[논문 리뷰] Contrastive Multiview Coding
이 논문은 Contrastive Multiview Coding (CMC)을 소개합니다. 이는 서로 다른 이미지 채널 또는 뷰 간의 상호정보를 극대화하여 뷰-불변 표현을 학습하는 자기지도 방법이며, 이미지 및 비디오 벤치마크에서 최첨단 성능을 보입니다. 더 많은 뷰가 표현 품질을 개선하고, 대조 학습이 교차 뷰 예측보다 우수합니다.
Humans view the world through many sensory channels, e.g., the long-wavelength light channel, viewed by the left eye, or the high-frequency vibrations channel, heard by the right ear. Each view is noisy and incomplete, but important factors, such as physics, geometry, and semantics, tend to be shared between all views (e.g., a "dog" can be seen, heard, and felt). We investigate the classic hypothesis that a powerful representation is one that models view-invariant factors. We study this hypothesis under the framework of multiview contrastive learning, where we learn a representation that aims to maximize mutual information between different views of the same scene but is otherwise compact. Our approach scales to any number of views, and is view-agnostic. We analyze key properties of the approach that make it work, finding that the contrastive loss outperforms a popular alternative based on cross-view prediction, and that the more views we learn from, the better the resulting representation captures underlying scene semantics. Our approach achieves state-of-the-art results on image and video unsupervised learning benchmarks. Code is released at: http://github.com/HobbitLong/CMC/.
연구 동기 및 목표
- 다중 감각 뷰 간에 공유되고 의미적으로 중요한 정보를 포착하는 컴팩트한 표현 학습 동기를 제시합니다.
- 뷰 간의 상호정보를 극대화하는 확장 가능한 멀티뷰 대조 학습 프레임워크를 개발합니다.
- 뷰의 수를 늘리는 것이 표현 품질에 어떤 영향을 주는지 조사합니다.
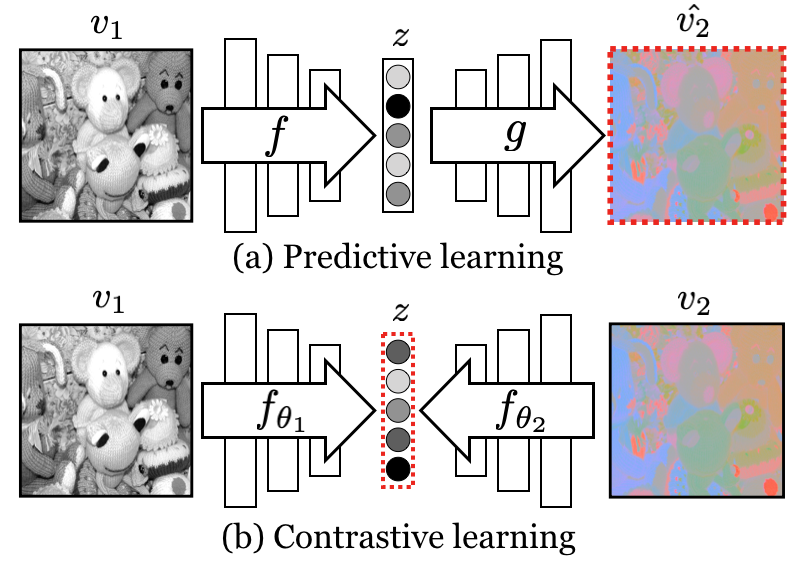
- 대조적 멀티뷰 학습을 교차 뷰 예측 및 예측 학습과 비교합니다.
- 학습된 표현의 다운스트림 인식 및 분할(Task)로의 전이 가능성을 평가합니다.
제안 방법
- 각 뷰 V1,...,VM에 대해 인코더 fi를 정의하여 잠재 표현 z_i = fi(v_i)를 생성합니다.
- 코사인 유사도에 기반한 z-벡터 간의 점수 h_theta를 통해 같은 장면의 양의 쌍(congruent views)과 서로 다른 장면의 음의 쌍을 구분하는 대조 목표를 사용합니다.
- 양방향으로 적용되고 합쳐져 L(V1,V2)을 형성하는 Two-view loss L_contrast^{V1,V2}를 적용합니다.
- 여러 뷰에 대한 핵심-뷰(core-view) 및 전체 그래프(full-graph) 형식으로 확장합니다: core-view는 j>1인 L(V1,Vj)을 합산하고; full-graph는 모든 i<j에 대해 L(Vi,Vj)을 합합니다.
- 음의 샘플링 및 메모리 뱅크: 허용 가능한 음의 샘플 수로 전체 소프트맥스 근사를 수행하고, 비교를 위한 잠재 특징을 메모리 뱅크에 저장합니다.
- 최적의 평가는 크기 비의 비율 및 상호정보와 관련되며, I(z1;z2) ≥ log(k) − L_contrast 이다. 여기서 k는 음의 샘플 수입니다.
- 대조 학습이 다양한 뷰 간 예측(재구성) 학습보다 공유 정보를 더 잘 포착한다는 경험적 비교를 제공합니다.
- 이미지에 적용(예: Lab L 대 ab 채널; Y 대 DbDr) 및 비디오(RGB 프레임과 옵티컬 플로우)로 확장하고 NYU-Depth-V2에서는 더 많은 뷰(L, ab, depth, surface normals)로 확장합니다.
- 데이터 증강과 함께 공유 대조 목표를 가진 두 인코더 구조, 필요시 메모리 뱅크를 활용하며, 선형 프로브 및 분할형 태스크를 통한 전이 평가를 수행합니다.
![Figure 1 : Given a set of sensory views, a deep representation is learnt by bringing views of the same scene together in embedding space, while pushing views of different scenes apart. Here we show and example of a 4-view dataset (NYU RGBD [ 53 ] ) and its learned representation. The encodings for e](https://ar5iv.labs.arxiv.org/html/1906.05849/assets/x1.png)
실험 결과
연구 질문
- RQ1대조적 멀티뷰 학습이 여러 이미지 채널 간에 뷰-불변이며 의미적으로 유의미한 표현을 학습할 수 있는가?
- RQ2뷰의 수를 늘리면 다운스트림 작업을 위한 학습 표현의 품질이 향상되는가?
- RQ3멀티뷰 표현 학습에서 대조 목표가 교차 뷰 예측 혹은 예측 학습보다 우수한가?
- RQ4핵심-뷰(core-view) 및 전체 그래프(full-graph) 멀티뷰 형태는 효율성과 정보 포착 간에 어떤 트레이드를 보이는가?
- RQ5CMC 표현이 이미지 분류, 비디오 인식 및 분할 작업으로의 전이에 얼마나 잘 수행되는가?
주요 결과
- CMC는 이미지 및 비디오 벤치마크에서 강한 비지도 성능을 달성하며 일부 환경에서 최첨단에 근접합니다.
- 뷰의 수가 증가할수록 표현 품질이 향상됩니다(예: NYU-Depth-V2 실험 전반에 걸쳐).
- 대조적 목표는 여러 뷰 조합 및 데이터세트에서 교차 뷰 예측 및 예측 학습보다 우수한 성능을 보입니다.
- 전체 그래프 멀티뷰 형식은 모든 뷰에서 강건한 표현을 제공하며 일부 작업에서 지도 학습 성능에 접근할 수 있습니다.
- ImageNet에서 L,ab와 같은 밝기-색상 공간 분할이나 다른 색 공간 분할을 사용하는 두-뷰 CMC가 경쟁력 있는 top-1/top-5 정확도를 보이며, 모델 폭을 늘리고 추가 뷰를 사용할수록 결과가 더 향상됩니다.
- 비디오 작업에서 RGB 프레임과 옵티컬 플로우를 사용하는 CMC는 여러 baselines를 능가하고 행동 인식 데이터셋으로의 전이를 향상시킵니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.