[논문 리뷰] Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
DEPS는 오픈 월드 다중 작업 에이전트를 위한 LLM 기반 인터랙티브 계획 프레임워크로, 기술된 Describe, Explain, Plan, Select 사이클과 수평도 예측 선택기(horizon-predictive selector)를 통해 계획의 신뢰성을 향상시키며, 제로샷 Minecraft 성능이 강하고 ALFWorld 및 탁상 작업으로 일반화됩니다.
We investigate the challenge of task planning for multi-task embodied agents in open-world environments. Two main difficulties are identified: 1) executing plans in an open-world environment (e.g., Minecraft) necessitates accurate and multi-step reasoning due to the long-term nature of tasks, and 2) as vanilla planners do not consider how easy the current agent can achieve a given sub-task when ordering parallel sub-goals within a complicated plan, the resulting plan could be inefficient or even infeasible. To this end, we propose "$\underline{D}$escribe, $\underline{E}$xplain, $\underline{P}$lan and $\underline{S}$elect" ($ extbf{DEPS}$), an interactive planning approach based on Large Language Models (LLMs). DEPS facilitates better error correction on initial LLM-generated $ extit{plan}$ by integrating $ extit{description}$ of the plan execution process and providing self-$ extit{explanation}$ of feedback when encountering failures during the extended planning phases. Furthermore, it includes a goal $ extit{selector}$, which is a trainable module that ranks parallel candidate sub-goals based on the estimated steps of completion, consequently refining the initial plan. Our experiments mark the milestone of the first zero-shot multi-task agent that can robustly accomplish 70+ Minecraft tasks and nearly double the overall performances. Further testing reveals our method's general effectiveness in popularly adopted non-open-ended domains as well (i.e., ALFWorld and tabletop manipulation). The ablation and exploratory studies detail how our design beats the counterparts and provide a promising update on the $ exttt{ObtainDiamond}$ grand challenge with our approach. The code is released at https://github.com/CraftJarvis/MC-Planner.
연구 동기 및 목표
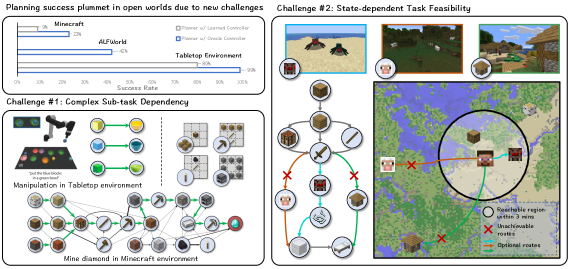
- 오픈 월드(예: Minecraft)에서의 장기 horizon 계획의 난제에 대처하여 계획이 실현 불가능하거나 비효율적일 수 있다는 문제를 해결한다.
- 설명자 및 설명자 피드백을 통한 오류 인식형 계획 수정으로 계획의 강건성을 향상시킨다.
- 가까운 목표를 선택하는 수평 기반(horizon-based) 목표 선택기를 도입하여 예측 가능한 서브목표를 선택함으로써 계획의 실행 가능성을 높인다.
- 환경 특화 계획 훈련 없이도 70개 이상의 Minecraft 작업을 제로샷으로 해결하는 능력을 시연한다.
- ALFWorld 및 탁상 조작과 같은 비 개방형 도메인으로의 일반화를 보여준다.
제안 방법
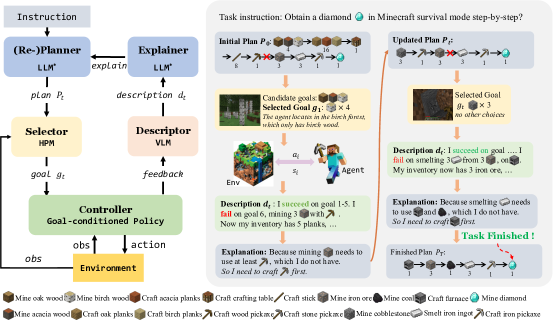
- DEPS를 제안한다: LLM이 기술자(descriptor), 설명자(explainer), 계획자(planner) 역할을 하며 서브목표를 반복적으로 정교화하는 루프.
- 서브목표 실행 실패 후 현재 상태를 요약하는 디스크립터를 사용하고 이를 LLM에 피드백하여 자기 설명 및 재계획을 수행한다.
- 남은 단계(호라이즌)를 각 후보 서브목표를 완료하기 위한 예측하고 가장 가까운/가장 실현 가능한 것을 선택하는 수평 예측 선택기를 도입한다.
- 목표 실현 가능성과 호라이즌을 예측하도록 백본(Impala CNN 기반) 학습기를 트레이닝하여 계획 효율성을 높인다.
- 제로샷 LLM 계획자와 학습된 정책을 통해 서브목표를 실행하는 목표 조건 제어자(goal-conditioned controller)를 바탕으로 접근법을 구체화한다.
실험 결과
연구 질문
- RQ1오픈 월드의 장기 과제에서 실패로부터 회복할 수 있는 LLM 기반 계획자는 어떻게 작동하는가?
- RQ2설명, 설명자, 계획을 통한 피드백 기반 재계획이 오픈 월드에서의 일회성 계획보다 성공률을 향상시키는가?
- RQ3호라이즌 인지 선택기가 오픈 월드 과제의 서브목표 시퀀스의 효율성과 실행 가능성을 향상시키는가?
- RQ4DEPS가 Minecraft를 넘어 ALFWorld 및 탁상 조작과 같은 다른 도메인으로 일반화되는 정도는 어느 수준인가?
- RQ5다중 재계획 라운드가 개방형 환경에서의 작업 성공에 미치는 영향은 무엇인가?
주요 결과
| Method | MT1 | MT2 | MT3 | MT4 | MT5 | MT6 | MT7 | MT8 | AVG |
|---|---|---|---|---|---|---|---|---|---|
| DEPS | 79.77 | 79.46 | 62.40 | 53.32 | 29.24 | 13.80 | 12.56 | 0.59 | 48.56 |
- DEPS는 71개의 Minecraft 작업에서 모든 언어 플래너 베이스라인보다 상당한 우위를 보이며 전체 성공률을 거의 두 배로 증가시킨다.
- 아블레이션 결과는 설명, 자기 설명 및 재계획(DEP)을 포함한 DEPS가 이전 계획자보다 우수하며 선택기를 추가하면(DEPS) 추가 이득이 발생한다.
- 수평 예측 선택기는 병렬 목표가 많은 작업에서 특히 효율성을 개선하고 비전을 언어 기반 바탕의 기준선보다 실행 가능성 순위를 더 잘 제시한다.
- 재계획 라운드가 많아질수록 성공률이 증가하며, 더 어려운 작업에서 이득이 커지며 수평-제한 토큰 제약까지 증가한다.
- DEPS는 10분 이내 ObtainDiamond에서 0.59%를 달성하며 태스크별 미세 조정 없이도 최신 제로샷 계획 성능에 근접하고, 도메인 간 일반화(HALFWorld, Tabletop)에서도 강력한 결과를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.