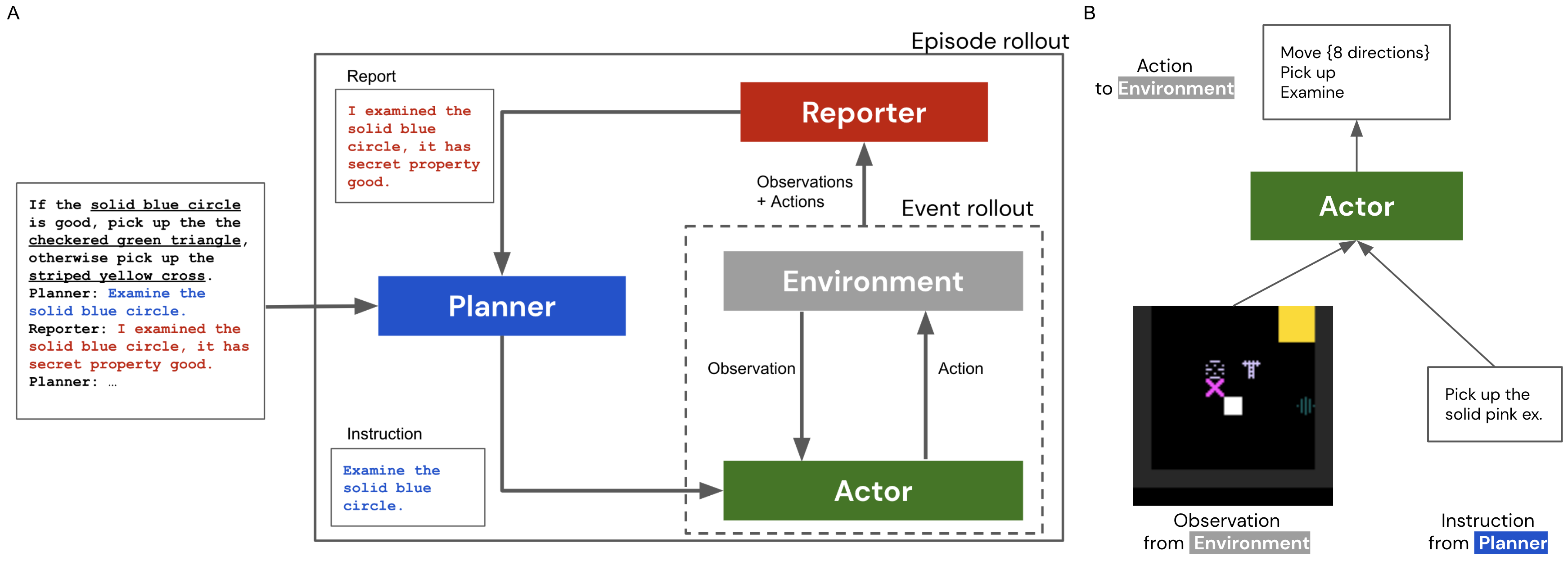
- Planner(LSLM), Actor(RL 에이전트), Reporter가 Actor 데이터를 Planner로 다시 번역하는 세 부분 시스템을 구현한다.
- 7B 및 70B 매개변수의 Chinchilla 기반 LLM을 Few-shot 프롬프트가 있는 Planners로 사용한다.
- 간단한 픽업 및 검사 작업에 대해 Actor를 학습시키고, 관찰자는 내부 환경 Reporter를 사용하여 지시를 피드백한다.
- 색상, 모양, 질감으로 구분되는 물체가 있는 2D 부분 관찰 가능 격자 세계를 정의하고 검사 및 픽업 동작을 허용한다.
- 정보 수집 및 보고된 속성에 따른 조건적 의사결정이 필요한 비밀 특성 작업을 실험한다.
- Report의 불완전성에 대한 플래너의 강건성을 평가하고 보상을 최적화하기 위해 Reporter를 RL로 학습하는 것을 탐구한다.
실험 결과
연구 질문
- RQ1플래너-액터-리포터 시스템이 구현된 환경에서 정보 수집 태스크의 제로샷 해결을 가능하게 하는가?
- RQ2플래너의 크기(7B 대 70B)가 Reporter의 불완전성에 대한 성능과 강건성에 어떤 영향을 미치는가?
- RQ3Reporter가 불완전할 때의 주요 실패 모드는 무엇이며, 명시적 프롬프트가 이를 완화할 수 있는가?
- RQ4학습된 Reporter가 RL을 통해 성능을 향상시키고 Hand-crafted 피드백에 대한 의존도를 줄일 수 있는가?
- RQ5제안된 태스크가 구현된 사고에서 논리적 추론, 일반화, 탐색 및 지각을 얼마나 잘 탐구하는가?
주요 결과
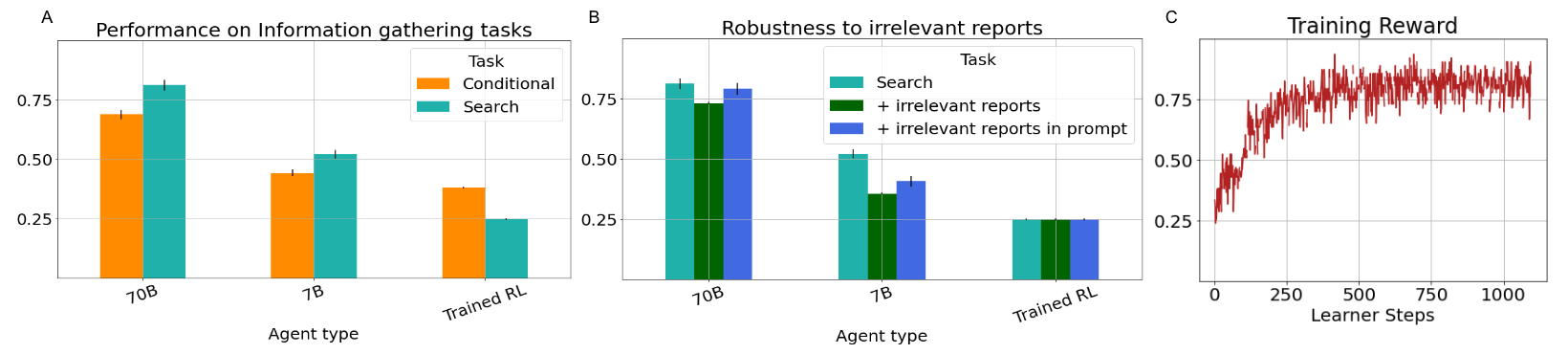
- 70B 플래너가 정보 수집 태스크에서 7B 플래너보다 더 높은 성공률을 보인다(예: 올바른 물체를 선택하는 추론이 더 우수).
- 순수 RL 기반 벤치마크는 비밀 속성 태스크에서 어려움을 겪는 반면 Planner-Actor-Reporter는 강력한 제로샷 성능을 달성한다.
- 플래너는 시끄러운 보고에 대해 강건하며, 20%의 관련 없는 보고 아래에서도 70B가 7B보다 성능을 더 잘 유지한다.
- 보고가 무의미할 때도 반복 전략을 보여주는 프롬프트를 제공하면 성능을 회복할 수 있다.
- RL로 Reporter를 학습하는 것은 실행 가능하며 태스크 성공에 가장 유용한 정보를 플래너가 학습하도록 돕는다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.