[논문 리뷰] Data Decisions and Theoretical Implications when Adversarially Learning Fair Representations
본 논문은 inference 시 민감 속성에 접근할 수 없거나 학습 중 라벨링이 어려운 경우에도 공정한 잠재 표현을 학습하기 위해 적대적 학습(adversarial training)을 사용하며, 적대적 데이터 분포가 공정성 정의를 어떻게 형성하는지와 작고 균형 잡힌 적대적 데이터셋이 정확도와의 트레이드오프를 감수하면서도 공정성을 의미 있게 향상시킬 수 있음을 보여준다.
How can we learn a classifier that is "fair" for a protected or sensitive group, when we do not know if the input to the classifier belongs to the protected group? How can we train such a classifier when data on the protected group is difficult to attain? In many settings, finding out the sensitive input attribute can be prohibitively expensive even during model training, and sometimes impossible during model serving. For example, in recommender systems, if we want to predict if a user will click on a given recommendation, we often do not know many attributes of the user, e.g., race or age, and many attributes of the content are hard to determine, e.g., the language or topic. Thus, it is not feasible to use a different classifier calibrated based on knowledge of the sensitive attribute. Here, we use an adversarial training procedure to remove information about the sensitive attribute from the latent representation learned by a neural network. In particular, we study how the choice of data for the adversarial training effects the resulting fairness properties. We find two interesting results: a small amount of data is needed to train these adversarial models, and the data distribution empirically drives the adversary's notion of fairness.
연구 동기 및 목표
- 추론 시 민감 속성을 사용할 수 없거나 학습 중 라벨링이 어려운 상황에서 공정한 예측을 학습하도록 동기를 부여한다.
- 공정성 정의를 적대적 목표를 위한 데이터 분포와 연결한다.
- 얼마나 많은 적대적 데이터가 필요한지와 그 분포가 공정성 결과에 어떤 영향을 주는지 실험적으로 평가한다.
- 다양한 적대적 데이터 체계에서 모델의 정확도와 공정성 간의 트레이드를 보여준다.
제안 방법
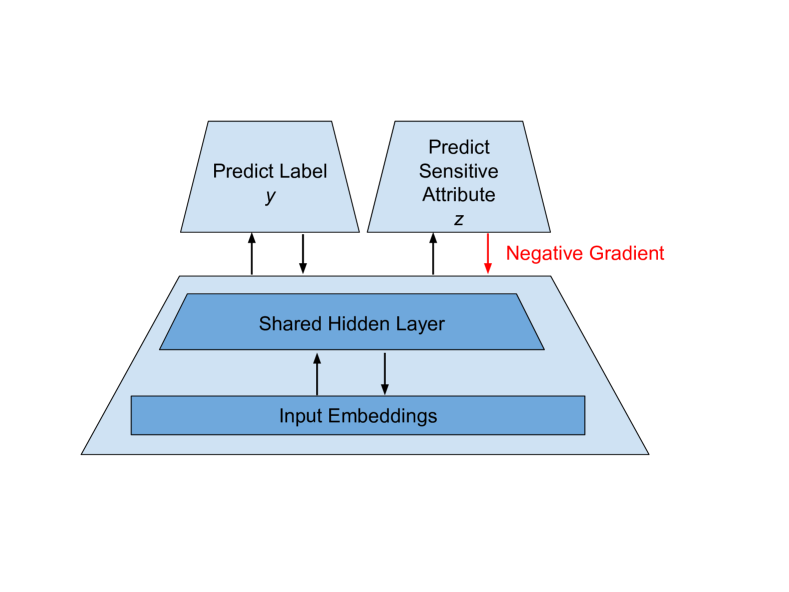
- Y를 예측하는 하나의 헤드와 잠재 표현 g(X)로부터 민감 속성 Z를 예측하려는 적대자(adversary)를 포함하는 다중 헤드 신경망을 제안한다.
- g(X)가 Z에 대한 정보를 숨기도록 하지만 Y를 여전히 잘 예측하도록 J_람다(J_lambda)의 부정 기울기 트릭을 도입한다.
- 적대자가 사용하는 데이터 세트 S와 Y, Z에 걸친 분포가 결과적 공정성에 어떤 영향을 주는지 분석한다.
- 다양한 크기와 분포를 가진 S를 실험하여 공정성 지표와 정확도에 미치는 영향을 연구한다.
실험 결과
연구 질문
- RQ1적대적 훈련 데이터 S의 선택과 분포가 모델의 결과 공정성에 어떤 영향을 미치는가?
- RQ2적대적 훈련에서 민감 속성 Z의 균형 잡힌 분포와 비균형 분포가 공정성과 정확성에 어떤 영향을 주는가?
- RQ3얼마나 많은 적대적 데이터가 공정성을 의미 있게 향상시키되 정확도의 손실을 너무 크게 초래하지 않는가?
- RQ4주요 라벨 Y(수입)에 대한 서로 다른 분포가 학습된 표현의 기회 평등과 인구 통계적 평등에 어떤 영향을 주는가?
주요 결과
| 남성 | 여성 |
|---|---|
| 15128 | 9592 |
| 6662 | 1179 |
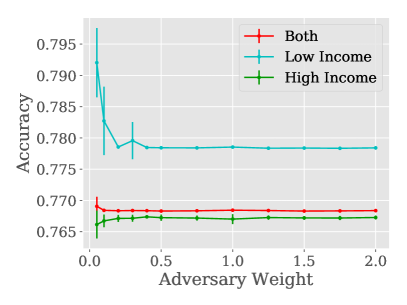
- 균형 잡힌 적대적 데이터는 공정성 지표를 크게 개선하고 학습을 안정화하지만 정확도에는 다소 비용이 든다.
- 높은 소득 또는 낮은 소득 그룹과 일치하는 적대적 데이터 분포는 해당 그룹의 기회 평등에 특화된 향상을 가져오고, 그룹을 혼합하면 여러 지표에 걸쳐 공정성을 향상시킨다.
- 아주 작은 적대적 데이터셋(예: 500개의 예시)으로도 의미 있는 공정성 향상을 얻을 수 있다.
- 적대적 데이터의 주요 라벨 Y 분포는 공정성 정의와 일치하는 서로 다른 공정성 결과를 야기하며, 데이터 선택이 정의에 영향을 미친다는 이론적 기대와 일관된다.
- 적대적 학습에서 Z의 균형 잡힌 분포는 일반적으로 무작위 표본 추출보다 더 강한 공정성 효과를 낳는다.
- 강한 공정성(격차 감소)과 예측 정확도 사이에는 트레이드오프가 있으며, 람다(lambda) 튜닝이 이 균형을 매개한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.