[논문 리뷰] Context Matters: A Strategy to Pre-train Language Model for Science Education
논문은 도메인 내 과학 교육 데이터에서 BERT 기반 모델의 지속적 사전 학습이 학생 과학 작문 자동 채점을 향상시키며, SR2-BERT와 SR2-SciBERT가 하류 작업에서 최상의 성과를 달성함을 보여준다.
This study aims at improving the performance of scoring student responses in science education automatically. BERT-based language models have shown significant superiority over traditional NLP models in various language-related tasks. However, science writing of students, including argumentation and explanation, is domain-specific. In addition, the language used by students is different from the language in journals and Wikipedia, which are training sources of BERT and its existing variants. All these suggest that a domain-specific model pre-trained using science education data may improve model performance. However, the ideal type of data to contextualize pre-trained language model and improve the performance in automatically scoring student written responses remains unclear. Therefore, we employ different data in this study to contextualize both BERT and SciBERT models and compare their performance on automatic scoring of assessment tasks for scientific argumentation. We use three datasets to pre-train the model: 1) journal articles in science education, 2) a large dataset of students' written responses (sample size over 50,000), and 3) a small dataset of students' written responses of scientific argumentation tasks. Our experimental results show that in-domain training corpora constructed from science questions and responses improve language model performance on a wide variety of downstream tasks. Our study confirms the effectiveness of continual pre-training on domain-specific data in the education domain and demonstrates a generalizable strategy for automating science education tasks with high accuracy. We plan to release our data and SciEdBERT models for public use and community engagement.
연구 동기 및 목표
- 학생의 과학적 작문 자동 채점을 촉진하고 교사의 주석 작업 부담을 줄인다.
- 과학 교육 과제에서 도메인 특화 사전학습 데이터가 BERT 기반 모델의 성능을 향상시키는지 조사한다.
- BERT 및 SciBERT 변형 간의 도메인 내 맥락화 전략을 비교한다.
- 학생 응답에 대한 지속적 사전학습이 하류 채점 작업에 미치는 효과를 입증한다.
- SciEdBERT 모델을 커뮤니티 사용을 위해 공개하고 확장 가능한 접근 방식을 제공한다.
제안 방법
- 세부 사전학습 모델을 미세 조정하기 전에 도메인 내 데이터로 문맥화하는 피라미드 학습 방식 적용.
- 세 가지 데이터 소스에서 모델을 사전 학습: SciEdJ(과학 교육 저널), SR1(50k+ 학생 응답), SR2(과학적 주장 응답).
- SR1의 일곱 개 과제인 7T와 SR2 과제를 이용하여 하류 작업에서 미세조정.
- 기준 BERT와 SR1-BERT, SciBERT, SciEdJ-BERT, SciEdJ-SciBERT, SR2-BERT, SR2-SciBERT 등 추가 변형을 비교하여 맥락화 효과를 평가.
- 다수의 서술형 과제에서 작업 단위 정확도 기준으로 성능 평가.
- 사전학습 데이터와 하류 작업 간 정렬을 최대화하기 위한 지속적 사전학습 체제 채택.
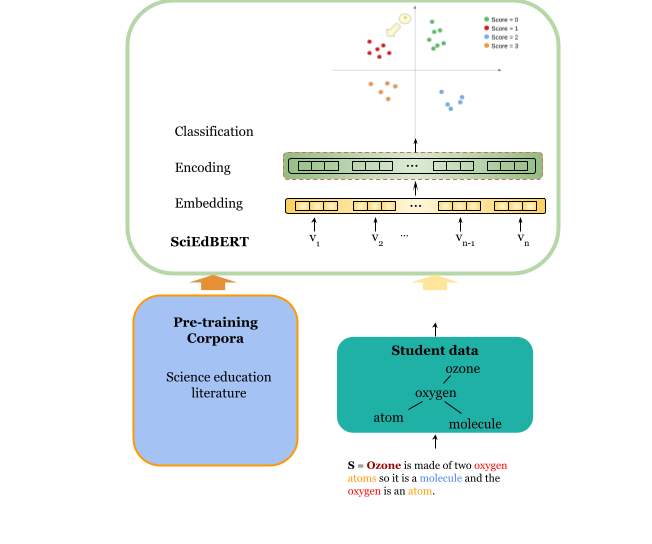
실험 결과
연구 질문
- RQ1도메인 내 지속적 사전 학습이 일반적인 BERT 기준에 비해 자동 채점 정확도를 향상시키는가?
- RQ2SciEdJ, SR1, SR2로의 맥락화가 과학 교육 채점 작업에서 모델 성능에 어떤 영향을 미치는가?
- RQ3어떤 모델 변형(BERT 대 SciBERT, 다양한 도메인 데이터)들이 서술형 응답의 최종 정확도에서 최상의 성과를 내는가?
- RQ4특정 채점 작업에 맞춘 맥락에서 미세 조정하기 전에 작업 관련 맥락에서 학습하는 것이 이점이 있는가?
주요 결과
| Table 1 - 7T task accuracies by model | Table 2 - 4T task accuracies by model | ||||
|---|---|---|---|---|---|
| H4-2 | 0.913 | 0.929 | |||
| H4-3 | 0.831 | 0.831 | |||
| H5-2 | 0.958 | 0.970 | |||
| J2-2 | 0.920 | 0.926 | |||
| J6-2 | 0.959 | 0.973 | |||
| J6-3 | 0.845 | 0.845 | |||
| R1-2 | 0.864 | 0.864 | |||
| Average | 0.904 | 0.912 | |||
| Table 2 G4 | 0.792 | 0.804 | 0.815 | 0.821 | 0.815 |
| G6 | 0.766 | 0.727 | 0.742 | 0.719 | 0.766 |
| S2 | 0.895 | 0.882 | 0.889 | 0.915 | 0.928 |
| S3 | 0.934 | 0.954 | 0.921 | 0.954 | 0.954 |
- SR1-BERT가 평균적으로 기초 BERT보다 약간 더 뛰어남(0.912 대 0.904).
- SR2-SciBERT가 4T 과제에서 가장 높은 평균 정확도(0.866)를 달성.
- SR2-BERT도 강한 성능을 보이며(평균 0.852), 여러 개별 과제에서 종종 SciEdJ 변형과 같거나 더 높은 성능을 달성.
- 하류 작업 언어(SR2)로 모델의 맥락화를 수행하는 것이 더 넓은 도메인 언어만 사용하는 것보다 작업별 성능이 더 좋음.
- SciEdJ-SciBERT와 SciEdJ-BERT는 평가된 모델 중 평균적으로 최악의 성능을 보임, 이는 과학 교육 저널의 언어가 학생 작문 언어를 혼란시킬 수 있음을 시사.
- 전반적으로 도메인 특화 데이터에 대한 지속적 사전 학습은 특히 하류 작업과의 정렬에 맞춰 수행될 때 학생의 과학 작문 자동 채점 성능을 향상시킴.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.