[논문 리뷰] Dota 2 with Large Scale Deep Reinforcement Learning
OpenAI Five가 PPO를 사용한 159M-파라미터 LSTM 정책으로 대규모 self-play 강화학습 에이전트를 훈련했고, 수천 대의 GPU에 걸쳐 10개월에 걸친 훈련 기간을 거쳤으며, Dota 2 세계 챔피언(OG)을 물리치는 동시에 인간에 비해 99.4%의 승률을 달성했다. 또한 지속적 학습을 위한 수술(surgery)을 도입하고 배치 사이즈, 데이터 품질, 그리고 장기적 크레딧 할당에 대해 분석했다.
On April 13th, 2019, OpenAI Five became the first AI system to defeat the world champions at an esports game. The game of Dota 2 presents novel challenges for AI systems such as long time horizons, imperfect information, and complex, continuous state-action spaces, all challenges which will become increasingly central to more capable AI systems. OpenAI Five leveraged existing reinforcement learning techniques, scaled to learn from batches of approximately 2 million frames every 2 seconds. We developed a distributed training system and tools for continual training which allowed us to train OpenAI Five for 10 months. By defeating the Dota 2 world champion (Team OG), OpenAI Five demonstrates that self-play reinforcement learning can achieve superhuman performance on a difficult task.
연구 동기 및 목표
- Dota 2의 복잡하고 장기적이며 부분 관찰 환경으로 강화학습을 확장한다.
- 진화하는 게임 버전과 함께 장기간 실행되는 실험을 가능하게 하는 분산형 지속 학습 시스템을 개발한다.
- 전체 재학습 없이 학습한 정책을 환경 변화에 맞게 보존하고 적응시키는 수술적 전이(surgical transfer)를 탐구한다.
- OpenAI Five Arena에서 인간 선수 대비 일반화를 평가하고 Dota 2 세계 챔피언을 물리침으로써 초인적 성능을 시연한다.
제안 방법
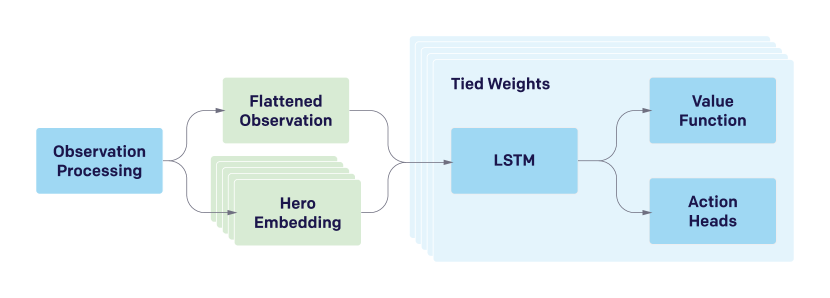
- 중앙 4096-unit LSTM을 갖는 재귀 정책과 다섯 영웅에 대한 개별 액터-크리틱 헤드를 포함하는 일반화된 이점 추정(GAE)과 함께 Proximal Policy Optimization(PPO)을 사용한다.
- 고차원 관측 공간을 GPU에 렌더링 픽셀 입력을 제공하는 대신 컴팩트 벡터로 처리한다.
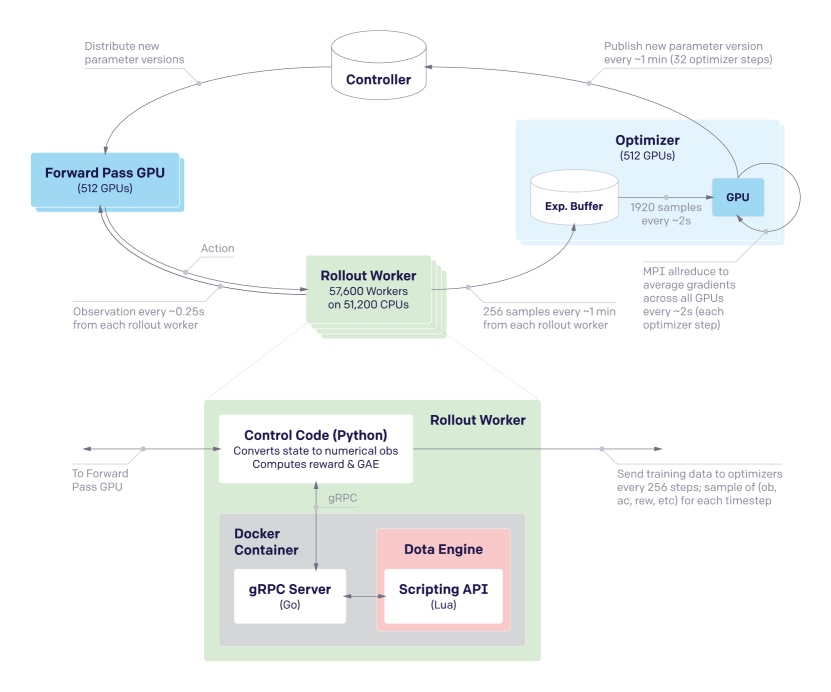
- 1536개의 GPU까지의 비동기 롤아웃-최적화 루프를 운영하여 업데이트당 총 배치 크기를 약 2.95백만 타임스텝으로 달성한다.
- 롤아웃(게임 플레이를 CPU에서), 순방향 패스 GPU(정책 샘플링), 최적화 GPU(그래디언트 업데이트)로 세 가지 훈련 인프라를 제어한다.
- 환경, 관찰 공간 또는 작용 공간의 변동에 맞춰 재학습 없이 사전 학습된 정책을 적응시키는 지속적 전이 메커니즘인 수술(surgery)을 구현한다.
실험 결과
연구 질문
- RQ1자체 학습 강화학습이 Dota 2처럼 매우 복잡하고 장기적이며 부분 관찰 게임에서 마스터하여 초인간 성능을 달성할 수 있는가?
- RQ2대규모 RL에서 배치 크기, 데이터 품질, 비동기 데이터 파이프라인이 학습 속도와 최종 성능에 어떤 영향을 미치는가?
- RQ3성능 저하 없이 환경 및 게임 버전 변화에 걸친 지속적 전이를 가능하게 하는 메커니즘(수술)은 무엇인가?
- RQ4Dota 2와 같은 매우 긴 수평의 작업에서 장기 크레딧 할당이 얼마나 학습되고 활용될 수 있는가?
- RQ5에이전트의 성능이 시간에 걸쳐 전문 인간 선수 및 팀과 어떻게 비교되는가?
주요 결과
- OpenAI Five가 Dota 2 세계 챔피언(Team OG)을 3전 2선승제로 물리쳤다(2-0).
- OpenAI Five가 OpenAI Five Arena에서 인간 선수들에 대해 7,000건이 넘는 온라인 게임에서 99.4%의 승률을 기록했다.
- 에이전트는 게임 이벤트에 평균 약 217 ms 만에 반응할 수 있다.
- 배치 크기를 늘리면 속도 향상이 나타났지만(예: Rerun 실험에서 2.5배 속도 향상) 초기 학습 단계에서 속도 향상은 비선형적이었다.
- 데이터 품질 요인(노후화, 샘플 재사용)이 학습 속도와 최종 성능에 중요한 영향을 미친다; 노후화를 0–1에 가깝게 유지하고 샘플 재사용을 최소화하는 것이 중요하다.
- 장기 수평 계획의 이점이 나타났으며, 더 긴 수평으로 재학습을 재개하면 승률이 향상되지만 아주 높은 수평에서 수익이 감소하는 구간이 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.