[논문 리뷰] CvT: Introducing Convolutions to Vision Transformers
CvT는 컨볼루션을 비전 트랜스포머에 통합하여 계층적이고 컨볼루션 강화된 트랜스포머를 만들어 더 적은 파라미터와 FLOPs로 ImageNet에서 최첨단 성능을 달성하고 위치 임베딩 없이도 가능하다.
We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs) to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention, global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition, performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding, a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks. Code will be released at \url{https://github.com/leoxiaobin/CvT}.
연구 동기 및 목표
- 이미지 인식에서 로컬 및 글로벌 컨텍스트를 활용하기 위해 CNN과 트랜스포머의 결합을 제안한다.
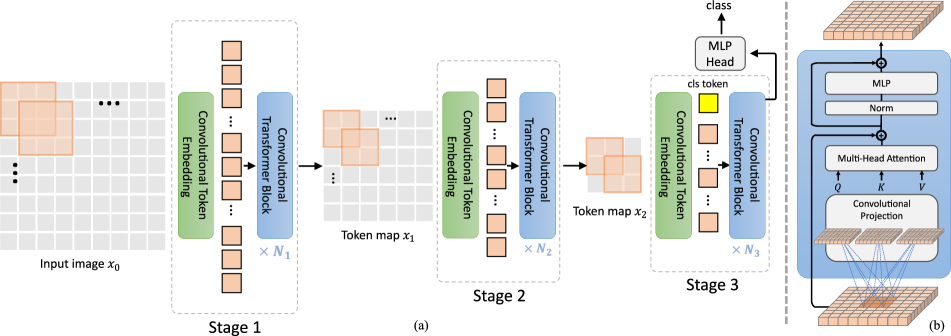
- 계층적 트랜스포머 프레임워크 내에서 컨볼루션 토큰 임베딩과 컨볼루션 프로젝션의 두 가지 핵심 변화를 도입하는 CvT를 제안한다.
- ImageNet-1k 및 ImageNet-22k에서 ViT/DeiT 대비 향상된 정확도와 효율성을 보이고, 경쟁적인 CNN과도 비교 우위를 입증한다.
- 위치 인코딩을 제거해도 성능 저하 없이, 가변 입력 해상도를 가능하게 한다.
제안 방법
- 토큰 길이를 점차 줄이면서 특징 차원을 증가시키기 위해 컨볼루션 토큰 임베딩을 사용하는 3단계 계층적 CvT 백본을 도입한다.
- 주목 입력 프로젝션을 깊이별 분리 가능한 컨볼루션을 기반으로 한 컨볼루션 프로젝션으로 교체하여 로컬 컨텍스트를 모델링하고 토큰 하위 샘플링을 가능하게 한다.
- 컨볼루션 토큰 임베딩 이후 층 정규화를 수행하고 분류를 위해 최종 단계에서 표준 MLP 헤드를 적용한다.
- 컨볼루션으로부터 내재된 로컬 컨텍스트로 인해 위치 임베딩을 제거해도 성능 저하가 없음을 입증한다.
![Figure 1 : Top-1 Accuracy on ImageNet validation compared to other methods with respect to model parameters. (a) Comparison to CNN-based model BiT [ 18 ] and Transformer-based model ViT [ 11 ] , when pretrained on ImageNet-22k. Larger marker size indicates larger architectures. (b) Comparison to con](https://ar5iv.labs.arxiv.org/html/2103.15808/assets/x1.png)
실험 결과
연구 질문
- RQ1비전 트랜스포머에 컨볼루션을 도입하면 대규모 이미지 분류에서 정확도와 효율성이 향상되는가?
- RQ2컨볼루션 토큰 임베딩과 컨볼루션 프로젝션을 갖춘 계층적 다단계 CvT 아키텍처가 ViT/DeiT 및 CNN보다 우수한 성능을 보일 수 있는가?
- RQ3로컬 컨텍스트가 컨볼루션으로 포착될 때 명시적 위치 임베딩을 제거해도 성능 저하가 없는가?
- RQ4CvT 모델은 데이터 세트 크기에서 어떻게 확장되며 다운스트림 태스크로의 일반화에 어떻게 영향을 미치는가?
주요 결과
| 방법 유형 | 네트워크 | #Param (M) | 이미지 크기 | FLOPs (G) | ImageNet top-1 (%) | Real (%) | V2 (%) |
|---|---|---|---|---|---|---|---|
| Convolutional Transformers (Ours) | CvT-13 | 20 | 224^2 | 4.5 | 81.6 | 86.7 | 70.4 |
| Convolutional Transformers (Ours) | CvT-21 | 32 | 224^2 | 7.1 | 82.5 | 87.2 | 71.3 |
| Convolutional Transformers (Ours) | CvT-13↑384 | 20 | 384^2 | 16.3 | 83.0 | 87.9 | 71.9 |
| Convolutional Transformers (Ours) | CvT-21↑384 | 32 | 384^2 | 24.9 | 83.3 | 87.7 | 71.9 |
| Convolutional Transformers (Ours) | CvT-13-NAS | 18 | 224^2 | 4.1 | 82.2 | 87.5 | 71.3 |
| Convolutional Transformers (Ours) | CvT-W24↑384 | 277 | 384^2 | 193.2 | 87.7 | 90.6 | 78.8 |
- ImageNet-1k에서 CvT-21은 82.5% top-1, 7.1G FLOPs 및 32M 파라미터로 DeiT-B보다 더 적은 FLOPs/파라미터로 우수한 성능을 달성한다.
- CvT-13은 4.5G FLOPs 및 20M 파라미터로 81.6% top-1을 달성하여 여러 CNN/트랜스포머 베이스라인보다 효율성에서 우위를 보인다.
- ImageNet-22k에서 사전학습된 CvT-W24는 ImageNet-1k에서 87.7% top-1에 도달하고 CIFAR, PETS, Flowers에서 강한 전이 성능을 유지한다.
- CvT에서 위치 임베딩 제거가 성능에 영향을 주지 않음을 보여주며, 컨볼루션 구성 요소가 충분한 공간 편향을 제공함을 강조한다.
- NAS에서 영감을 받은 변형(CvT-13-NAS)은 파라미터가 더 적은데도 비슷한 정확도를 달성할 수 있어 아키텍처 탐색의 여지가 있음을 시사한다.
- CvT는 해상도 전반에서 강력한 성능을 보이며, (예: 384^2) 유사하거나 더 낮은 FLOPs에서 다른 트랜스포머들과 비교해 경쟁력 있는 또는 우수한 정확도를 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.