[논문 리뷰] Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
본 논문은 간단한 기울기-free 유전 알고리즘이 Atari 및 Humanoid 과제에서 기울기 기반 방법과 대등한 규모의 심층 신경망을 강화학습에 학습시킬 수 있으며, 새로운 인코딩 및 탐색 기법을 제시한다.
Deep artificial neural networks (DNNs) are typically trained via gradient-based learning algorithms, namely backpropagation. Evolution strategies (ES) can rival backprop-based algorithms such as Q-learning and policy gradients on challenging deep reinforcement learning (RL) problems. However, ES can be considered a gradient-based algorithm because it performs stochastic gradient descent via an operation similar to a finite-difference approximation of the gradient. That raises the question of whether non-gradient-based evolutionary algorithms can work at DNN scales. Here we demonstrate they can: we evolve the weights of a DNN with a simple, gradient-free, population-based genetic algorithm (GA) and it performs well on hard deep RL problems, including Atari and humanoid locomotion. The Deep GA successfully evolves networks with over four million free parameters, the largest neural networks ever evolved with a traditional evolutionary algorithm. These results (1) expand our sense of the scale at which GAs can operate, (2) suggest intriguingly that in some cases following the gradient is not the best choice for optimizing performance, and (3) make immediately available the multitude of neuroevolution techniques that improve performance. We demonstrate the latter by showing that combining DNNs with novelty search, which encourages exploration on tasks with deceptive or sparse reward functions, can solve a high-dimensional problem on which reward-maximizing algorithms (e.g.\ DQN, A3C, ES, and the GA) fail. Additionally, the Deep GA is faster than ES, A3C, and DQN (it can train Atari in ${\raise.17ex\hbox{$\scriptstyle\sim$}}$4 hours on one desktop or ${\raise.17ex\hbox{$\scriptstyle\sim$}}$1 hour distributed on 720 cores), and enables a state-of-the-art, up to 10,000-fold compact encoding technique.
연구 동기 및 목표
- 일반적인 유전 알고리즘(GA)이 도전적인 RL 과제에서 대규모로 심층 신경망을 학습시킬 수 있는지 평가한다.
- Atari와 MuJoCo Humanoid 보행에서 GA 성능을 DQN, A3C, ES와 비교한다.
- 심층 RL 설정에서 novelty search 및 기타 신경진화 기법의 이점을 탐구한다.
- GA로 진화된 대규모 네트워크의 효율적이고 압축된 인코딩을 보여준다.
- 단일 머신 및 분산 설정에서 GA의 속도 및 확장성 이점을 조사한다.
제안 방법
- 절단 선택과 엘리티즘을 갖춘 간단한 기울기-없는 GA를 사용하여 신경망 가중치를 진화시킨다.
- 자손을 가법 가우시안 노이즈로 변이시키고; 최고 개체를 엘리티스트로 보존하며; 노이즈를 줄이기 위해 상위 개체를 여러 에피소드로 평가한다.
- 시드 기반 인코딩을 통해 대규모 가중 벡터를 표현하여 컴팩트하고 확장 가능한 분산 학습을 가능하게 한다.
- 기능을 행동적 참신성으로 대체하여 감독 학습 방식으로 novetly search (GA-NS)를 적용한다.
- 두 가지 실험 설정을 테스트한다: 픽셀에서의 Atari(4M+ 매개변수 네트워크)와 MuJoCo에서의 Humanoid Locomotion; DQN, ES, A3C와 비교한다.
- wall-clock 시간 및 확장성을 평가하기 위해 분산 CPU 기반과 GPU 가속 GA 구현을 포함한다.
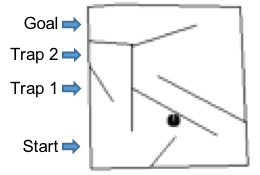
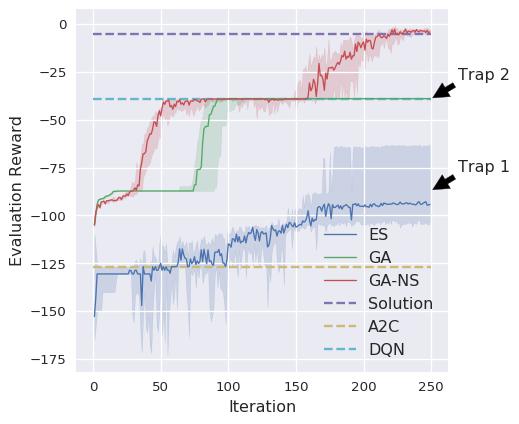
실험 결과
연구 질문
- RQ1단순한 GA가 딥 RL 벤치마크에서 사용되는 규모(예: 4M+ 매개변수)로 심층 신경망을 Atari 및 Humanoid 과제에서 효과적으로 학습시킬 수 있는가?
- RQ2이 도메인들에서 GA의 성능은 기울기 기반 방법(DQN, A3C) 및 ES와 어떻게 비교되는가?
- RQ3기만적이거나 고차원 과제에서 GA와 함께 novelty search를 결합했을 때 탐색 및 성능이 개선되는가?
- RQ4GA로 진화된 대규모 네트워크를 컴팩트하게 인코딩하여 효율적인 분산 학습을 가능하게 할 수 있는가?
- RQ5다른 딥 RL 방법에 비해 GA의 wall-clock 시간 및 계산 비용 이점은 무엇인가?
주요 결과
- GA로 학습된 네트워크는 여러 Atari 게임에서 DQN, A3C, ES와 비슷한 성능을 보이며, 일부 타이틀(예: Skiing, Frostbite, Venture)에서 우수하다.
- GA는 4M+ 매개변수 네트워크를 진화시킬 수 있었으며, 당시 전통적인 진화 알고리즘으로 진화된 가장 큰 신경망을 나타낸다.
- GA 실행은 DQN 및 A3C보다 벽 시계 시간 측면에서 상당히 빠르며, 데스크탑 설정(~4 hours on 4 GPUs/48 CPUs) 및 분산 실행(~1 hour on 720 CPUs)을 포함한다.
- Novelty search (GA-NS)는 보상만 사용하는 GA 및 다른 베이스라인이 해결하지 못하는 고차원 이미지 기반 미로를 해결하게 한다.
- 랜덤 탐색은 특정 게임에서 일부 기울기 기반 방법보다 자주 더 우수하며, 원점 근처의 촘촘한 로컬 탐색이 일부 도메인에서 강한 해를 낳을 수 있음을 강조한다.
- GA with novelty exploration은 심층 신경진화에서 다양성 및 품질 신호의 통합 가치를 보여주며, 딥 RL과의 잠재적 하이브리드 접근법을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.