[논문 리뷰] Deductive Verification of Chain-of-Thought Reasoning
논문은 자연어 추론 형식인 Natural Program을 도입하여 LLM의 각 추론 단계의 단계별 검증을 가능하게 하고, Unanimity-Plurality Voting 체계를 결합하여 연쇄 사고 추론의 엄밀성, 신뢰성, 해석 가능성을 향상시킵니다. 산술 및 상식 데이터셋에 대한 평가에서 단계별, 전제 최소화 검증으로 검증 정확도가 더 높아졌으며, 최종 답변은 많은 경우에 동등하거나 더 우수하고, 전체 검증을 적용할 때는 때때로 약간의 하락이 나타납니다.
Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inadvertently introduce hallucinations and accumulated errors, thereby limiting models' ability to solve complex reasoning tasks. Inspired by how humans engage in careful and meticulous deductive logical reasoning processes to solve tasks, we seek to enable language models to perform explicit and rigorous deductive reasoning, and also ensure the trustworthiness of their reasoning process through self-verification. However, directly verifying the validity of an entire deductive reasoning process is challenging, even with advanced models like ChatGPT. In light of this, we propose to decompose a reasoning verification process into a series of step-by-step subprocesses, each only receiving their necessary context and premises. To facilitate this procedure, we propose Natural Program, a natural language-based deductive reasoning format. Our approach enables models to generate precise reasoning steps where subsequent steps are more rigorously grounded on prior steps. It also empowers language models to carry out reasoning self-verification in a step-by-step manner. By integrating this verification process into each deductive reasoning stage, we significantly enhance the rigor and trustfulness of generated reasoning steps. Along this process, we also improve the answer correctness on complex reasoning tasks. Code will be released at https://github.com/lz1oceani/verify_cot.
연구 동기 및 목표
- LLM에서 망상을 줄이고 Chain-of-Thought(CoT) 오류를 줄이기 위해 엄밀한 연역적 추론을 촉진하고 가능하게 한다.
- 검증 가능성을 높이기 위해 각 추론 단계에서 최소 전제를 명시적으로 나열하는 Natural Program 형식을 제안한다.
- 필요한 맥락만 분석하여 단계별 검증을 개발하고 이를 투표와 결합하여 최종 답변의 신뢰를 향상시킨다.
- GPT-3.5-turbo를 사용한 다양한 추론 벤치마크에서 방법을 경험적으로 검증하고 엄밀성 및 해석 가능성을 개선함을 보여준다.
제안 방법
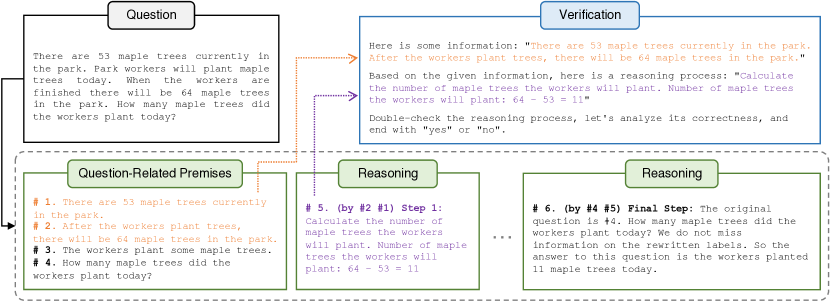
- Natural Program 도입: 질문 관련 전제와 명시적 전제 사용을 포함한 단계별 추론을 나열하는 구조화된 자연어 형식.
- 필요 최소 전제 p_i를 사용한 각 단계의 타당성 V(s_i)으로 연역적 검증을 분해하여 로컬 검증이 가능하게 한다.
- 전제, 단계 설명, 검증 지시를 포함한 프롬프트로 단일 단계 타당성 검사를 수행하며 신뢰성을 높이기 위해 원샷 프롬프트를 사용한다.
- Unanimity-Plurality Voting(UPV) 적용: 만장일치 단계가 모든 단계가 유효한 연쇄를 필터링하고, 다수결 투표로 확인된 연쇄 중 최종 답을 결정한다.
- 두 가지 체제를 평가한다: (i) 전체 검증 없이 Natural Program 추론, (ii) Deductive 검증 및 UPV를 통한 NP 추론; 여러 데이터셋에서 CoT 및 Faithful CoT 기준과 비교한다.
- 데이터셋으로 GSM8K, AQuA, MATH, AddSub, Date, Last Letters를 포함한다.
실험 결과
연구 질문
- RQ1LLM이 Natural Program 형식으로 추론할 때 각 추론 단계의 연역적 타당성을 검증할 수 있는가?
- RQ2단계별, 프리미스 최소화 검증이 엔드 투 엔드 검증에 비해 추론의 엄밀성과 신뢰성을 향상시키는가?
- RQ3Deductive 검증과 UPV를 통합하는 것이 최종 정답 정확도와 다양한 작업에서의 강건성에 어떤 영향을 미치는가?
- RQ4최소 전제 대 전체 전제로 검증 정확도에 미치는 영향은 무엇인가?
주요 결과
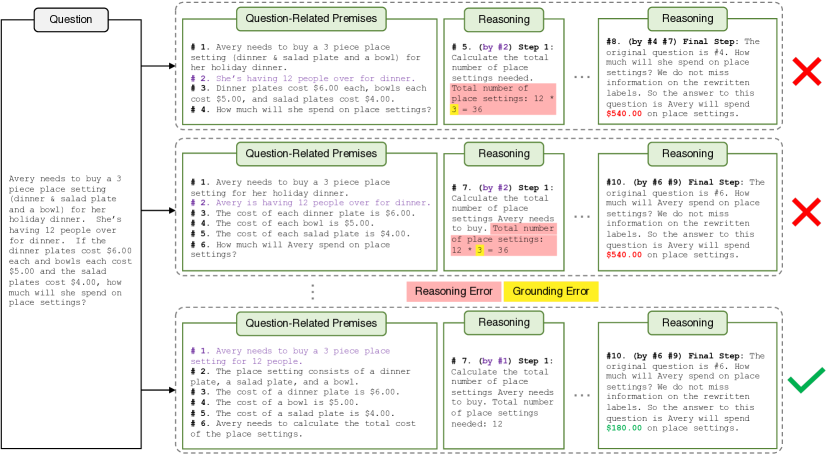
- Natural Program 기반 검증이 대부분의 데이터셋에서 단계별 추론 검증 정확도를 크게 향상시킨다.
- 단계당 최소 전제가 모든 전제를 사용하는 것보다 검증 성능을 크게 향상시키며 관련 없는 맥락으로 인한 주의 산만을 줄인다.
- 단일 단계 타당성에서 투표 수(k')를 늘리면 일반적으로 검증 정확도가 향상되지만 계산 비용이 증가한다.
- Natural Program 형식으로 프롬트를 제시하면 검증 여부와 무관하게-baseline 대비 다수의 작업에서 최종 답변 정확도가 동등하거나 더 우수하게 나타난다.
- 전체 Deductive 검증을 적용하면 논리적 오류가 있는 채널을 걸러내 최종 답변 정확도가 약간 감소할 수 있지만, 추론의 엄밀성은 높아진다.
- 변형 실험은 전제 최소화와 UPV 설정이 검증 정확도와 최종 결과에 실질적인 영향을 준다는 것을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.