[논문 리뷰] DocLLM: A layout-aware generative language model for multimodal document understanding
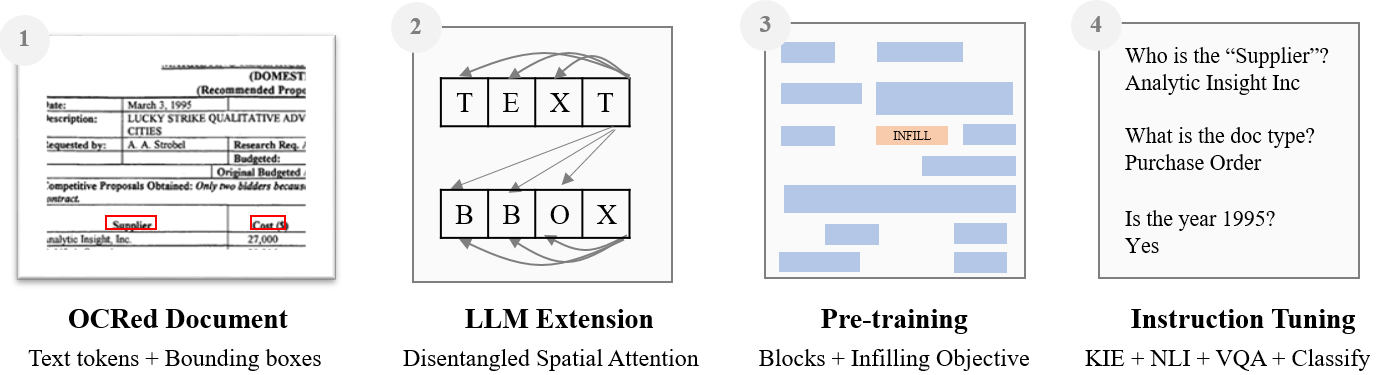
DocLLM은 시각 문서에서 텍스트와 레이아웃을 함께 모델링하기 위해 해상 분리된 공간 주의(attention)로 인과적 LLM을 확장하고, 블록 인필링 사전 학습과 지시 튜닝을 사용하여 무거운 비전 인코더 없이도 VRDU 작업에서 뛰어난 성능을 발휘합니다.
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
연구 동기 및 목표
- 레이아웃과 텍스트 의미가 서로 얽혀 있는 시각적으로 풍부한 문서를 이해하는 도전과제를 동기 부여하고 다루기.
- 무거운 비전 인코더 없이도 공간 레이아웃을 통합한 경량 모델을 개발합니다.
- 텍스트와 경계 상자 정보를 교차 모달 의존성을 포착하기 위한 해상도 분리형 공간 주의 메커니즘을 제안합니다.
- 비정형 레이아웃과 정렬이 맞지 않는 텍스트를 처리하기 위한 블록 수준의 인필링 사전 학습 목표를 도입합니다.
- 다수의 DocAI 태스크에 걸친 지시 튜닝 데이터로 모델을 미세 조정하여 강력한 제로샷 일반화를 가능하게 합니다.
제안 방법
- 경계 상자를 통해 공간 레이아웃을 나타내는 두 번째 모달리티를 추가하여 인과적 디코더 LLM을 확장합니다.
- 텍스트-텍스트, 텍스트-공간, 공간-텍스트, 공간-공간 점수를 각각의 전용 투영으로 계산하는 해상도 분리형 공간 주의(attention)를 구현합니다.
- 랜덤 텍스트 블록을 마스킹하고 선행 및 후행 컨텍스트를 모두 사용해 재구성하도록 모델을 학습시키는 블록 인필링 사전 학습 목표를 도입합니다.
- 총 3.8B 토큰과 16.7M 페이지의 IIT-CDIP 및 DocBank 문서 컬렉션에서 사전 학습합니다.
- VQA, NLI, KIE, CLS를 포괄하는 16개의 DocAI 데이터셋에 대해 지시 튜닝을 수행하여 제로샷 성능을 향상시킵니다.
- 레이아웃 집중형 및 문서 이해 태스크에 초점을 맞추고 제로샷 및 지시 튜닝 기반의 기준선과 비교합니다.
실험 결과
연구 질문
- RQ1레이아웃 정보를 경계 상자를 통해 보강한 경량 LLM이 비전 인코더 없이도 VRDU 성능에서 경쟁력을 달성할 수 있는가?
- RQ2해상도 분리형 주의에서 공간 모달리티와 텍스트 모달리티의 분리가 시각적으로 풍부한 문서에서의 교차 모달 추론을 개선하는가?
- RQ3블록 수준의 인필링 사전 학습이 문서의 비정형 레이아웃과 정렬되지 않은 텍스트를 더 잘 다루는가?
- RQ4지시 튜닝 이후 DocLLM이 보지 못한 데이터셋 및 핵심 DocAI 태스크에 얼마나 잘 일반화하는가?
주요 결과
- DocLLM-7B는 SDDS 설정의 16개 데이터셋 중 12개에서 최첨단 성능을 달성하며, 여러 기준선 중 일부 멀티모달 LLM보다 우수합니다.
- DocLLM-7B와 DocLLM-1B는 비전 인코더가 없는 기준선 대비 강력한 이점을 보이며 다수의 태스크에서 GPT-4 OCR에 대해 경쟁력 있는 결과를 보였고, 일부 VQA 사례에서 GPT-4가 선두를 차지했습니다.
- 모델은 특히 KIE 및 CLS와 같은 레이아웃 집중형 태스크에서 뛰어나며, STDD 설정에서 보류된 데이터셋으로의 일반화가 좋음을 보여줍니다.
- 16개의 DocAI 데이터셋에 대한 지시 튜닝은 VQA, KIE, CLS, NLI 태스크에서 제로샷 일반화를 향상시킵니다.
- 더 작은 DocLLM-1B도 7B 변종에 근접한 성능을 달성하여 아키텍처 설계로 인한 효율성 이점을 시사합니다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.