[논문 리뷰] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
DistServe는 prefill과 decoding을 별도의 GPU로 분리하고, 자원을 공동 최적화하며, 배치를 최적화하여 TTFT 및 TPOT SLO 하에서 GPU당 높은 goodput을 달성하고 최첨단 시스템보다 우수한 성능을 보인다.
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Existing LLM serving systems colocate the two phases and batch the computation of prefill and decoding across all users and requests. We find that this strategy not only leads to strong prefill-decoding interferences but also couples the resource allocation and parallelism plans for both phases. LLM applications often emphasize individual latency for each phase: time to first token (TTFT) for the prefill phase and time per output token (TPOT) of each request for the decoding phase. In the presence of stringent latency requirements, existing systems have to prioritize one latency over the other, or over-provision compute resources to meet both. DistServe assigns prefill and decoding computation to different GPUs, hence eliminating prefill-decoding interferences. Given the application's TTFT and TPOT requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase. DistServe also places the two phases according to the serving cluster's bandwidth to minimize the communication caused by disaggregation. As a result, DistServe significantly improves LLM serving performance in terms of the maximum rate that can be served within both TTFT and TPOT constraints on each GPU. Our evaluations show that on various popular LLMs, applications, and latency requirements, DistServe can serve 7.4x more requests or 12.6x tighter SLO, compared to state-of-the-art systems, while staying within latency constraints for > 90% of requests.
연구 동기 및 목표
- LLM 서비스의 엄격한 TTFT와 TPOT 대기시간 요구사항을 최적화해야 할 필요성에 대한 동기 부여.
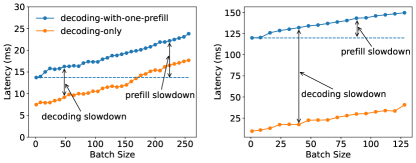
- 공동 위치의 서비스에서 prefill- dec oding 간섭과 자원 결합이 주요 병목 현상임을 확인.
- prefill와 decoding의 비분해를 제안하여 단계별 최적화를 가능하게 함.
- 실제 워크로드 하에서 GPU당 goodput을 극대화하기 위한 배치 및 스케줄링 알고리즘 개발.
- 다양한 모델과 대기시간 목표에 대해 기존 시스템과 비교하여 DistServe 평가.
제안 방법
- prefill 및 decoding 단계를 별도의 GPU로 분리하여 간섭 제거.
- TTFT 및 TPOT 요구사항에 따라 각 단계에 대해 자원 할당 및 병렬성 공동 최적화.
- 각 단계의 GPU당 goodput를 최대화하고 트래픽 속도를 복제와 함께 충족하기 위한 배치 알고리즘(높은 노드 친화도와 낮은 노드 친화도) 개발.
- 메모리 압력과 파이프라인 버블을 줄이기 위해 pull 기반 KV 캐시 전송이 포함된 온라인 스케줄링 계층 도입.
- 워크로드 인식 시뮬레이션을 사용하여 SLO 달성 예측 및 구성 검색 가이드.
- 최적화된 각 단계 구성을 더 높은 트래픽으로 확장하기 위한 복제 전략 제공.
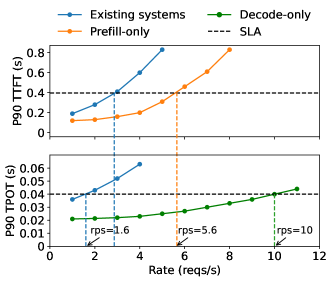
실험 결과
연구 질문
- RQ1prefill와 decoding 단계를 분리하면 TTFT 및 TPOT 제약 하에서 GPU당 좋은 처리량이 향상되는가?
- RQ2클러스터 토폴로지와 대역폭을 고려할 때 각 단계에 대해 어떤 배치 및 병렬성 구성이 GPU당 goodput를 최대화하는가?
- RQ3다양한 LLM 크기, 애플리케이션 및 대기시간 목표에 대해 DistServe는 최첨단 시스템과 어떻게 비교되는가?
- RQ4실제 배포에서의 KV 캐시 전송, 비균일 프롬프트 등의 실용적 문제점은 무엇이며 이를 어떻게 완화할 수 있는가?
- RQ5워크로드 변화에 적응하기 위한 온라인 재계획이 필요한가? 그 효과는 어떠한가?
주요 결과
- DistServe는 대기시간 제약하에서 최첨단 시스템에 비해 최대 4.48× 더 많은 요청을 처리한다.
- DistServe는 대기시간 목표를 10.2×까지 더 촘촘하게 맞출 수 있으며, 90% 이상의 요청에 대해 대기시간 목표를 만족한다.
- prefill와 decoding의 분리로 사전 채움-디코딩 간섭이 제거되고 단계별 병렬성이 가능해졌다.
- 배치 알고리즘과 복제는 각 단계의 goodput를 트래픽 속도에 맞게 효율적으로 확장한다.
- KV-캐시 전송은 메모리 압력과 파이프라인 버블을 줄이기 위해 pulling 기반으로 관리된다.
- 다양한 LLM 및 애플리케이션과 대기시간 요구에도 성능 향상이 일관되게 나타난다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.