[논문 리뷰] Conversational AI Powered by Large Language Models Amplifies False Memories in Witness Interviews
생성형 챗봇 상호작용은 설문 기반 또는 사전 스크립트된 챗봇에 비해 즉각적인 잘못된 기억과 자신감을 크게 증가시키며, 효과가 일주일 후에도 지속된다.
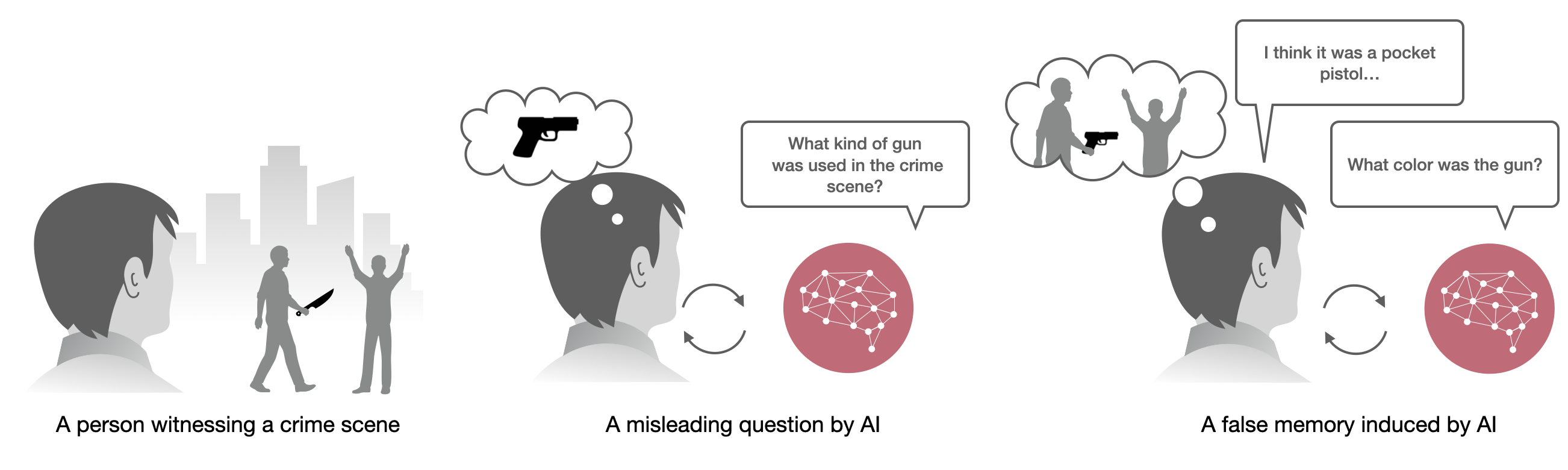
This study examines the impact of AI on human false memories -- recollections of events that did not occur or deviate from actual occurrences. It explores false memory induction through suggestive questioning in Human-AI interactions, simulating crime witness interviews. Four conditions were tested: control, survey-based, pre-scripted chatbot, and generative chatbot using a large language model (LLM). Participants (N=200) watched a crime video, then interacted with their assigned AI interviewer or survey, answering questions including five misleading ones. False memories were assessed immediately and after one week. Results show the generative chatbot condition significantly increased false memory formation, inducing over 3 times more immediate false memories than the control and 1.7 times more than the survey method. 36.4% of users' responses to the generative chatbot were misled through the interaction. After one week, the number of false memories induced by generative chatbots remained constant. However, confidence in these false memories remained higher than the control after one week. Moderating factors were explored: users who were less familiar with chatbots but more familiar with AI technology, and more interested in crime investigations, were more susceptible to false memories. These findings highlight the potential risks of using advanced AI in sensitive contexts, like police interviews, emphasizing the need for ethical considerations.
연구 동기 및 목표
- AI 매개 질문이 목격자와 같은 상황에서 잘못된 기억 형성에 어떤 영향을 미치는지 조사한다.
- 네 가지 상호작용 방식(제어, 설문 기반, 사전 스크립트 챗봇, 생성형 챗봇)을 잘못된 기억에 대해 비교한다.
- 유도된 잘못된 기억의 즉각적 및 일주일 간 지속성과 자신감을 검토한다.
- AI로 유도된 잘못된 기억에 대한 민감성에 영향을 미치는 개인 요인을 식별한다.
제안 방법
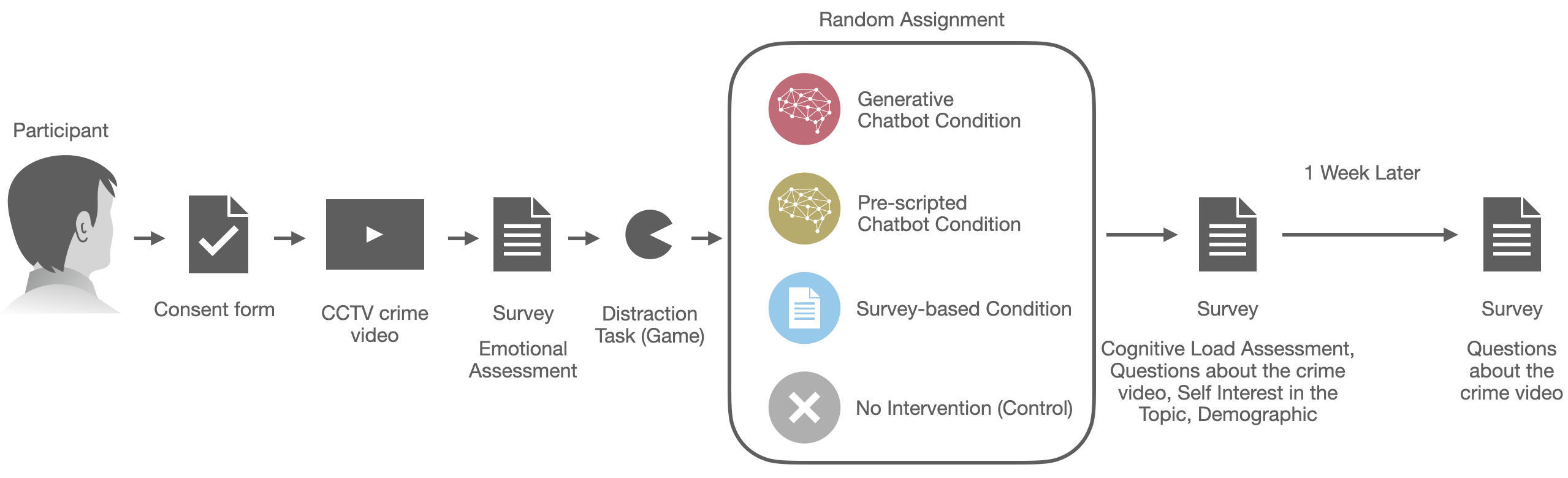
- 네 가지 조건에 무작위로 배정된 200명의 참가자를 대상으로 한 두 단계 실험.
- 참가자는 범죄 영상을 시청한 뒤, 다섯 개의 오해를 불러일으키는 문제를 포함한 25문항에 답한다.
- 1단계는 제어, 설문 기반, 사전 스크립트 챗봇, 또는 생성형 챗봇 조건을 사용한다.
- 1주일 후 2단계에서 기억과 자신감을 재평가하여 지속성을 측정한다.
- 즉각적 및 일주일 기억 회상을 통해 잘못된 기억을 정량화하고, 잘못된 기억과 진실 기억에 대한 자신감을 측정한다.
실험 결과
연구 질문
- RQ1서로 다른 AI 상호작용 모드가 목격자 유사 인터뷰 설정에서 잘못된 기억 형성에 어떤 영향을 미치는가?
- RQ2생성형 챗봇이 설문 기반 또는 사전 스크립트 챗봇보다 잘못된 기억 유도에 더 효과적인가?
- RQ3AI로 유도된 잘못된 기억에 대한 민감성에 영향을 미치는 사용자의 조절 요인은 무엇인가?
- RQ4AI로 유도된 잘못된 기억이 일주일 동안 지속되는가, 그리고 시간이 지나며 자신감은 어떻게 변하는가?
주요 결과
- 생성형 챗봇은 설문 기반 및 사전 스크립트 챗봇 조건보다 더 많은 즉각적인 잘못된 기억을 유도했다(평균 수: 제어 0.54, 설문 1.08, 사전 스크립트 1.34, 생성형 1.82).
- 생성형 챗봇 조건에서의 응답 중 36.4%가 즉시 오도되었다.
- 모든 중재는 제어 대비 즉각적 잘못된 기억과 자신감을 증가시켰으며, 생성형 챗봇이 잘못된 기억의 가장 높은 자신감을 유도했다.
- 일주일 후 생성형 챗봇의 잘못된 기억은 대략 일정하게 유지되었으며(즉각 36.4% 대 36.8%), 제어와 설문은 잘못된 기억이 증가했다.
- 조절 요인: 챗봇에 대한 낮은 친숙도와 높은 AI 기술 친숙도, 더 큰 범죄 수사 관심이 AI로 유도된 잘못된 기억에 대한 민감도 증가.
- 생성형 챗봇으로 유도된 잘못된 기억은 제어 및 사전 스크립트 조건보다 장기 자신감이 더 높았다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.