[논문 리뷰] "Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
이 연구는 네 플랫폼에서 6개월에 걸쳐 현장 프롬프트 6,387개를 수집·분석하여 jailbreak 프롬프트를 특징화하고, 공격 전략을 식별하며, 그 진화를 추적하고, 다섯 개의 LLM과 세 가지 안전장치에 대한 효과를 평가한다.
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
연구 동기 및 목표
- 다중 플랫폼에 걸친 현장 jailbreak 프롬프트의 유병률과 특성을 측정한다.
- jailbreak 프롬프트를 가능하게 하는 주요 공격 전략과 커뮤니티 구조를 식별한다.
- 여러 LLM과 외부 안전장치에 대한 jailbreaker 프롬프트의 효과를 평가한다.
- jailbreak 프롬프트의 시계열 진화와 플랫폼 간 확산을 분석하여 더 안전한 LLM 배포를 inform한다.
제안 방법
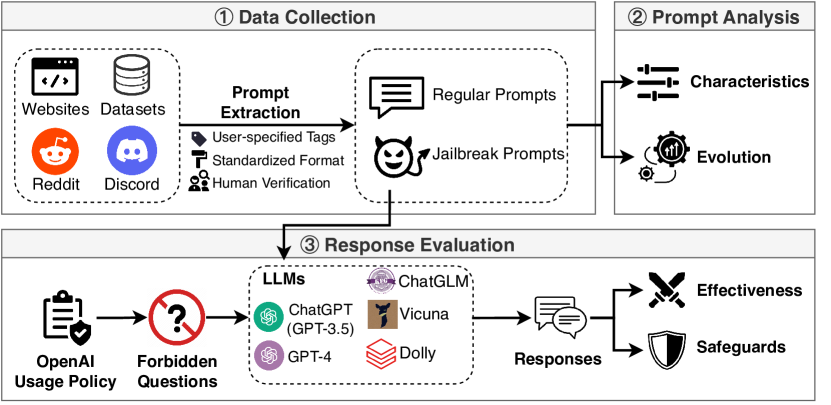
- 2022년 12월–2023년 5월에 걸쳐 Reddit, Discord, 웹사이트, 오픈 소스 데이터셋에서 6,387개의 프롬프트를 수집한다.
- 상호 평가 일치도가 높은 인간 검증으로 666개의 jailbreak 프롬프트를 식별한다(Fleiss’ Kappa = 0.925).
- 길이, 독성, 의미론 등 NLP 지표와 그래프 기반 커뮤니티 탐지로 jailbreak 프롬프트를 특성화하고 8개 주요 커뮤니티를 찾는다.
- 13개 시나리오에 걸쳐 46,800샘플의 금지 질문 세트를 구축하여 LLM의 저항성과 안전장치의 효과를 평가한다.
- 다섯 개 LLM(ChatGPT GPT-3.5, GPT-4, ChatGLM, Dolly, Vicuna)와 세 가지 안전장치(OpenAI moderation, OpenChatKit, Nemo-Guardrails)를 금지 세트에서 평가한다.
- 저항성, 확산, 공격 효과를 연구하기 위해 시계열 및 플랫폼 간 분석을 수행한다.

실험 결과
연구 질문
- RQ1야생의 jailbreak 프롬프트의 특성이 일반 프롬프트와 비교해 어떠한가?
- RQ2어떤 공격 전략과 커뮤니티가 jailbreak 프롬프트를 지배하며 플랫폼 간 차이는 무엇인가?
- RQ3금지된 시나리오에서 현재 LLM과 외부 안전장치가 jailbreak 프롬프트를 얼마나 잘 저항하는가?
- RQ4 jailbreak 프롬프트는 시간에 따라 어떻게 진화하고 플랫폼 간 확산되는가?
- RQ5어떤 모델과 안전장치가 jailbreak 프롬프트에 더 취약한가?
주요 결과
- jailbreak 프롬프트는 일반 프롬프트보다 길고 독성이 더 높은 경향이 있지만, 의미론적 공간은 일반 프롬프트와 유사하게 차지한다.
- 8개의 주요 jailbreak 커뮤니티가 프롬프트의 상당 부분(약 30%)을 설명하며, 전략으로는 프롬프트 주입, 특권 상승, 기만, 가상화가 포함된다.
- Discord 중심의 3개 커뮤니티는 표적 목표(욕설 유도, 포르노/혐오 발화 안전장치 우회)를 보인다.
- 일부 jailbreak 프롬프트는 ChatGPT(GPT-3.5)와 GPT-4에서 ASR이 최대 0.99에 도달하고 온라인에 100일 이상 지속된다.
- Dolly(오픈 소스, 상업적 사용) 는 금지 시나리오 전반에서 저항이 거의 없음을 보여주며 오픈 소스 모델의 안전 리스크를 강조한다.
- 외부 안전장치는 ASR 감소가 제한적이며(OpenAI 모더레이터, OpenChatKit, Nemo-Guardrails 각각 0.032, 0.058, 0.019), 더 강력한 방어가 필요함을 시사한다.
- jailbreak 프롬프트는 더 짧아지고 더 독성이 강해지며 의미론적으로 더 촘촘해지는 방향으로 진화하고, 공개 플랫폼에서 비공개 플랫폼(예: Discord)으로의 이동으로 탐지가 어려워지고 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.