[논문 리뷰] DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
DIN-SQL은 텍스트-대-SQL을 스키마 연결, 분류/해체, NatSQL 기반의 SQL 생성, 그리고 자기 수정으로 분해하고, 맥락 학습을 통해 실행 정확도를 크게 향상시키며, holdout에서 기존 Spider SOTA를 넘고 BIRD에서 새로운 SOTA를 달성한다.
There is currently a significant gap between the performance of fine-tuned models and prompting approaches using Large Language Models (LLMs) on the challenging task of text-to-SQL, as evaluated on datasets such as Spider. To improve the performance of LLMs in the reasoning process, we study how decomposing the task into smaller sub-tasks can be effective. In particular, we show that breaking down the generation problem into sub-problems and feeding the solutions of those sub-problems into LLMs can be an effective approach for significantly improving their performance. Our experiments with three LLMs show that this approach consistently improves their simple few-shot performance by roughly 10%, pushing the accuracy of LLMs towards SOTA or surpassing it. On the holdout test set of Spider, the SOTA, in terms of execution accuracy, was 79.9 and the new SOTA at the time of this writing using our approach is 85.3. Our approach with in-context learning beats many heavily fine-tuned models by at least 5%. Additionally, when evaluated on the BIRD benchmark, our approach achieved an execution accuracy of 55.9%, setting a new SOTA on its holdout test set.
연구 동기 및 목표
- 프롬프트 기반 LLM과 미세 조정된 모델 간의 텍스트-대-SQL 벤치마크(Spider와 BIRD 등) 간의 격차를 해소하는 동기 부여.
- SQL 생성에 대한 LLM의 추론을 향상시키기 위한 분해된 다중 모듈 프롬프트 방식 제안.
- 모듈별 프롬프트(스키마 연결, 분류/해체, NatSQL 기반 생성, 자기 수정)가 성능에 미치는 영향을 조사.
- 자기 수정 프롬프트의 효과와 다양한 쿼리 난이도에 따른 적응적 프롬프트 선택의 효과를 입증
제안 방법
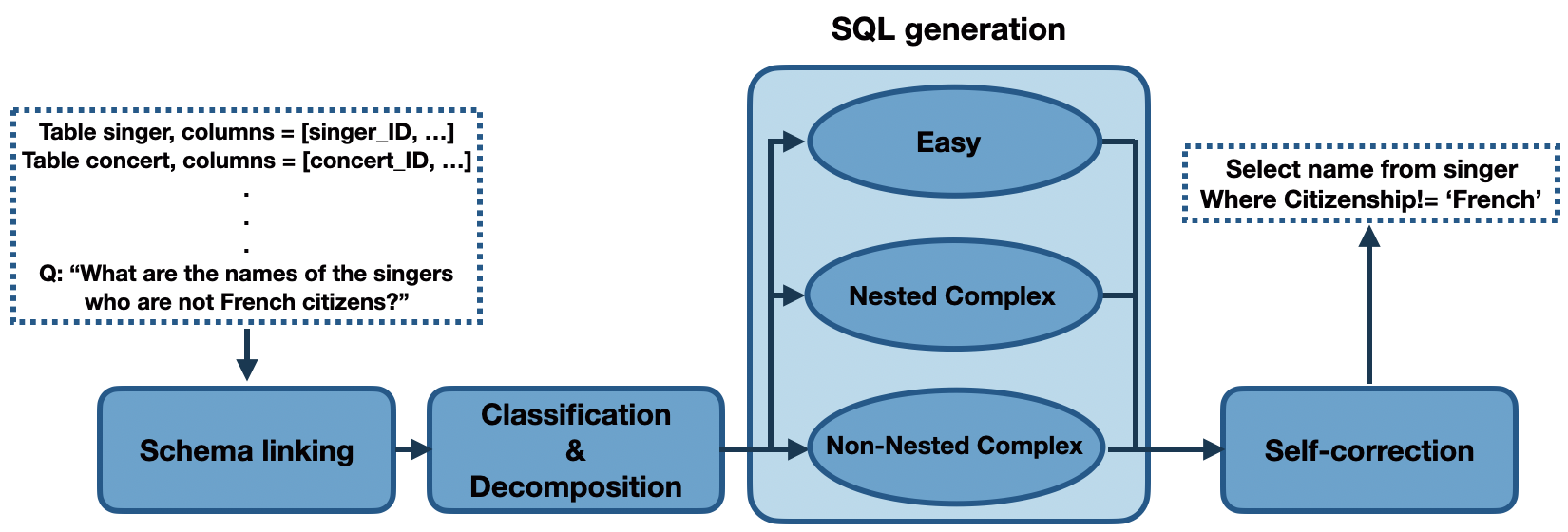
- NL2SQL 작업을 네 가지 프롬프트 기반 모듈로 분해: 스키마 연결, 분류/해체, NatSQL 중간 표현을 이용한 SQL 생성, 그리고 자체 수정 단계.
- 각 모듈과 각 쿼리 클래스에 대해 학습 데이터에서 가져온 few-shot 시연 사용.
- SQL 생성을 위한 특화 프롬프트를 선택하기 위해 쉬운 쿼리, 비중첩 복잡한 쿼리, 중첩 복잡한 쿼리의 3진 분류를 사용.
- 비중첩 복잡 쿼리에 대한 NL-대-SQL 번역을 용이하게 하기 위해 NatSQL을 중간 표현으로 채택.
- 생성 후 작은 SQL 오류를 수정하기 위한 일반적이거나 부드러운 프롬프트를 갖춘 자기 수정 모듈 적용.
- 생성 및 수정 제어를 위한 탐색적 디코딩, 0 온도, 특정 최대 토큰 설정으로 GPT-4 및 CodeX 계열으로 평가.
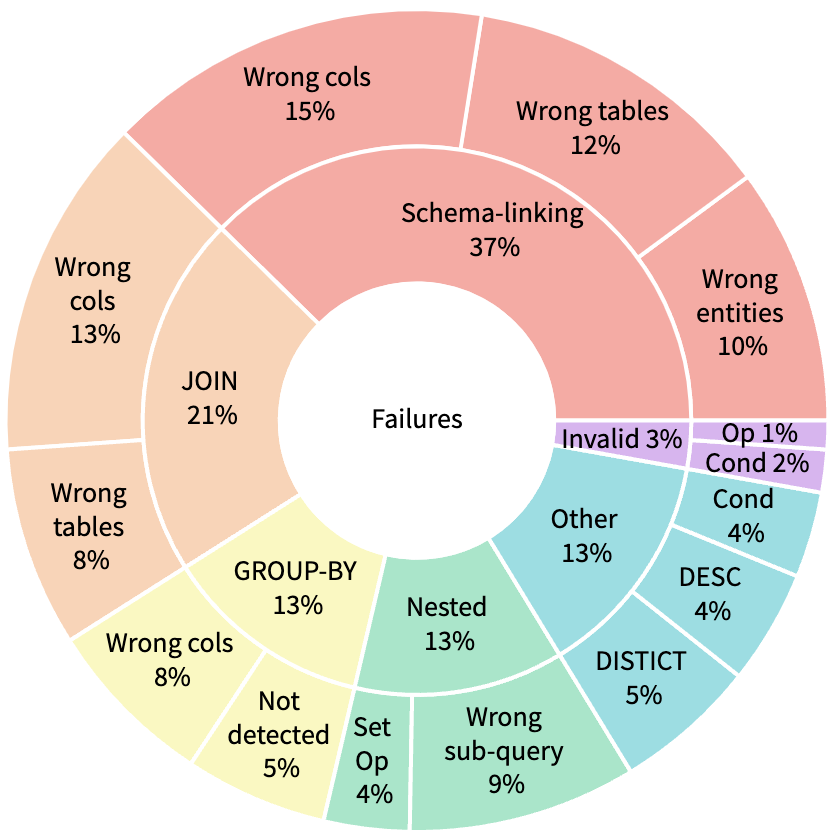
실험 결과
연구 질문
- RQ1텍스트-대-SQL을 스키마 연결, 분류/해체, 중간 표현으로 분해하는 것이 간단한 few-shot 프롬프트보다 LLM 성능을 향상시키는가?
- RQ2쿼리 난이도에 따른 적응형 프롬 prompting 및 자기 수정이 Spider와 BIRD에서 실행 및 정확 일치(EM) 정확도에 미치는 영향은 얼마인가?
- RQ3이 접근 방식이 교차 도메인 텍스트-대-SQL 벤치마크에서 미세 조정된 SOTA 방법과 어떻게 비교되는가?
- RQ4스키마 연결 및 NatSQL 중간 표현의 도입으로 조인, 중첩, 스키마 모호성 등 일반적인 실패 모드를 완화하는가?
주요 결과
| 모델 | EX (Spider Holdout) | EM (Spider Holdout) |
|---|---|---|
| DIN-SQL + GPT-4 (Ours) | 85.3 | 60 |
| DIN-SQL + CodeX Davinci (Ours) | 78.2 | 57 |
| RESDSQL-3B + NatSQL (DB content used) (Li et al., 2023a) | 79.9 | 72 |
| Graphix-3B+PICARD (DB content used) (Li et al., 2023b) | 77.6 | 74 |
| SHiP+PICARD (DB content used) (Zhao et al., 2022) | 76.6 | 73.1 |
| N-best Rerankers + PICARD (DB content used) (Zeng et al., 2022) | 75.9 | 72.2 |
| RASAT+PICARD (DB content used) (Qi et al., 2022) | 75.5 | 70.9 |
| T5-3B+PICARD (DB content used) (Scholak et al., 2021) | 75.1 | 71.9 |
| RATSQL+GAP+NatSQL (DB content used) (Gan et al., 2021) | 73.3 | 68.7 |
| RYANSQL v2 + BERT (Choi et al., 2021) | - | 60.6 |
| SmBoP + BART (Rubin and Berant, 2020) | - | 60.5 |
- GPT-4를 사용한 Spider holdout에서 실행 정확도 85.3%를 달성하며 당시 새로운 SOTA를 수립했다.
- CodeX Davinci를 사용한 Spider holdout에서 실행 정확도 78.2%를 달성했고 60%의 EM를 달성했다.
- GPT-4를 사용한 BIRD 벤치마크 holdout에서 실행 정확도 55.9%를 달성하며 새로운 SOTA를 확립했고 개발 세트에서 GPT-4로 50.72% EM을 달성했다.
- 분해된 프롬프트가 단순한 few-shot 프롬프트에 비해 LLM 전반에서 일관되게 약 10%의 성능 향상을 보여준다.
- 각 모듈이 성능에 기여하는 것을 입증한 소거 분석에서 스키마 연결은 특히 비간단 쿼리에서 뚜렷한 이득을 제공한다.
- 자기 수정 프롬프트(CodeX에 대해서는 일반적, GPT-4에 대해서는 부드럽게)가 SQL 결함을 줄이고 실행 정확도를 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.