[논문 리뷰] Complex Logical Reasoning over Knowledge Graphs using Large Language Models
LARK는 KG 질의의 추상화를 통해 지식 그래프(KG) 위의 논리적 추론을 대형 언어 모델과 통합하며, KG 쿼리를 추상화하고 하위 그래프를 검색하며 다중 연산 쿼리를 단일 연산 프롬프트의 연속 LLM 추론으로 분해하여 표준 KG 벤치마크에서 최첨단 성능을 달성합니다.
Reasoning over knowledge graphs (KGs) is a challenging task that requires a deep understanding of the complex relationships between entities and the underlying logic of their relations. Current approaches rely on learning geometries to embed entities in vector space for logical query operations, but they suffer from subpar performance on complex queries and dataset-specific representations. In this paper, we propose a novel decoupled approach, Language-guided Abstract Reasoning over Knowledge graphs (LARK), that formulates complex KG reasoning as a combination of contextual KG search and logical query reasoning, to leverage the strengths of graph extraction algorithms and large language models (LLM), respectively. Our experiments demonstrate that the proposed approach outperforms state-of-the-art KG reasoning methods on standard benchmark datasets across several logical query constructs, with significant performance gain for queries of higher complexity. Furthermore, we show that the performance of our approach improves proportionally to the increase in size of the underlying LLM, enabling the integration of the latest advancements in LLMs for logical reasoning over KGs. Our work presents a new direction for addressing the challenges of complex KG reasoning and paves the way for future research in this area.
연구 동기 및 목표
- 전통적인 임베딩 기반 방법을 넘어 크고 시끄럽고 불완전한 지식 그래프에서 강건한 추론의 필요성을 제시합니다.
- 추상화와 하위 그래프 맥락을 사용하여 KG 추론을 LLM 추론에서 분리하고, 간단한 프롬프트에 대한 LLM 강점을 활용합니다.
- 체인 분해 및 논리적으로 정렬된 프롬프트를 통해 복잡한 일차 로직 질의(p, ∧, ∨, ¬)에서 성능을 향상시킵니다.
- 더 큰 LLM으로의 확장성 확보 및 추상화가 일반화 및 헛현상 감소에 미치는 영향을 분석합니다.
제안 방법
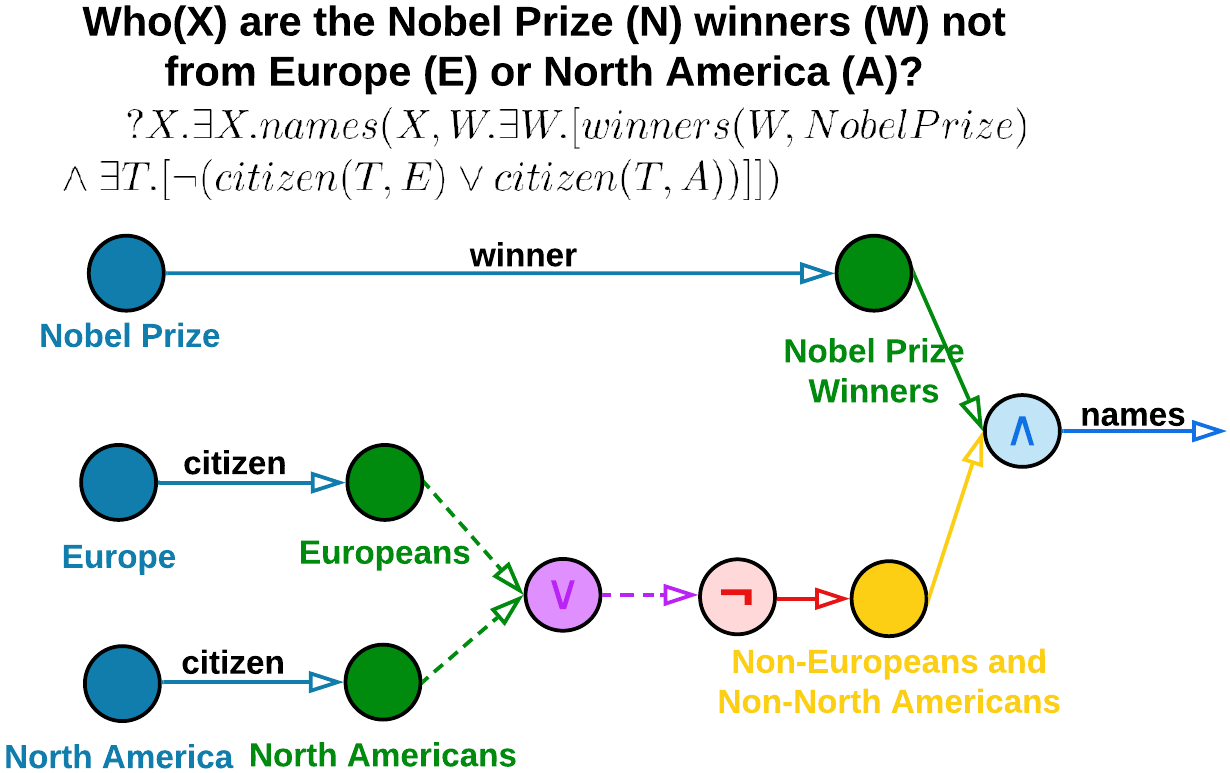
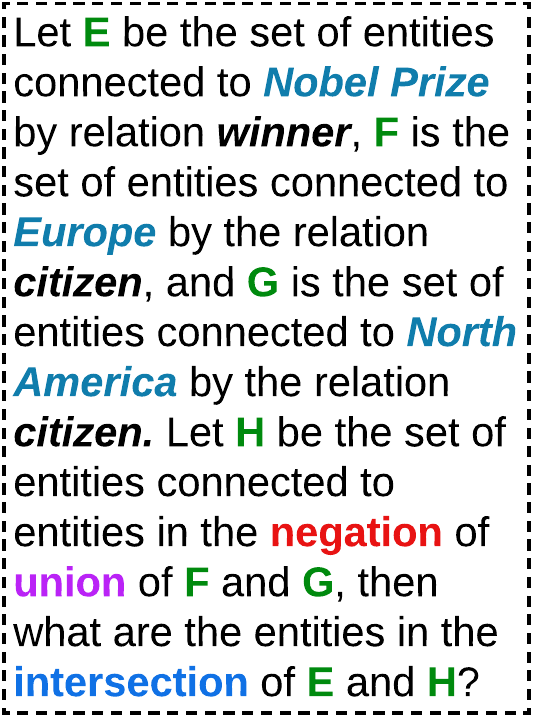
- 엔티티와 관계를 고유 ID로 추상화하여 KG-배제 프롬프트를 형성하고 토큰 부하를 줄입니다.
- 쿼리 엔티티/관계 주변의 컨텍스트 부분그래프를 구성하기 위해 n단계 이웃 검색을 수행합니다.
- 복잡한 다중 연산 질의를 단일 연산 질의의 시퀀스(예: 3p → 1p 체인; 3i/2i와 투영)를 통해 분해합니다.
- 분해된 질의와 이웃 맥락을 의존 답변에 대한 자리표시자와 이전 결과의 메모리 내 캐시를 갖춘 LLM 프롬프트로 변환합니다.
- 논리적으로 정렬된 단계에서 분해된 프롬프트를 처리하고 배치 처리 및 중간 결과 재사용을 가능하게 하여 헛현상을 최소화합니다.
- 실험적으로 LARK를 FB15k, FB15k-237, NELL995에서 기반선(GQE, Q2B, BetaE, HQE, HypE, CQD)과 비교하여 검증합니다.
실험 결과
연구 질문
- RQ1LARK가 표준 KG 논리 추론 벤치마크에서 기존 최첨단 기반선을 능가합니까?
- RQ2연쇄 분해 프롬프트가 LLM 기반 KG 추론에서 표준 복합 프롬프트보다 더 효과적입니까?
- RQ3더 큰 LLM 및 토큰 용량으로 확장될 때 LARK의 성능은 어떻게 증가합니까?
- RQ4쿼리 추상화가 데이터 세트 전반의 성능과 일반화에 미치는 영향은 무엇입니까?
- RQ5LARK가 부정 및 복합 질의 유형을 이전 방법보다 더 효과적으로 처리합니까?
주요 결과
- LARK는 14개의 FOL 질의 유형에서 여러 데이터셋에 걸쳐 33%–64%의 MRR로 이전 최첨단 기반선을 능가합니다.
- 체인 분해는 복합 질의에 비해 9%–26%의 개선을 가져오며, LLM의 추론을 분해하는 이점을 강조합니다.
- LLM의 크기 증가(Flan-T5 L에서 XXL로)가 상당한 이득을 가져오며 FB15k-237에서 최대 118%의 MRR 증가를 보입니다.
- 쿼리 추상화는 토큰 로드를 줄이고 헛현상 위험을 감소시키며 성능 저하가 거의 없고, 의미가 풍부한 변형은 복합 질의에서 토큰 한도 때문에 성능이 다소 저하될 수 있습니다.
- LARK는 부정 처리에 강력한 면모를 보이며, 부정 질의에서 종종 기준선을 능가하지만 일부 질의 유형의 토큰 길이 제약과 관련된 주의점이 있습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.