[논문 리뷰] Diffusion Models for Open-Vocabulary Segmentation
OVDiff는 텍스트-투-이미지 확산 모델을 사용해 임의의 범주에 대한 보조 이미지 셋을 생성하고, 여러 시각적 프로토타입(전경 및 배경)을 구축한 뒤 학습 없이 근접 프로토타입 매칭으로 이미지를 분할합니다. 제로샷 개방 어휘 분할 성능이 강력하며, 결정의 근거를 보조 집합의 영역으로 매핑해 설명 가능성을 제공합니다.
Open-vocabulary segmentation is the task of segmenting anything that can be named in an image. Recently, large-scale vision-language modelling has led to significant advances in open-vocabulary segmentation, but at the cost of gargantuan and increasing training and annotation efforts. Hence, we ask if it is possible to use existing foundation models to synthesise on-demand efficient segmentation algorithms for specific class sets, making them applicable in an open-vocabulary setting without the need to collect further data, annotations or perform training. To that end, we present OVDiff, a novel method that leverages generative text-to-image diffusion models for unsupervised open-vocabulary segmentation. OVDiff synthesises support image sets for arbitrary textual categories, creating for each a set of prototypes representative of both the category and its surrounding context (background). It relies solely on pre-trained components and outputs the synthesised segmenter directly, without training. Our approach shows strong performance on a range of benchmarks, obtaining a lead of more than 5% over prior work on PASCAL VOC.
연구 동기 및 목표
- 오류열거: 학습 데이터가 없는 상태에서 개방 어휘 의미 분할을 다룬다.
- 각 범주에 대해 다양한 외관과 맥락을 샘플링하기 위해 확산 모델을 활용한다.
- 강건한 분할을 위해 언어 없이도 프로토타입으로 사전에 학습된 시각 백본을 접지한다.
- 전경 및 배경 프로토타입을 포함시켜 물체-배경 구분 및 설명 가능성을 개선한다.
제안 방법
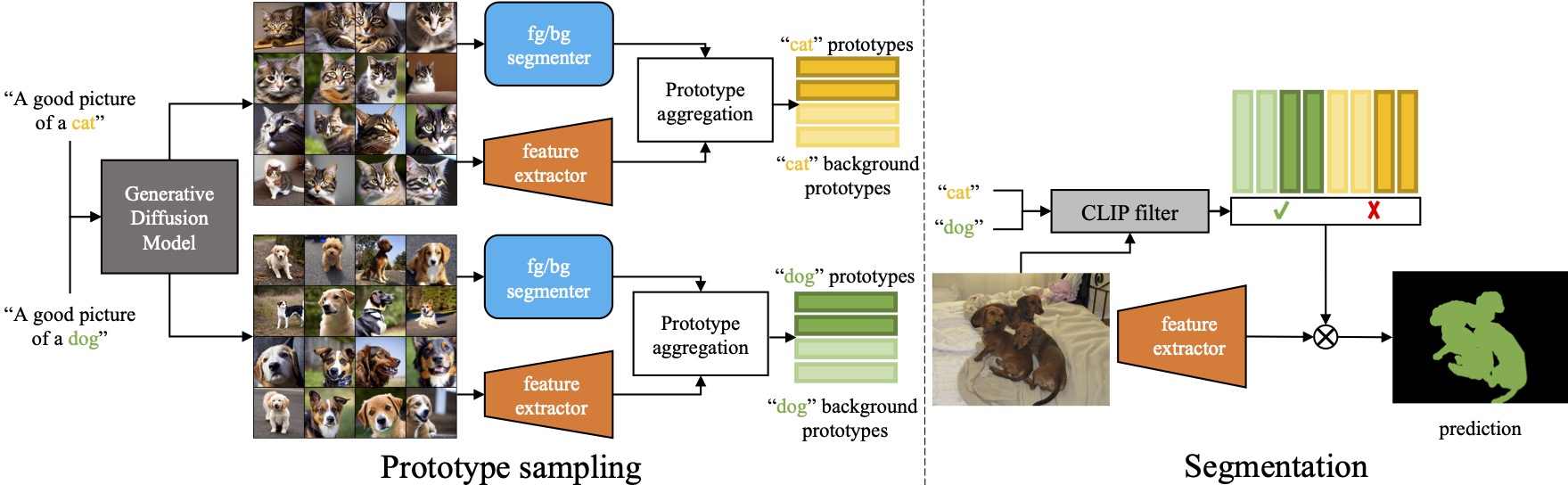
- Stable Diffusion으로 텍스트 프롬프트를 사용하여 질의당 보조 이미지를 생성한다.
- 사전학습된 시각 인코더와 비감독(segmentation)으로 보조 이미지에서 클래스 및 인스턴스 프로토타입을 추출한다.
- 마스크된 특징의 K-평균 클러스터링으로 얻은 파트 수준 중심점을 사용해 프로토타입을 보강한다.
- 전경 및 배경 프로토타입을 개방 어휘 바인딩에 사용하고 픽셀당 코사인 유사도 기반의 단일 분류기를 적용한다.
- 클립 기반의 카테고리 선필터링 및 Stuff/Thing filtering을 적용해 허위 카테고리를 줄이고 배경 영역을 처리한다.
- 각 후보 범주(배경 클래스를 포함)에 대해 프로토타입 세트에 대한 가장 근접한 프로토타입 매칭으로 대상 이미지를 분할한다.
실험 결과
연구 질문
- RQ1확산 생성 보조 세트가 미세조정 없이도 개방 어휘 분할을 접지할 수 있는가?
- RQ2인스턴스, 클래스, 파트 등 여러 프로토타입과 배경 프로토타입을 사용하는 것이 분할 품질에 어떤 영향을 미치는가?
- RQ3사전필터링 및 Stuff/Thing 카테고리의 필터링이 개방 어휘 분할 성능에 어떤 역할을 하는가?
- RQ4OVDiff가 표준 개방 어휘 벤치마크(VOC, Context, Object)와 다양한 특징 추출기에 대해 어떻게 수행되는가?
주요 결과
| 방법 | VOC mIoU | Context mIoU | Object mIoU |
|---|---|---|---|
| OVDiff (Ours) | 67.1 ± 0.5 | 30.1 ± 0.2 | 34.8 ± 0.2 |
- OVDiff는 제로샷 개방 어휘 분할에서 강력한 성능을 달성하며 VOC, Context, Object 벤치마크에서 기존 방법들을 능가한다.
- 배경 프로토타입과 카테고리 선필터링을 활용하면 성능이 크게 향상되고 허위 상관관계가 줄어든다.
- 실험에서 SD, DINO, CLIP 특징 추출기를 조합한 OVDiff가 최상의 결과를 낸다(예: VOC 단일 설정 63.6, 앙상블로 최대 67.0).
- 전경, 배경, 파트 수준의 프로토타입은 보조 집합 영역과의 연결을 통해 더 세밀한 분할과 설명 가능성을 제공한다.
- 이 방법은 여전히 학습 없이, 사전 학습된 컴포넌트와 확산 기반 보조 세트 생성 프로세스에 의존한다.
- 지원 세트 크기에 따라 성능이 확장되며 각 클래스당 대략 128샘플에서 안정화된다.
![Figure 2 : Qualitative results . OVDiff in comparison to TCL [ 9 ] (+ PAMR) . OVDiff provides more accurate segmentations across a range objects and stuff classes with well defined object boundaries that separate from the background well. Last 2 columns show failure cases. Additional table and light](https://ar5iv.labs.arxiv.org/html/2306.09316/assets/figures/images/main_qual_figure.jpg)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.