[논문 리뷰] Convolutional State Space Models for Long-Range Spatiotemporal Modeling
ConvSSMs와 ConvS5를 소개하는 컨볼루션 상태공간 접근법으로, 병렬화된 장기 시공-시간 모델링을 가능하게 하는 선형-시간 per-step 추론과 빠른 자기회귀 생성을 제공하며, 장기-수평 태스크에서 Transformer와 ConvLSTM보다 우수하게 작동한다.
Effectively modeling long spatiotemporal sequences is challenging due to the need to model complex spatial correlations and long-range temporal dependencies simultaneously. ConvLSTMs attempt to address this by updating tensor-valued states with recurrent neural networks, but their sequential computation makes them slow to train. In contrast, Transformers can process an entire spatiotemporal sequence, compressed into tokens, in parallel. However, the cost of attention scales quadratically in length, limiting their scalability to longer sequences. Here, we address the challenges of prior methods and introduce convolutional state space models (ConvSSM) that combine the tensor modeling ideas of ConvLSTM with the long sequence modeling approaches of state space methods such as S4 and S5. First, we demonstrate how parallel scans can be applied to convolutional recurrences to achieve subquadratic parallelization and fast autoregressive generation. We then establish an equivalence between the dynamics of ConvSSMs and SSMs, which motivates parameterization and initialization strategies for modeling long-range dependencies. The result is ConvS5, an efficient ConvSSM variant for long-range spatiotemporal modeling. ConvS5 significantly outperforms Transformers and ConvLSTM on a long horizon Moving-MNIST experiment while training 3X faster than ConvLSTM and generating samples 400X faster than Transformers. In addition, ConvS5 matches or exceeds the performance of state-of-the-art methods on challenging DMLab, Minecraft and Habitat prediction benchmarks and enables new directions for modeling long spatiotemporal sequences.
연구 동기 및 목표
- Local spatial structure와 긴 시간 의존성을 포착하는 장기 시공-시간 시퀀스의 확장 가능한 모델링 필요성에 대한 동기 부여.
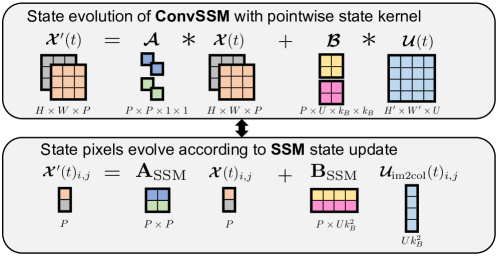
- 텐서 상태와 선형 연속-시간 다이내믹스를 결합한 ConvSSMs를 개발하여 효율적인 병렬화를 가능하게 한다.
- 병렬 스캔과 SSM에서 영감을 받은 초기화를 통해 장기 의존성을 모델링하는 ConvSS5라는 효율적인 ConvSSM 변형을 제안한다.
- 장기의 벤치마크와 데이터셋에서 Transformer와 ConvLSTM 대비 실험적 성능 향상을 입증한다.
제안 방법
- 텐서-값 상태와 선형 컨볼루셔널 다이내믹스를 갖는 합성곱 상태 공간 모델(ConvSSMs)을 정의한다.
- 시퀀스 전체에서 ConvSSM 재귀를 이진 연관 연산자와 병렬 스캔을 이용해 병렬화하는 방법을 보여준다.
- ConvSSMs와 상태-공간 모델(SSMs) 간의 동등성을 확립하여 HiPPO에서 영감을 받은 초기화와 이산화의 이점을 활용한다.
- 대각화된 SSM 유사 다이내믹스로 ConvSSMs를 매개변수화하고 효율적인 장기 모델링을 위해 병렬 스캔을 적용해 ConvS5를 제안한다.
- 다층의 ConvS5를 비선형 활성화로 쌓아 비선형 시공-시간 다이내믹스를 포착하되 학습 가능성을 유지한다.
- 장기-수평 Moving-MNIST, DMLab, Minecraft, Habitat 벤치마크에서 빠른 자기회귀 생성을 제공하는 실증 근거를 제시한다.
![Figure 1 : ConvRNNs [ 17 , 18 ] (left) model spatiotemporal sequences using tensor-valued states, $\mathbfcal{X}_{k}$ , and a nonlinear RNN update, $\mathbf{G}()$ , that uses convolutions instead of matrix-vector multiplications. A position-wise nonlinear function, $\mathbf{h}()$ , transforms the st](https://ar5iv.labs.arxiv.org/html/2310.19694/assets/x1.png)
실험 결과
연구 질문
- RQ1ConvSSMs가 장기 시공-시간 시퀀스에 대해 서브제곱적 병렬 학습 및 추론을 제공할 수 있는가?
- RQ2ConvSSMs를 어떻게 매개변수화하고 초기화하여 장기 의존성을 효과적으로 포착할 수 있는가?
- RQ3ConvS5가 장기-수평 비디오 예측 벤치마크에서 Transformer 및 ConvLSTM Baseline보다 우수한가?
- RQ4ConvS5의 계산 상 트레이드오프(속도, 메모리)는 Transformer 및 ConvRNN과 비교해 어떤가?
- RQ5ConvS5가 DMLab, Minecraft, Habitat 같은 복잡한 3D 환경 벤치마크로 확장되면서 품질을 유지할 수 있는가?
주요 결과
- ConvS5는 서브제곱 복잡도로 병렬 시퀀스 처리를 가능하게 하고 자기회귀 생성이 빠르다.
- ConvS5는 Moving-MNIST의 장기-수평에서 ConvLSTM보다 빠르게 학습하고 샘플 생성이 Transformer보다 훨씬 빠르다.
- ConvS5는 DMLab, Minecraft, Habitat의 장기-범위 비디오 예측 벤치마크에서 최첨단에 근접하거나 이를 상회한다.
- ConvS5는 SSM에서 영감을 받은 매개변수화와 HiPPO 기반 초기화가 결합된 ConvSSM 구조의 이점을 누린다.
- 프레이밍된 프레임의 토큰 기반 압축에 의존하지 않고도 강력한 성능을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.