[논문 리뷰] Differentiable Learning-to-Normalize via Switchable Normalization
Switchable Normalization(SN)은 학습 가능한 중요 가중치를 사용하여 각 계Layer에서 세 가지 정규화 통계량(IN, LN, BN)을 선택적으로 결합하도록 학습하며, 이는 작은 배치 크기에 대한 강인성 확보와 시각 태스크 전반의 성능 향상을 가져온다.
We address a learning-to-normalize problem by proposing Switchable Normalization (SN), which learns to select different normalizers for different normalization layers of a deep neural network. SN employs three distinct scopes to compute statistics (means and variances) including a channel, a layer, and a minibatch. SN switches between them by learning their importance weights in an end-to-end manner. It has several good properties. First, it adapts to various network architectures and tasks (see Fig.1). Second, it is robust to a wide range of batch sizes, maintaining high performance even when small minibatch is presented (e.g. 2 images/GPU). Third, SN does not have sensitive hyper-parameter, unlike group normalization that searches the number of groups as a hyper-parameter. Without bells and whistles, SN outperforms its counterparts on various challenging benchmarks, such as ImageNet, COCO, CityScapes, ADE20K, and Kinetics. Analyses of SN are also presented. We hope SN will help ease the usage and understand the normalization techniques in deep learning. The code of SN has been made available in https://github.com/switchablenorms/.
연구 동기 및 목표
- 고정된 선택지 대신 여러 계층에 서로 다른 정규화기를 허용함으로써 정규화 학습의 필요성을 자극한다.
- IN, LN, BN 통계를 엔드투엔드로 가중치화하는 미분 가능 메커니즘을 개발한다.
- 다양한 미니배치 크기에 대한 SN의 강인성을 보여준다.
- 민감한 하이퍼파라미터 없이도 SN이 다양한 아키텍처와 태스크에 적응함을 보여준다.
제안 방법
- 평균과 분산의 가중 평균(Eq. 3)을 통해 IN, LN, BN의 세 통계 세트를 결합하는 SN을 도입한다.
- IN, LN, BN 간 계산을 재사용하여 통계를 효율적으로 계산한다(Eq. 4).
- 제어 파라미터 λ_k 및 λ_k′에 대한 소프트맥스를 통해 평균 및 분산에 대한 중요 가중치 w_k 및 w_k′를 학습한다(Eq. 5).
- 손실 L(Θ,Φ)을 최소화하도록 역전파로 네트워크 매개변수 Θ와 제어 매개변수 Φ를 함께 학습한다.
- 정규화 기를 비교하기 위해 가중치 정규화에 대한 SN의 기하학적 해석(Remark 1)을 제공한다.
- 희소성 및 그룹 SN과 같은 변형을 향후 연구로 논의하고 배치 평균 통계를 사용한 추론 절차를 개략한다.

실험 결과
연구 질문
- RQ1하나의 정규화 층이 주어진 계층과 태스크에 대해 가장 적합한 정규화기를 선택하도록 학습할 수 있는가?
- RQ2IN, LN, BN의 혼합이 다양한 미니배치 크기에서 통계적으로 성능과 안정성을 향상시키는가?
- RQ3민감한 하이퍼파라미터 없이도 SN이 다양한 네트워크 아키텍처와 데이터셋에 대해 강인한가?
- RQ4분류, 탐지, 분할, 비디오 인식과 같은 태스크에서 학습된 정규화 가중치는 어떻게 적응하는가?
주요 결과
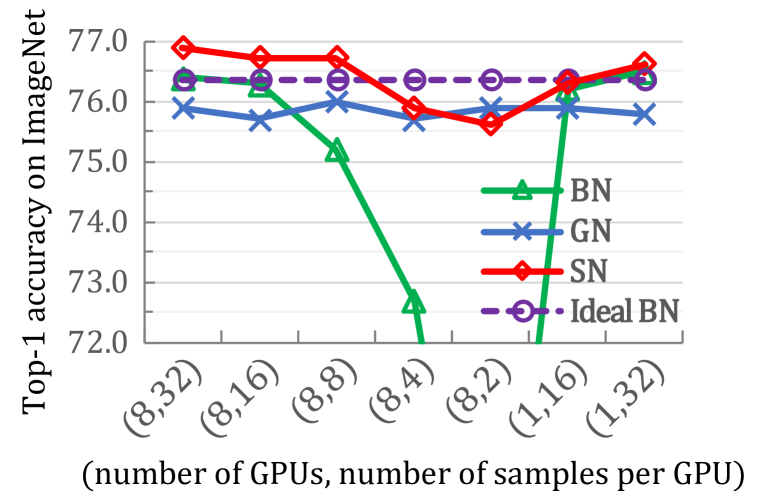
- SN은 ImageNet에서 다수의 배치 설정에서 BN 및 GN보다 우수한 성능을 보인다(예: SN이 76.9% top-1으로 BN/GN 베이스라인을 상회).
- 배치 크기가 작아져도 SN은 높은 성능을 유지하는 반면 BN은 크게 저하되며, SN은 배치 설정 전반에서 이상적인 BN에 근접하거나 이를 능가한다.
- 작업과 데이터셋에 따라 정규화 구성를 적응시켜 예: 큰 미니배치에서는 BN이 선호되고, 매우 작은 미니배치에서는 LN이 우세하다.
- 객체 탐지(Faster R-CNN, Mask R-CNN)와 의미론적 분할(Cityscapes, ADE20K)에서 성능을 향상시키며, 종종 GN 및 SyncBN 베이스라인을 능가한다.
- Kinetics 비디오 인식 및 기타 태스크에서 경쟁력 있는 또는 우수한 결과를 보여 주며, 폭넓은 적용 가능성을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.