[논문 리뷰] Deep Learning Based Text Classification: A Comprehensive Review
감정 분석, 질문 응답(QA), 자연어 추론(NLI) 등 다양한 분야에서 텍스트 분류를 위한 150개가 넘는 DL 모델을 검토하고 분석하며, 40개가 넘는 데이터셋과 함께 16개 벤치마크에 대한 정량적 성능 조사를 제공합니다.
Deep learning based models have surpassed classical machine learning based approaches in various text classification tasks, including sentiment analysis, news categorization, question answering, and natural language inference. In this paper, we provide a comprehensive review of more than 150 deep learning based models for text classification developed in recent years, and discuss their technical contributions, similarities, and strengths. We also provide a summary of more than 40 popular datasets widely used for text classification. Finally, we provide a quantitative analysis of the performance of different deep learning models on popular benchmarks, and discuss future research directions.
연구 동기 및 목표
- 다양한 작업에 걸친 텍스트 분류에 적용된 심층 학습 모델의 현황을 요약한다.
- 텍스트 분류에 널리 사용되는 데이터셋을 분류하고 비교한다.
- 선정된 DL 모델의 벤치마크에 대한 정량적 분석을 제공하고 향후 방향성을 제시한다.
제안 방법
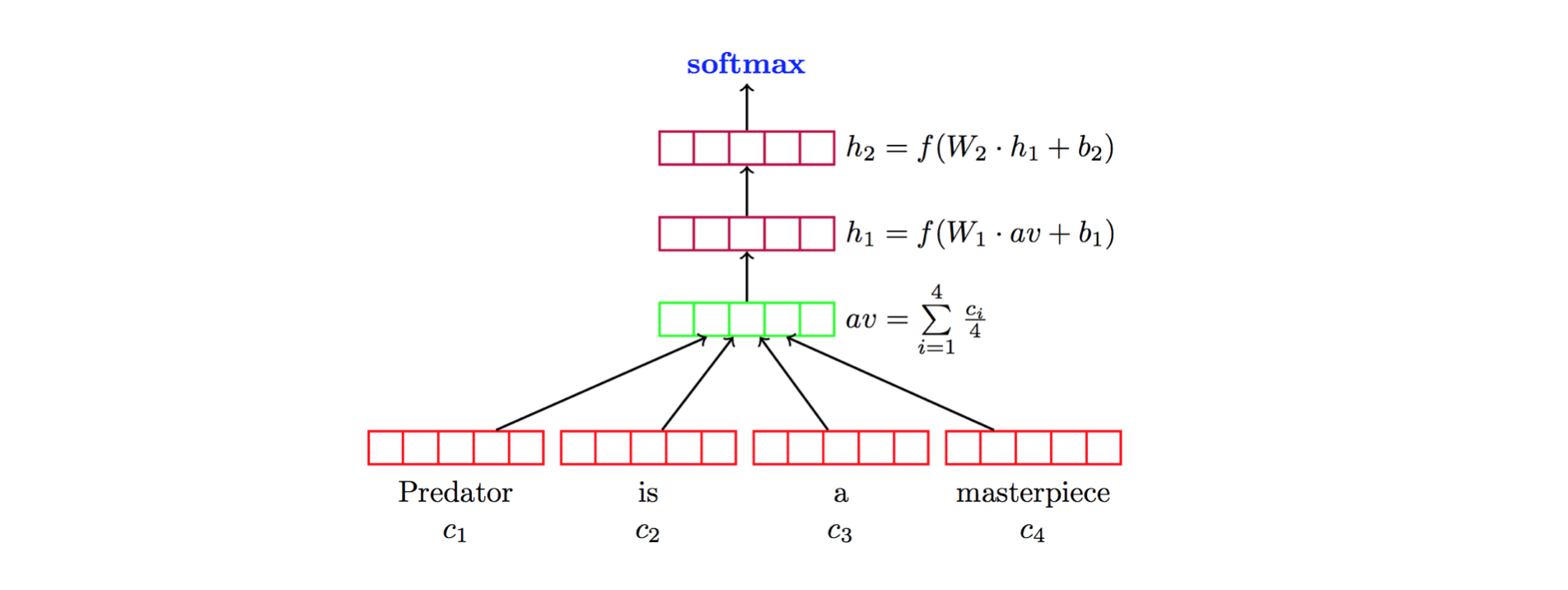
- 구조화된 리뷰를 위해 아키텍처별로 DL 모델을 범주화한다(순환 신경망 RNN, 컨볼루션 신경망 CNN, 트랜스포머, 캡슐 신경망, 그래프 신경망 등).
- 대표 모델과 그들의 아키텍처적 혁신을 설명한다(예: DAN, fastText, Word2Vec/Doc2Vec, LSTM/Tree-LSTM, CNN 변형, CapsNets, 주의 메커니즘, 메모리 네트워크, GNN, 시암 네트 네트워크).
- 텍스트 분류 연구에 사용된 40개가 넘는 데이터셋과 벤치마크를 요약한다.
- 16개의 표준 벤치마크에서 하위 집합의 DL 모델에 대해 정량적 비교를 수행한다.
실험 결과
연구 질문
- RQ1텍스트 분류에 사용되는 지배적인 DL 아키텍처와 시간이 지남에 따른 진화는 무엇인가?
- RQ2다양한 모델 계열(RNN, CNN, 트랜스포머, 캡슐, GNN)은 표준 텍스트 분류 작업에서 어떤 성능을 보이는가?
- RQ3DL 기반 TC 연구를 지배하는 데이터셋과 벤치마크는 무엇이며, 향후 연구를 위한 어떤 간극이 남아 있는가?
- RQ4주의 집중(attention), 메모리 보강, 그래프 기반 접근 방식은 성능과 강인성에 어떻게 기여하는가?
주요 결과
- 본 고찰은 최근 몇 년 간 텍스트 분류를 위해 개발된 150개가 넘는 DL 모델을 다룬다.
- 40개가 넘는 널리 사용되는 텍스트 분류 데이터셋을 요약하고 분석한다.
- 16개의 인기 벤치마크에서의 정량적 성능 분석을 제공한다.
- 논문은 DL 기반 TC의 남은 도전과제와 향후 연구 방향에 대해 논의한다.
- 핸드 크래프트 특징에서 임베딩 및 대규모 사전학습 모델로의 진보를 강조한다.
- 모델을 실용적 계열로 분류한다(예: RNN, CNN, 트랜스포머, 캡슐 네트 Nets, 기억 네트워크, GNN).

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.