[논문 리뷰] Diffusion Cross-domain Recommendation
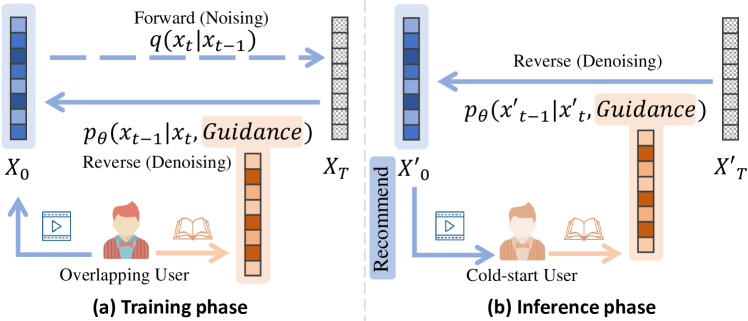
DiffCDR은 Diffusion 확률 모델 기반의 교차 도메인 추천기를 도입하여 풍부한 보조 도메인에서 희소한 대상 도메인으로 사용자 임베딩을 전이하고, Diffusion Module과 Alignment Module을 사용하여 강한 콜드 스타트 및 웜 스타트 성능을 달성한다.
It is always a challenge for recommender systems to give high-quality outcomes to cold-start users. One potential solution to alleviate the data sparsity problem for cold-start users in the target domain is to add data from the auxiliary domain. Finding a proper way to extract knowledge from an auxiliary domain and transfer it into a target domain is one of the main objectives for cross-domain recommendation (CDR) research. Among the existing methods, mapping approach is a popular one to implement cross-domain recommendation models (CDRs). For models of this type, a mapping module plays the role of transforming data from one domain to another. It primarily determines the performance of mapping approach CDRs. Recently, diffusion probability models (DPMs) have achieved impressive success for image synthesis related tasks. They involve recovering images from noise-added samples, which can be viewed as a data transformation process with outstanding performance. To further enhance the performance of CDRs, we first reveal the potential connection between DPMs and mapping modules of CDRs, and then propose a novel CDR model named Diffusion Cross-domain Recommendation (DiffCDR). More specifically, we first adopt the theory of DPM and design a Diffusion Module (DIM), which generates user's embedding in target domain. To reduce the negative impact of randomness introduced in DIM and improve the stability, we employ an Alignment Module to produce the aligned user embeddings. In addition, we consider the label data of the target domain and form the task-oriented loss function, which enables our DiffCDR to adapt to specific tasks. By conducting extensive experiments on datasets collected from reality, we demonstrate the effectiveness and adaptability of DiffCDR to outperform baseline models on various CDR tasks in both cold-start and warm-start scenarios.
연구 동기 및 목표
- 교차 도메인 추천 시스템에서 보조 도메인 데이터를 활용하여 콜드 스타트 문제를 해결한다.
- 도메인 간 사용자 임베딩을 전이하기 위한 확산 기반 매핑 모듈을 제안한다.
- 교차 도메인 전송을 안정화하기 위한 Alignment Module을 제안한다.
- Diffusion outputs를 태스크 목적에 맞게 정렬하기 위해 대상 도메인 라벨 데이터를 포함한다.
- 콜드 및 웜 스타트 설정에서 현실 세계의 Amazon 도메인 CDR 태스크에서 효과를 입증한다.
제안 방법
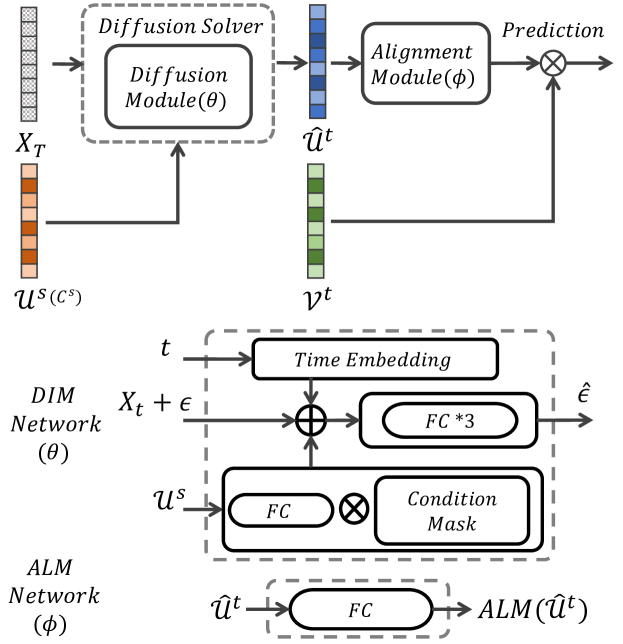
- 소스 도메인 임베딩을 조건으로 역확산을 통해 대상 도메인 사용자 임베딩을 생성하기 위해 Diffusion Module (DIM)을 도입한다.
- 무작위성을 줄이고 전이된 임베딩을 실제 대상 임베딩과 정렬하기 위해 Alignment Module (ALM)을 추가한다.
- DIM 추론의 효율성을 위해 빠른 확산 해를 사용한다.
- 예측 노이즈를 실제 노이즈와 일치시키는 DIM 손실과 ALM+태스크 손실로 전이된 임베딩을 대상 도메인 평점과 연결하는 손실로 학습한다.
- ALM 출력과 대상 도메인 평점을 결합하여 특정 태스크에 맞추는 태스크 지향 손실을 사용한다.
- DIM, ALM 및 태스크 지향 학습의 기여를 분리하기 위한 제거 연구를 수행한다.
실험 결과
연구 질문
- RQ1DiffCDR은 콜드스타트 및 웜스타트 설정에서 최신의 교차 도메인 추천 baselines와 비교하여 어떤 성능을 보이는가?
- RQ2DIM과 ALM 구성 요소가 성능에 어떻게 기여하는가, 그리고 대상 라벨 태스크 손실의 포함이 미치는 영향은?
- RQ3확산 기반 전이가 교차 도메인 지식 전이에 왜 개선을 가져오는가?
- RQ4DiffCDR의 추론 처리량은 전통적 방법과 비교하여 어떤가?
주요 결과
| Beta | CDR Task | 지표 | TGT | CMF | EMCDR | SSCDR | LACDR | PTUPCDR | DiffCDR | 향상 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20% | Task1 Video → Music | MAE | 4.4546 | 1.4642 | 1.3596 | 1.1757 | 1.1295 | 1.1099 | 1.0435* | 6.0% |
| 20% | Task1 Video → Music | RMSE | 5.1338 | 1.9571 | 1.6615 | 1.4911 | 1.4358 | 1.4543 | 1.3840* | 3.6% |
| 20% | Task1 Video → Music | N@20 | 0.00253 | 0.00508 | 0.00977 | 0.00932 | 0.00984 | 0.00978 | 0.01026* | 4.3 % |
| 20% | Task1 Video → Music | H@20 | 0.00033 | 0.00084 | 0.00229 | 0.00212 | 0.00228 | 0.00236 | 0.00238* | 1.1 % |
| 50% | Task1 Video → Music | MAE | 4.4884 | 1.6710 | 1.6891 | 1.4320 | 1.3502 | 1.2842 | 1.2367* | 3.7% |
| 50% | Task1 Video → Music | RMSE | 5.1790 | 2.2076 | 2.0368 | 1.8248 | 1.7510 | 1.7340 | 1.6859* | 2.8% |
| 50% | Task1 Video → Music | N@20 | 0.00251 | 0.00403 | 0.00898 | 0.00793 | 0.00893 | 0.00828 | 0.00915* | 1.9% |
| 50% | Task1 Video → Music | H@20 | 0.00033 | 0.00068 | 0.00193 | 0.00164 | 0.00199 | 0.00179 | 0.00202* | 1.9% |
| 80% | Task1 Video → Music | MAE | 4.4959 | 2.2327 | 2.1980 | 1.8162 | 1.6886 | 1.6174 | 1.5606* | 3.5% |
| 80% | Task1 Video → Music | RMSE | 5.1830 | 2.8868 | 2.5713 | 2.3090 | 2.2238 | 2.2429 | 2.1754* | 2.2% |
| 80% | Task1 Video → Music | N@20 | 0.00248 | 0.00348 | 0.00622 | 0.00578 | 0.00606 | 0.00545 | 0.00665* | 6.9% |
| 80% | Task1 Video → Music | H@20 | 0.00033 | 0.00051 | 0.00124 | 0.00111 | 0.00124 | 0.00107 | 0.00136* | 9.7% |
| 20% | Task2 Book → Video | MAE | 4.1807 | 1.4742 | 1.1305 | 0.9774 | 0.9681 | 1.0728 | 0.9476* | 2.1% |
| 20% | Task2 Book → Video | RMSE | 4.7496 | 1.9180 | 1.4215 | 1.2356 | 1.2311 | 1.3745 | 1.2338* | -0.2% |
| 20% | Task2 Book → Video | N@20 | 0.00245 | 0.00578 | 0.01898 | 0.02066 | 0.01850 | 0.01821 | 0.02073 | 0.3% |
| 20% | Task2 Book → Video | H@20 | 0.00043 | 0.00124 | 0.0064 | 0.00676 | 0.0056 | 0.00594 | 0.00697* | 3.1% |
| 50% | Task2 Book → Video | MAE | 4.1951 | 1.5651 | 1.1863 | 1.0193 | 1.0077 | 1.1116 | 0.9953 | 1.2% |
| 50% | Task2 Book → Video | RMSE | 4.7693 | 2.0341 | 1.4993 | 1.3089 | 1.3051 | 1.4425 | 1.3155 | -0.8% |
| 50% | Task2 Book → Video | N@20 | 0.00274 | 0.00536 | 0.01924 | 0.02041 | 0.01875 | 0.01785 | 0.02047 | 0.3% |
| 50% | Task2 Book → Video | H@20 | 0.00044 | 0.00107 | 0.00642 | 0.00675 | 0.00535 | 0.00575 | 0.0068 | 0.7% |
| 80% | Task2 Book → Video | MAE | 4.2384 | 2.2379 | 1.3445 | 1.1469 | 1.1151 | 1.2072 | 1.0846* | 2.7% |
| 80% | Task2 Book → Video | RMSE | 4.8198 | 3.1740 | 1.6946 | 1.4871 | 1.4660 | 1.5968 | 1.4695 | -0.2% |
| 80% | Task2 Book → Video | N@20 | 0.00258 | 0.00412 | 0.01906 | 0.01949 | 0.01710 | 0.01520 | 0.01960 | 0.6% |
| 80% | Task2 Book → Video | H@20 | 0.00040 | 0.00073 | 0.00628 | 0.00636 | 0.00512 | 0.00484 | 0.00634 | -0.3% |
| 20% | Task3 Book → Music | MAE | 4.5190 | 1.7976 | 1.6425 | 1.3073 | 1.1945 | 1.2556 | 1.1220* | 6.1% |
| 20% | Task3 Book → Music | RMSE | 5.1838 | 2.3545 | 1.9873 | 1.6599 | 1.5771 | 1.6730 | 1.5390* | 2.4% |
| 20% | Task3 Book → Music | N@20 | 0.00196 | 0.00383 | 0.01193 | 0.01179 | 0.01367 | 0.01006 | 0.01374 | 0.5% |
| 20% | Task3 Book → Music | H@20 | 0.00035 | 0.00071 | 0.00323 | 0.00313 | 0.0037 | 0.00275 | 0.00382* | 3.2% |
| 50% | Task3 Book → Music | MAE | 4.4953 | 2.0002 | 1.9364 | 1.5183 | 1.3925 | 1.4304 | 1.3077* | 6.1% |
| 50% | Task3 Book → Music | RMSE | 5.1685 | 2.6001 | 2.2966 | 1.9467 | 1.8644 | 1.9475 | 1.8255* | 2.1% |
| 50% | Task3 Book → Music | N@20 | 0.00200 | 0.00341 | 0.00994 | 0.00964 | 0.01058 | 0.00804 | 0.01082* | 2.3% |
| 50% | Task3 Book → Music | H@20 | 0.00028 | 0.00059 | 0.00253 | 0.00247 | 0.00277 | 0.00206 | 0.00281* | 1.7% |
| 80% | Task3 Book → Music | MAE | 4.5133 | 2.5014 | 2.3448 | 1.8849 | 1.7107 | 1.7016 | 1.5871* | 6.7% |
| 80% | Task3 Book → Music | RMSE | 5.1960 | 3.1740 | 2.7035 | 2.3517 | 2.2468 | 2.3248 | 2.2110* | 1.6% |
| 80% | Task3 Book → Music | N@20 | 0.00170 | 0.00275 | 0.00705 | 0.00652 | 0.00658 | 0.00682 | 0.00722* | 2.3% |
| 80% | Task3 Book → Music | H@20 | 0.00027 | 0.00046 | 0.00176 | 0.00158 | 0.00165 | 0.00107 | 0.00179* | 1.6% |
- DiffCDR은 Amazon 데이터셋의 콜드스타트 및 웜스타트 CDR 태스크에서 여러 베이스라인(CMF, EMCDR, SSCDR, LACDR, PTUPCDR)을 상회한다.
- 제거 연구로 DIM, ALM 및 태스크 지향 학습이 각각 성능 향상에 기여하는 것을 보여준다.
- DAT 구성의 전체 구성으로 DiffCDR은 다수의 태스크와 콜드 스타트 수준에서 최상의 결과를 달성하며, MAE, RMSE, N@20, H@20에서 가장 강력한 베이스라인 대비 상당한 개선을 보인다.
- 빠른 DIM 해를 사용하면 추론 속도가 크게 빨라지면서 정확도 손실은 거의 없다.
- 시각화는 DiffCDR이 다른 방법들보다 대상 도메인으로 사용자 인자를 더 일관되게 전이한다는 것을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.