[논문 리뷰] Divergence-Augmented Policy Optimization
정책 최적화에 발산 증강(divergence augmentation)을 도입하여 강화학습 목표에 발산 기반 정규화 항을 추가하고, 상태-행동 분포 간의 브레그만 발산으로부터 도출되며 Atari에서 데이터가 희소한 오프폴리시 재사용에서 성능이 향상됨을 보인다.
In deep reinforcement learning, policy optimization methods need to deal with issues such as function approximation and the reuse of off-policy data. Standard policy gradient methods do not handle off-policy data well, leading to premature convergence and instability. This paper introduces a method to stabilize policy optimization when off-policy data are reused. The idea is to include a Bregman divergence between the behavior policy that generates the data and the current policy to ensure small and safe policy updates with off-policy data. The Bregman divergence is calculated between the state distributions of two policies, instead of only on the action probabilities, leading to a divergence augmentation formulation. Empirical experiments on Atari games show that in the data-scarce scenario where the reuse of off-policy data becomes necessary, our method can achieve better performance than other state-of-the-art deep reinforcement learning algorithms.
연구 동기 및 목표
- 오프폴리시 데이터를 재사용할 때 정책 최적화를 안정화하려는 동기를 제시한다.
- 발산 증강(divergence augmentation)을 상태-행동 분포 발산에 기반한 정규화로 도입한다.
- 브레그만 발산(Bregman divergence)과 미러 디센트(mirror descent) 원리로부터 방법을 도출한다.
- 발산 증강 업데이트에 대한 실용적인 기울기 기반 최적화 체계를 제안한다.
제안 방법
- 현재 상태-행동 분포와 이전 상태-행동 분포 사이의 Bregman 발산을 사용하여 divergence augmentation을 정의한다.
- 발산 증강을 KL 기반 업데이트 및 미러 디센트 기반 최적화와 연관시킨다.
- 정책 손실의 기울기(∇_θ L_pi) 및 ∇_θ D_F 항을 포함하여 divergence augmentation을 포함하는 기울기 표현식을 도출한다.
- 오프 폴리시 데이터에 대해 V-trace를 통해 Q값과 발산 항을 추정한다.
- 그라디언트 기반 업데이트를 구현한다: theta <- theta - alpha_t (grad_theta L_pi + b grad_theta L_v).
- 경험 궤적 수집, 오프폴리시 샘플링, 그리고 그래디언트 업데이트를 번갈아 수행하는 실용 알고리즘(DAPO)을 제공한다.
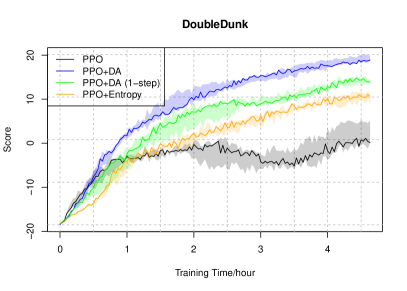
실험 결과
연구 질문
- RQ1오프폴리시 데이터를 재사용할 때 divergence augmentation이 정책 최적화를 안정화하는가?
- RQ2상태-행동 분포 간의 Bregman 발산을 정책 기울기 업데이트에 어떻게 통합할 수 있는가?
- RQ3데이터가 희소한 강화학습 설정에서 발산 증강이 성능에 미치는 영향은 무엇인가?
- RQ4DAPO가 PPO, TRPO, MPO, MARWIL 등 기존 방법과 어떤 관련이 있고 어떤 점에서 차이가 있는가?
주요 결과
- 데이터가 희소한 상황에서 DAPO는 표준 PPO보다 성능을 향상시킬 수 있다.
- 발산 증강은 상태-행동 공간에 브레그만 발산 제약을 부과하는 것에 해당한다.
- 발산 항의 기울기를 정책 기울기 방법과 유사한 Q-연산자로 추정할 수 있다.
- 언급된 Atari 실험에 따라 오프폴리시 데이터를 재사용할 때 발산 증강이 도움이 된다.
- 이 접근법은 온라인 미러 디센트에 연결되며 KL 기반 정책 업데이트를 일반화한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.