[논문 리뷰] DSSD : Deconvolutional Single Shot Detector
DSSD는 Residual-101을 사용한 SSD에 deconvolutional encoder-decoder 컨텍스트를 추가하여 VOC2007에서 81.5% mAP, COCO에서 33.2% mAP를 달성하고 기존의 단일 네트워크 검출기보다 우수합니다.
The main contribution of this paper is an approach for introducing additional context into state-of-the-art general object detection. To achieve this we first combine a state-of-the-art classifier (Residual-101[14]) with a fast detection framework (SSD[18]). We then augment SSD+Residual-101 with deconvolution layers to introduce additional large-scale context in object detection and improve accuracy, especially for small objects, calling our resulting system DSSD for deconvolutional single shot detector. While these two contributions are easily described at a high-level, a naive implementation does not succeed. Instead we show that carefully adding additional stages of learned transformations, specifically a module for feed-forward connections in deconvolution and a new output module, enables this new approach and forms a potential way forward for further detection research. Results are shown on both PASCAL VOC and COCO detection. Our DSSD with $513 \times 513$ input achieves 81.5% mAP on VOC2007 test, 80.0% mAP on VOC2012 test, and 33.2% mAP on COCO, outperforming a state-of-the-art method R-FCN[3] on each dataset.
연구 동기 및 목표
- 더 큰 규모의 컨텍스트 정보를 주입함으로써 일반 물체 탐지 성능을 향상시키려는 동기.
- SSD에서 더 깊은 백본(VGG 대신 Residual-101)을 도입해 정확도를 높이는 연구.
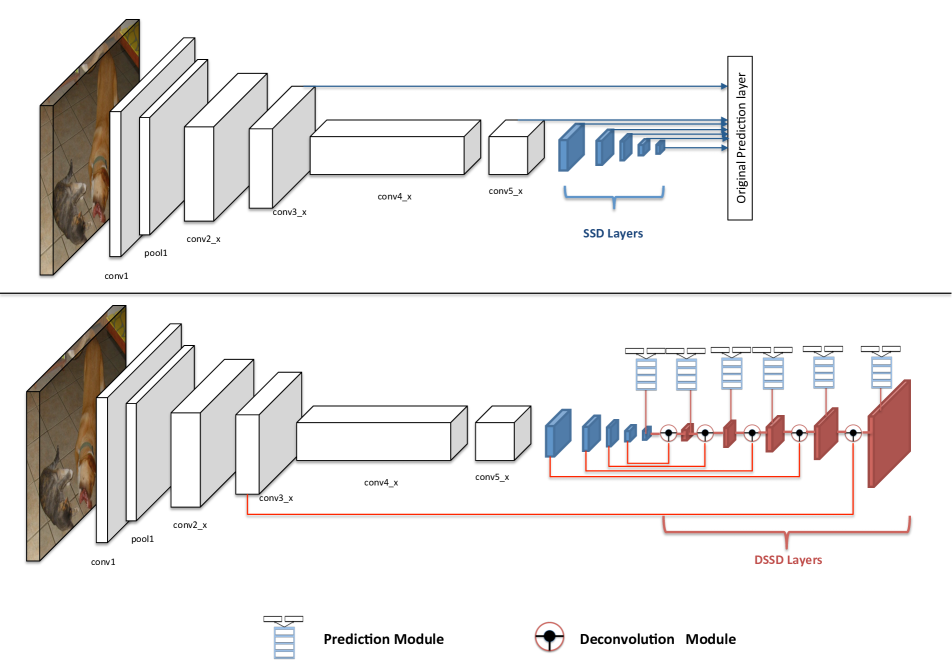
- 시맨틱 컨텍스트를 후속 예측 층으로 전달하기 위한 deconvolution 기반의 hourglass 모듈을 개발합니다.
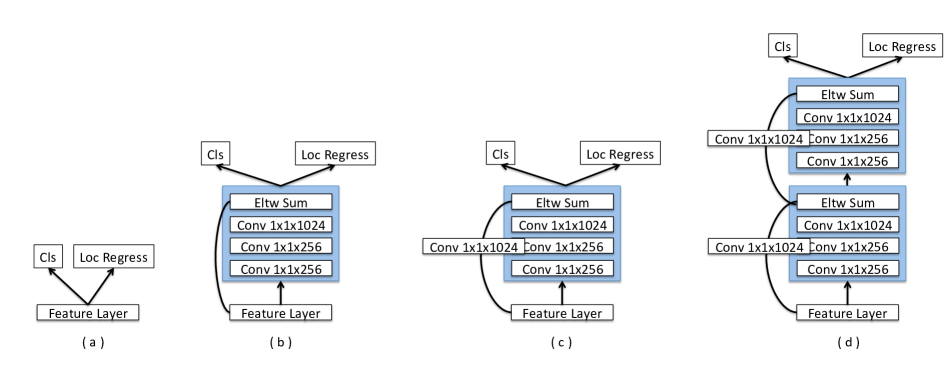
- 예측 모듈과 deconvolution 모듈을 도입해 학습을 안정화하고 작은 객체 탐지 성능을 향상시킵니다.
제안 방법
- SSD의 기본 네트워크로 VGG를 Residual-101로 교체하여 특징 품질을 개선합니다.
- 잔차 블록을 포함한 예측 모듈을 추가해 예측 층을 강화하고 학습을 안정화합니다.
- SSD 뒤에 deconvolution 층을 붙여 비대칭 인코더-디코더(hourglass) 네트워크를 형성합니다.
- 배치 정규화 및 학습된 업샘플링을 갖춘 deconvolution 모듈을 도입하고 이를 요소별 곱으로 결합하여 컨텍스트 융합을 수행합니다.
- 고수준 컨텍스트를 더 세밀한 해상도 특성 맵으로 전달하기 위한 스킵 커넥션을 사용하여 DSSD를 생성합니다.
- 먼저 SSD를 고정하고 deconvolution 사이드를 학습한 뒤 전체 네트워크를 미세 조정하는 두 단계 학습을 수행하고, SSD와 유사한 데이터 증강 및 기본 박스의 종횡비를 조정합니다.
실험 결과
연구 질문
- RQ1SSD에 deconvolution 기반 인코더-디코더(hourglass) 구조를 추가하면 특히 작은 물체의 정확도가 향상될 수 있는가?
- RQ2VGG를 Residual-101로 대체하고 예측 모듈을 도입하면 속도를 희생하지 않으면서 VOC/COCO 탐지 성능이 향상되는가?
- RQ3deconvolution 모듈에서 서로 다른 특징 융합 전략(합산 vs 곱하기)이 탐지 정확도에 어떤 영향을 주는가?
- RQ4두 단계 학습 전략(백본 고정 후 전체 미세 조정)이 수렴 및 최종 성능에 어떤 영향을 미치는가?
주요 결과
- Residual-101 및 deconvolution 층을 갖춘 DSSD가 SSD보다 더 높은 정확도를 달성하고 VOC 및 COCO에서 경쟁적인 최첨단 방법과 비슷한 성능을 보입니다.
- 예측 모듈과 deconvolution 모듈이 특히 작은 객체와 컨텍스트 특화 클래스에서 mAP를 크게 향상시킵니다.
- deconvolution 모듈의 요소별 곱 융합이 테스트된 융합 방법 중 최상의 정확도를 제공합니다.
- VOC2007에서 513 입력의 DSSD가 81.5% mAP를 달성하여 R-FCN 및 SSD 변형과 같은 기존의 단일 네트워크 검출기를 능가합니다.
- VOC2012에서 DSSD는 80.0% mAP를 달성하고 COCO에서 DSSD 513은 33.2% mAP에 도달하여 교차 데이터셋 성능이 강함을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.