[논문 리뷰] CulturaX: A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages
tldr: CulturaX는 공개적으로 출시된, 6.3-trillion-token 다국어 데이터셋으로 167개 언어에 걸쳐 있으며 고품질 LLMs 훈련을 위해 광범위하게 정리되고 중복 제거되었습니다. 그것은 mC4 v3.1.0와 OSCAR 코퍼스를 엄격한 정리/중복 제거 파이프라인과 결합하며 HuggingFace에서 이용 가능합니다.
The driving factors behind the development of large language models (LLMs) with impressive learning capabilities are their colossal model sizes and extensive training datasets. Along with the progress in natural language processing, LLMs have been frequently made accessible to the public to foster deeper investigation and applications. However, when it comes to training datasets for these LLMs, especially the recent state-of-the-art models, they are often not fully disclosed. Creating training data for high-performing LLMs involves extensive cleaning and deduplication to ensure the necessary level of quality. The lack of transparency for training data has thus hampered research on attributing and addressing hallucination and bias issues in LLMs, hindering replication efforts and further advancements in the community. These challenges become even more pronounced in multilingual learning scenarios, where the available multilingual text datasets are often inadequately collected and cleaned. Consequently, there is a lack of open-source and readily usable dataset to effectively train LLMs in multiple languages. To overcome this issue, we present CulturaX, a substantial multilingual dataset with 6.3 trillion tokens in 167 languages, tailored for LLM development. Our dataset undergoes meticulous cleaning and deduplication through a rigorous pipeline of multiple stages to accomplish the best quality for model training, including language identification, URL-based filtering, metric-based cleaning, document refinement, and data deduplication. CulturaX is fully released to the public in HuggingFace to facilitate research and advancements in multilingual LLMs: https://huggingface.co/datasets/uonlp/CulturaX.
연구 동기 및 목표
- 대규모의 개방형 다국어 데이터셋을 제공함으로써 LLM 학습 데이터의 투명성 및 민주화를 촉진한다.
- 다국어 자원(mC4 및 OSCAR)을 통합하고 업데이트하여 영어를 넘는 언어 커버리지를 극대화한다.
- 언어 간 고품질 학습 데이터를 보장하기 위해 엄격한 정리 및 중복 제거를 적용한다.
- 167개 언어에 걸친 즉시 사용 가능한 데이터를 통해 다국어 LLM 연구 및 개발을 가능하게 한다.
제안 방법
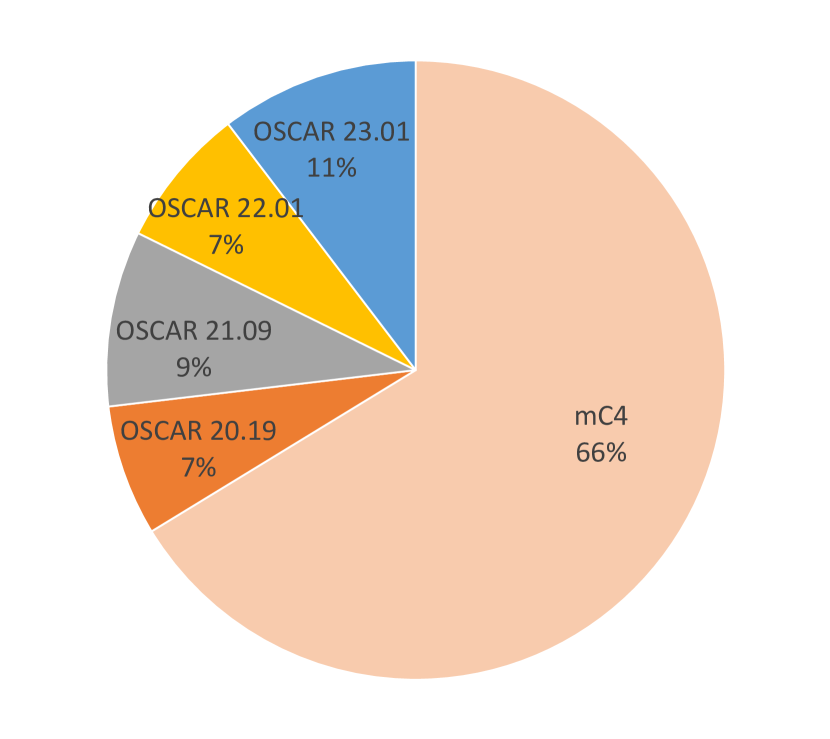
- 최신 mC4 (v3.1.0)와 OSCAR 코퍼스를 2023.01 분포까지 결합한다.
- 언어 식별 재예측, URL 기반 필터링, 메트릭 기반 정리, 문서 정제를 포함하는 다단계 데이터 정리 파이프라인을 적용한다.
- 필터링 임계값을 결정하기 위해 Interquartile Range(IQR)의 변형을 사용하여 언어별 임계값을 설정한다.
- 언어별로 MinHashLSH를 사용한 문서 수준 중복 제거 및 URL 기반 중복 제거를 실행한다.
- 사전처리 및 중복 제거를 위해 상당한 계산 자원(600 AWS EC2 인스턴스)을 활용한다.
- 향후 연구를 돕기 위해 KenLM 모델을 공개한다.
실험 결과
연구 질문
- RQ1CulturaX는 167개 언어에 걸친 고품질 LLM 학습에 적합한 확장 가능하고 다국어이며 공개적으로 접근 가능한 데이터세트를 제공할 수 있는가?
- RQ2제안된 정리 및 중복 제거 파이프라인(언어 재예측, URL 필터링, 메트릭 기반 필터링, 문서 정제, MinHash 기반 중복 제거)이 이전의 공개 데이터 세트에 비해 상당히 더 높은 품질의 다국어 말뭉치를 산출하는가?
- RQ3mC4 v3.1.0와 OSCAR를 결합하고 엄격한 다국어 정리를 적용함으로써 달성된 언어 커버리지, 규모, 품질 간의 트레이드오프는 무엇인가?
주요 결과
- CulturaX는 167개 언어에 걸쳐 6.3 trillion tokens를 포함하고 있어 LLM 학습을 위한 대규모 다국어 자원이다.
- 초기 문서의 46% 이상이 정리/중복 제거 파이프라인을 통해 제거되어 품질 향상이 크게 나타난다.
- 데이터셋은 비영어 콘텐츠를 중시하며 다국어 학습을 지원하기 위해 비영어 언어에 데이터의 절반 이상이 할당된다.
- 문서 수준 중복 제거를 위한 MinHashLSH 및 URL 기반 중복 제거는 학습 데이터의 중복성과 암기 위험을 감소시킨다.
- 언어 식별 재예측(FastText over cld3)을 사용하여 언어 라벨링 정확도와 데이터 품질을 향상시킨다.
- HuggingFace에서의 공개 가용성은 재현성과 다국어 NLP 연구에서의 광범위한 활용을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.