[논문 리뷰] Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
DiffSeg는 사전에 학습된 Stable Diffusion 모델의 자기 주의를 활용하여 훈련 없이도 무감독 제로샷 방식으로 분할 마스크를 생성하고, COCO-Stuff-27에서 최첨단 성능을 달성하며 Cityscapes에서도 경쟁력 있는 결과를 보인다.
Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU. The project page is at \url{https://sites.google.com/view/diffseg/home}.
연구 동기 및 목표
- 사전에 학습된 Stable Diffusion의 자기 주의가 주석 없이도 분할에 적합한 객체 그룹화 신호를 포함하는지 조사한다.
- 훈련 없이 주의 맵을 일관된 분할 마스크로 변환할 수 있는 후처리 파이프라인을 개발한다.
- 표준 벤치마크에서 제로샷 성능을 입증하고 기존의 비감독 방법들과 비교한다.
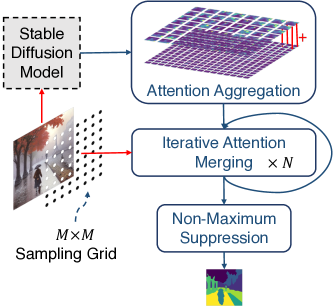
제안 방법
- 실제 이미지에서 조건 없는 Stable Diffusion 실행으로부터 자기 주의 텐서를 추출한다.
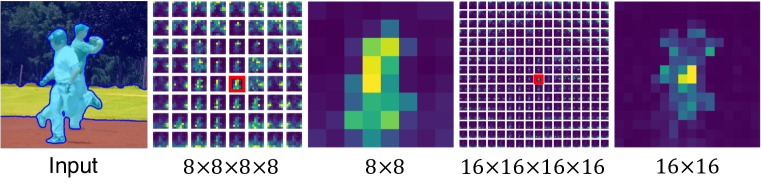
- 다중 해상도 주의 맵을 고해상도 표현으로 집계한다.
- 클래스 KL 발산을 사용해 주의 맵을 반복적으로 병합하여 마스크 개수 사전 지정 없이 객체 제안 마스크를 형성한다.
- 제안들 간에 비최대 억제(NMS)를 적용해 최종 픽셀 단위 분할 마스크를 생성한다.
- Ground-truth 마스크와의 헝가리 매칭으로 픽셀 정확도(ACC) 및 평균 IoU(mIoU)를 사용해 평가한다.
실험 결과
연구 질문
- RQ1사전에 학습된 Stable Diffusion 모델의 자기 주의가 프롬프트나 학습 없이도 분할에 충분한 고유의 객체/그룹화를 드러낼 수 있는가?
- RQ2간단한 후처리를 통해 무조건 디퓨전 주의로부터 고품질 분할 마스크를 얻을 수 있는가?
- RQ3기존의 비감독 방법들과 비교했을 때 제로샷 분할 벤치마크에서 DiffSeg의 성능은 어떠한가?
주요 결과
| 모델 | LD | AX | UA | ACC | mIoU |
|---|---|---|---|---|---|
| IIC | ✗ | ✗ | ✓ | 21.8 | 6.7 |
| MDC | ✗ | ✗ | ✓ | 32.3 | 9.8 |
| PiCLE | ✗ | ✗ | ✓ | 48.1 | 13.8 |
| PiCLE+H | ✗ | ✗ | ✓ | 50.0 | 14.4 |
| STEGO | ✗ | ✗ | ✓ | 56.9 | 28.2 |
| ACSeg | ✓ | ✗ | ✓ | - | 28.1 |
| MaskCLIP | ✓ | ✗ | ✗ | 32.2 | 19.6 |
| ReCo | ✓ | ✓ | ✗ | 46.1 | 26.3 |
| K-Means-C | ✗ | ✗ | ✗ | 58.9 | 33.7 |
| K-Means-S | ✗ | ✗ | ✗ | 62.6 | 34.7 |
| Ours: DiffSeg (320) | ✗ | ✗ | ✗ | 72.5 | 43.0 |
| Ours: DiffSeg (512) | ✗ | ✗ | ✗ | 72.5 | 43.6 |
- DiffSeg는 COCO-Stuff-27의 비감독 제로샷 분할에서 최첨단(SOTA)을 달성하고, 픽셀 정확도에서 이전 SOTA보다 26pp, 평균 IoU에서 17pp 향상시켰다.
- DiffSeg는 언어 의존성이나 보조 이미지 없이도 320×320 및 512×512 해상도에서 COCO-Stuff-27에 대해 이전 방법들을 능가한다.
- Cityscapes에서 DiffSeg는 기존 제로샷 방법과 동등하거나 우수하며, 특히 클래스 세분성으로 인해 더 작은 입력 해상도에서 더 높은 성능을 보인다.
- 대체 비감독 기준선들(K-Means 변형 등)과 비교할 때 DiffSeg는 미리 정의된 클러스터 수를 필요로 하지 않으면서도 더 안정적이고 품질 높은 분할을 제공한다.
- 이 방법은 DomainNet 스케치, 그림, 실제 사진 등 다양한 이미지 스타일에 강한 일반화를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.