[논문 리뷰] DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
DatasetDM은 확산 모델의 잠재 코드를 통해 픽셀 단위 주석을 추출하는 지각 디코더를 사용하는 텍스트-데이터 패러다임으로, 디코더 학습에 필요한 실제 이미지가 약 100장에 불과한 상태에서 무한한 합성 라벨 데이터를 가능하게 합니다.
Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing). The project website and code can be found at https://weijiawu.github.io/DatasetDM_page/ and https://github.com/showlab/DatasetDM, respectively
연구 동기 및 목표
- 대규모 라벨링 데이터의 필요성을 자극하고 지각 태스크에서 라벨링 비용을 줄인다.
- 다중 태스크에 걸쳐 확산 잠재 코드를 지각 주석으로 디코딩하는 일반 프레임워크를 제안한다.
- 확산 역변환과 통합된 P-Decoder를 활용하여 다양한 데이터셋에 대해 텍스틀 가이드 데이터 생성을 가능하게 한다.
- 합성 데이터가 세그멘테이션, 깊이, 포즈 태스크에서 최첨단 혹은 경쟁력 있는 결과를 달성할 수 있음을 시연한다.
제안 방법
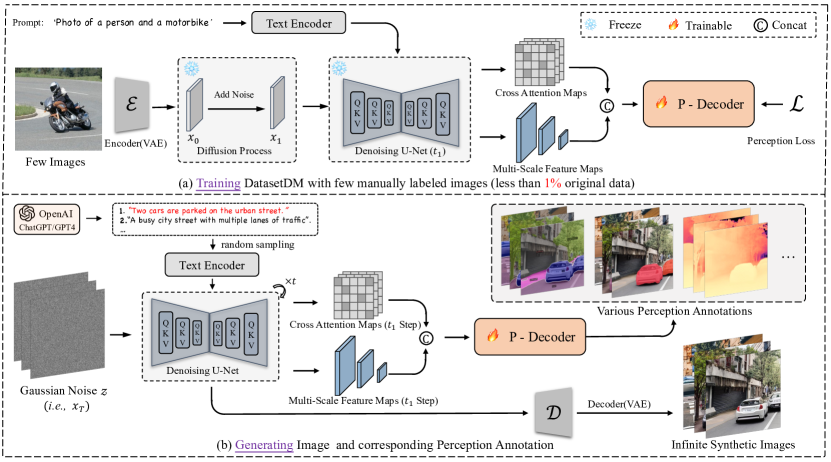
- 실제 이미지에서 잠재 코드를 추출하고 다중 스케일 확산 특징과 교차 주의 맵을 융합하여 하이컬럼 표현을 형성한다.
- 융합된 확산 표현을 다양한 지각 주석(예: 마스크, 깊이, 키포인트)으로 변환하는 일반화된 Perception Decoder(P-Decoder)를 트랜스포머 기반 아키텍처 내에서 개발한다.
- 실제 라벨의 1% 미만을 사용한 시각적 정렬/명령 조정 튜닝 접근법으로 출력 의존성을 유도하여 P-Decoder를 학습시킨다.
- GPT-4를 활용한 텍스트 가이드 데이터 생성을 통해 다양한 프롬프트를 생성하고 광범위하고 개방형 데이터 합성 파이프라인을 가능하게 한다.
- 데이터 합성 중 확산 모델 가중치를 고정하고 잠재 코드 역변환과 디코더를 사용하여 합성 주석을 생성함으로써 무한한 주석 데이터를 가능하게 한다.
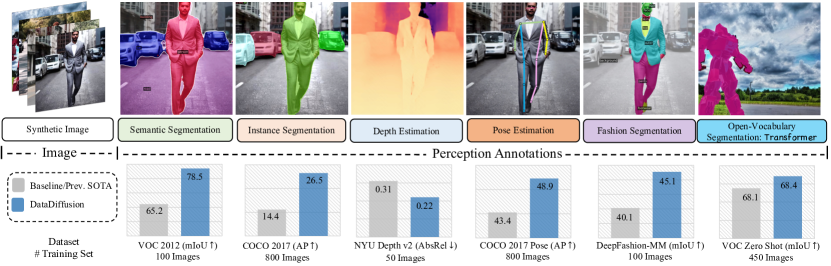
실험 결과
연구 질문
- RQ1통합된 지각 디코더가 확산 잠재 코드를 디코딩하여 여러 태스크에 걸쳐 정확한 지각 주석을 생성할 수 있는가?
- RQ2이 디코더를 무한한 합성 주석 데이터를 가능하게 하도록 학습하는 데 필요한 실제 라벨 데이터의 양은 어느 정도인가?
- RQ3확산 모델의 텍스트 가이드 데이터 생성이 의미론적 세그멘테이션, 인스턴스 세그멘테이션, 깊이 추정, 포즈 추정에서 다운스트림 지각 태스크를 개선하는가?
- RQ4확산 시간 스텝, 교차 주의 융합, 프롬프트 다양성이 합성 주석의 품질과 유용성에 어떤 영향을 미치는가?
주요 결과
- DatasetDM이 생성한 합성 데이터는 여러 태스크에서 상당한 개선을 가져오는데, 예를 들어 VOC 2012 의미론적 세그멘테이션에서 13.3% mIoU 증가, COCO 2017 인스턴스 세그멘테이션에서 12.1% AP 증가.
- 실제 라벨 100장만 사용하고 합성 데이터를 포함하면, VOC 2012의 mIoU가 78.5%에 도달합니다(표 2 맥락에서 실제 데이터만 사용할 때의 기준선 65.2%와 비교).
- COCO2017의 800장의 실제 이미지와 80k장의 합성 이미지로 인스턴스 세그멘테이션이 26.5 AP를 달성합니다(표 3에서 확인).
- 깊이 추정 및 포즈 추정도 이점이 있으며, 합성 데이터로 학습할 때 측정 가능한 개선이 나타납니다(예: NYU Depth V2의 깊이에서 소규모 실제 세트 규모에서도 약 10% 이득; 포즈 추정은 기본값 대비 눈에 띄는 증가).
- 제로샷 및 롱테일 세그멘테이션 태스크는 합성 데이터의 이점을 얻으며, 제로샷/롱테일 설정에서 최대 약 20% mIoU 향상이 보고됩니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.