[논문 리뷰] Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct Preference Optimization (DPO)는 명시적 보상 모델링이나 RL 없이 사람 선호로부터 언어 모델 정책을 직접 최적화합니다. 이는 PPO 기반 RLHF보다 등급이 같거나 더 나은 정렬을 달성하며 구현과 학습이 더 간단합니다.
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
연구 동기 및 목표
- 인간의 선호를 활용해 조작 가능하고 안전하며 정렬된 대형 언어 모델의 필요성을 제시한다.
- 명시적 보상 모델링이나 RL 없이 선호로부터 정책을 직접 최적화하는 새로운 패러다임을 제안한다.
- 재매개변수가 닫힌 형태의 최적 정책을 산출함을 보이고, 이를 통해 간단한 분류 손실을 가능하게 한다.
- 감정 제어, 요약, 대화와 같은 작업에서 DPO를 PPO 기반 RLHF와 비교한다.
- 6B 파라미터까지의 모델에서 DPO의 안정성, 효율성 및 확장성을 입증한다.
제안 방법
- Eq. 4를 통해 최적 정책을 닫힌 형태로 추출할 수 있도록 보상-모델 매개변수화를 도입한다.
- 보상을 r(x,y)=β log(π(y|x)/π_ref(y|x))로 재매개변수화하고 정책 출력에 대한 Bradley-Terry 기반 선호 손실(Eq. 7)을 도출한다.
- 암묵적 보상(Eq. 7)을 이용한 선호/비선호 쌍에 대한 이진 교차 엔트로피 손실을 공식화한다.
- 퇴화를 방지하기 위해 암묵적 보상 순서 오차로 손실에 가중치를 둔다(그래디언트 형태를 논의).
- 실용적인 DPO 파이프라인을 개요화한다: π_ref에서 샘플링하고, 인간 선호를 수집하며, DPO 손실로 최적화한다.
- Plackett-Luce/Bradley-Terry 모델 하에서 보상 기반 RL과 동등성에 대한 이론적 특성 및 actor-critic 방법에 비해 강건성 이점을 논의한다.
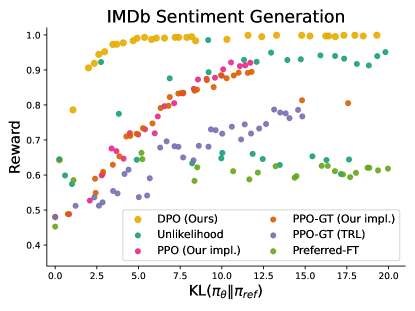
실험 결과
연구 질문
- RQ1사람의 선호로부터 정책을 직접 최적화하는 것이 작업 전반에서 PPO 기반 RLHF와 비슷하거나 이를 능가할 수 있는가?
- RQ2DPO 재매개변수화가 명시적 보상 모델링이나 RL 루프 없이도 최적 정책을 복구하는가?
- RQ3감정 제어, 요약, 대화에서 성능과 안정성 면에서 DPO가 기본 방법들과 어떻게 비교되는가?
- RQ4PPO 기반 RLHF보다 하이퍼파라미터 및 온도에 대해 DPO가 더 효율적이고 강건한가?
- RQ5Plackett-Luce/Bradley-Terry 모델 하에서 DPO의 타당성을 뒷받침하는 이론적 보장은 무엇인가?
주요 결과
- 주어진 KL 제약 경계에서 DPO가 가장 높은 보상을 달성하고, 감정 프런티어에서 PPO를 능가한다.
- 요약 및 대화 작업에서 DPO가 PPO 기반 RLHF에 비해 하이퍼파라미터 조정이 적은 수준으로 일치하거나 능가한다.
- DPO는 샘플링 온도에 대해 여전히 강건하며 강력한 성능으로 빠르게 수렴한다.
- 통제된 감정 설정에서 PPO가ground-truth 보상을 사용할 수 있어도 DPO가 PPO를 능가한다.
- 간단하고 안정적인 학습 목표를 사용하여 최대 6B 파라미터 언어 모델에서도 경쟁력 있는 성능을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.