[논문 리뷰] Dynamic Grained Encoder for Vision Transformers
동적 그레인 인코더(DGE)가 비전 트랜스포머에서 영역 의존적 쿼리 수를 할당하여 계산량을 40-60% 감소시키면서 정확도를 유지하고 특정 작업에서 성능을 향상시킵니다.
Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
연구 동기 및 목표
- 비전 트랜스포머의 공간적 중복성을 Exploit하여 이미지 영역의 정보성이 다양한 영역을 활용하는 동기를 제공한다.
- 다이나믹하고 영역 기반의 라우터를 제안하여 혼합 그레노랄리티 패치를 희소 쿼리로 할당한다.
- 표준 비전 트랜스포머 블록과 엔드-투-엔드 학습 가능성을 보장한다.
- 이미지 분류, 물체 탐지, 의미 분할 전반에 걸친 효율-정확도 트레이드를 시연한다.
제안 방법
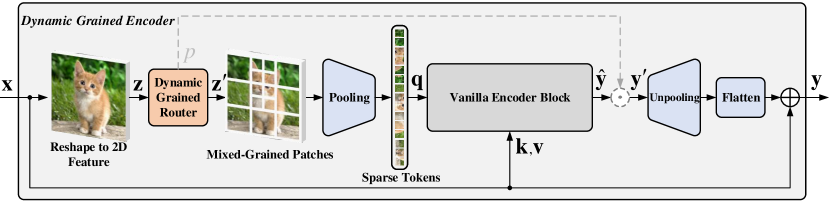
- 표준 인코더를 동적 그레인 라우터와 일반 인코더 블록으로 대체하는 Dynamic Grained Encoder(DGE)를 도입한다.
- 2D 피처를 고정된 SxS 영역으로 분할하고 게이트 네트워크를 통해 후보 세트 Φ에서 영역별 그레너리티를 선택한다.
- 선택된 그레너리티의 패치를 평균 풀링하여 트랜스포머를 위한 희소 쿼리로 영역 토큰을 계산한다.
- 언풀링으로 원래 해상도로 출력을 복원하고 잔여 연결과 융합한다.
- 원하는 계산 비율 γ를 목표로 하는 예산 제약과 함께 Gumbel-Softmax 기반의 확률적 게이팅으로 학습한다.
- 선택적으로 영역별 또는 층별 라우팅을 허용하며, 영역별 게이팅은 성능 향상을 보인다.
실험 결과
연구 질문
- RQ1비전 트랜스포머가 영역 적응형 혼합 그레노랄리티 쿼리를 사용하여 상당한 계산량 절감을 달성할 수 있는가?
- RQ2데이터 의존적 라우팅 전략이 분류, 탐지, 분할 작업에서 정확도와 효율성에 어떤 영향을 미치는가?
- RQ3영역별 동적 그레너리티가 비전 트랜스포머에서 층별 동적 제어보다 더 효과적인가?
- RQ4계산 예산 제약이 모델 성능과 속도에 어떤 영향을 미치는가?
- RQ5DGE가 서로 다른 백본 아키텍처(DeiT, PVT, DPVT) 및 다운스트림 작업에 얼마나 잘 일반화되는가?
주요 결과
| Framework | Dynamic | Region | Φ | Top1 Acc | Top5 Acc | FLOPs | #Param |
|---|---|---|---|---|---|---|---|
| PVT-S | - | - | - | 80.2 | 95.2 | 6.2G | 28.2M |
| PVT-S+DGE | ✓ | - | 1, 2, 4 | 80.2 | 95.0 | 3.5G | +12.1K |
| PVT-S+DGE | ✓ | - | 1, 2 | 80.0 | 95.0 | 3.5G | +8.1K |
- 이미지 분류에서 Dynamic Grained Encoder가 FLOPs를 약 40-60% 감소시키면서도 유사한 정확도를 유지한다.
- 예산 제약이 있는 DGE는 구성에 따라 대략 절반의 계산으로 유사하거나 더 나은 정확도를 달성할 수 있다.
- 영역별 라우팅은 비슷한 복잡도에서 층별 라우팅보다 약 1.1%의 절대 이득을 제공한다.
- 전경 영역에는 더 많은 쿼리가 할당되어 문제가 가장 중요한 곳에서 세밀한 표현력을 가능하게 한다.
- DGE는 백본 전반에 걸쳐 하류 작업 성능(객체 탐지 및 의미 분할)을 향상시키고 FLOPs 감소를 크게 달성한다.
- ADE-20K에서 DPVT/PVT와 함께 DGE를 사용하면 상당한 FLOPs 감소(약 30%까지)와 함께 경쟁력 있는 mIoU를 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.