[논문 리뷰] D4: Improving LLM Pretraining via Document De-Duplication and Diversification
이 논문은 SemDeDup 중복 제거와 클러스터링 기반 다변화를 결합한 데이터 선택 방법 D4를 소개하여 LLM 사전 학습 효율성과 다운스트림 정확도를 향상시키고, 최대 67억 매개변수 모델까지의 다양한 규모에서 이점이 있음을 보여준다.
Over recent years, an increasing amount of compute and data has been poured into training large language models (LLMs), usually by doing one-pass learning on as many tokens as possible randomly selected from large-scale web corpora. While training on ever-larger portions of the internet leads to consistent performance improvements, the size of these improvements diminishes with scale, and there has been little work exploring the effect of data selection on pre-training and downstream performance beyond simple de-duplication methods such as MinHash. Here, we show that careful data selection (on top of de-duplicated data) via pre-trained model embeddings can speed up training (20% efficiency gains) and improves average downstream accuracy on 16 NLP tasks (up to 2%) at the 6.7B model scale. Furthermore, we show that repeating data intelligently consistently outperforms baseline training (while repeating random data performs worse than baseline training). Our results indicate that clever data selection can significantly improve LLM pre-training, calls into question the common practice of training for a single epoch on as much data as possible, and demonstrates a path to keep improving our models past the limits of randomly sampling web data.
연구 동기 및 목표
- LLM 사전 학습에서 단순한 중복 제거를 넘어 데이터 선택의 동기를 제시하고 효율성과 성능을 향상시킨다.
- 중복 대상 클러스터링을 줄이고 학습 데이터를 다양화하기 위한 임베딩 기반 전략을 조사한다.
- 고정된 계산 예산과 데이터 제한 환경에서 여러 모델 규모에서 효율성과 성능 향상을 정량화한다.
- 가장 큰 데이터셋으로 단일 에폭 학습이 항상 최적이라는 관념에 도전한다.
제안 방법
- 문서를 125M 매개변수 모델을 사용해 마지막 토큰 임베딩을 얻는다.
- 임베딩 공간에서 근접 중복을 제거하기 위해 SemDeDup를 적용한다.
- Deduplicated 데이터를 K-평균으로 클러스터링하고 SSL 프로토타입을 적용해 다양한 샘플을 선택한다.
- Deduplication과 다변화를 결합하고 전체 선택 비율 R = R_dedup * R_proto를 제안한다.
- 1.3B 및 6.7B 매개변수 OPT 모델을 40B–100B 토큰으로 학습시키며 고정된 계산 및 데이터 제한 환경에서 평가한다.
- 16개 NLP 태스크 및 perplexity 지표에 걸쳐 효율성 증가 및 다운스트림 성능을 계산한다.
실험 결과
연구 질문
- RQ1임베딩 기반 데이터 선택(SemDeDup 및 다변화)이 LLM의 랜덤 샘플링과 단순 중복 제거에 비해 사전 학습 효율성을 향상시키는가?
- RQ2중복 제거 후 클러스터링 기반 다양화의 2단계 선택이 중복으로 인한 클러스터링 문제를 완화하고 perplexity 및 다운스트림 정확도를 향상시키는가?
- RQ3고정된 계산과 데이터 제한 환경에서 모델 크기와 토큰 예산에 따라 데이터 선택의 이익이 어떻게 확장되는가?
- RQ4웹 스냅샷 여부가 있는 검증 세트와 비웹 스냅샷 검증 세트 간의 데이터 선택의 트레이드오프는 무엇인가?
주요 결과
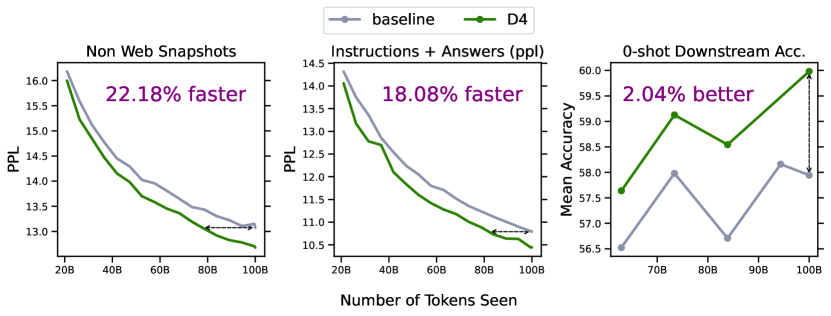
| S | T_total | T_selected | Epochs | Non-Web Snapshot PPL | Instruction + Answers PPL |
|---|---|---|---|---|---|
| Random | 40B | 40B | 1 | 16.27±0.012 | 14.19±0.003 |
| 40B | 20B | 2 | 16.39±0.011 | 14.37±0.015 | |
| D4 | 40B | 20B | 2 | 16.10±0.024 | 13.85±0.016 |
- D4는 6.7B 규모에서 perplexity에서 약 18-20%의 효율 이득과 다운스트림 정확도에서 평균 약 2% 향상을 보여준다.
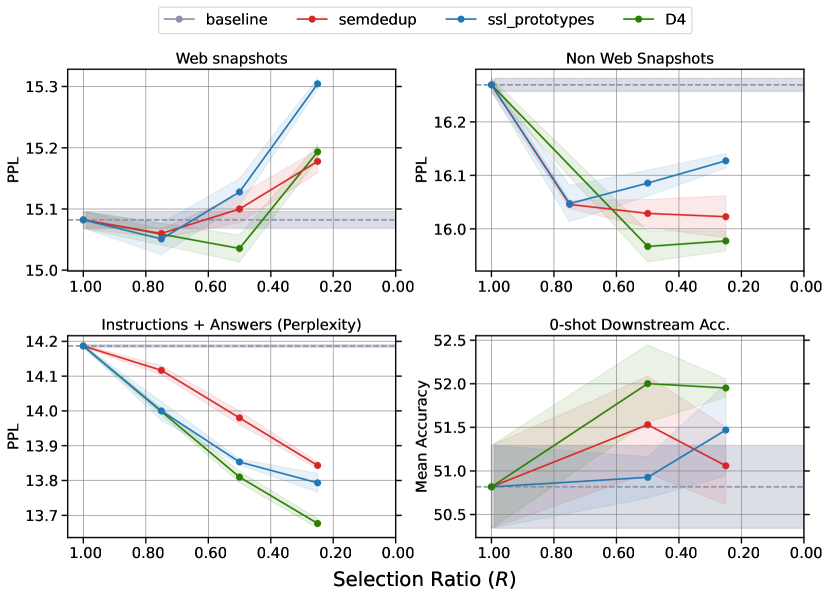
- D4는 실험된 설정에서 SemDeDup 또는 SSL 프로토타입만 사용하는 것보다 우수하다.
- 고정 데이터 regime에서 D4를 통해 선택적으로 다시 학습한 데이터는 새로운 임의 데이터 토큰으로 학습하는 것보다 더 나은 성능을 낼 수 있다.
- 고정 계산 시나리오에서 더 큰 중복 제거 및 다변화된 하위집합을 학습하면 업데이트를 20% 줄여도 동등한 perplexity를 달성할 수 있다.
- SemDeDup와 SSL 프로토타입 사이에서 재클러스터링은 중복 주도 클러스터를 줄이고 성능을 향상시키는 데 필수적이다.
- 비용 분석에 따르면 D4의 전반적 효율성 이득은 모델 크기가 커질수록 증가하며 더 큰 모델에서 약 20–22%까지 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.