[논문 리뷰] Dynamic Head: Unifying Object Detection Heads with Attentions
Introduces Dynamic Head (DyHead), a unified detection head that stacks scale-, spatial-, and task-aware attention modules to improve object detection without extra computational overhead, achieving state-of-the-art COCO results.
The complex nature of combining localization and classification in object detection has resulted in the flourished development of methods. Previous works tried to improve the performance in various object detection heads but failed to present a unified view. In this paper, we present a novel dynamic head framework to unify object detection heads with attentions. By coherently combining multiple self-attention mechanisms between feature levels for scale-awareness, among spatial locations for spatial-awareness, and within output channels for task-awareness, the proposed approach significantly improves the representation ability of object detection heads without any computational overhead. Further experiments demonstrate that the effectiveness and efficiency of the proposed dynamic head on the COCO benchmark. With a standard ResNeXt-101-DCN backbone, we largely improve the performance over popular object detectors and achieve a new state-of-the-art at 54.0 AP. Furthermore, with latest transformer backbone and extra data, we can push current best COCO result to a new record at 60.6 AP. The code will be released at https://github.com/microsoft/DynamicHead.
연구 동기 및 목표
- 객체의 스케일, 공간 및 작업Variations를 다루는 단일 탐지 헤드의 필요성을 동기화한다.
- 대표 표현을 개선하기 위해 세 가지 특징 차원에서 주의를 적용하는 다이내믹 헤드를 제안한다.
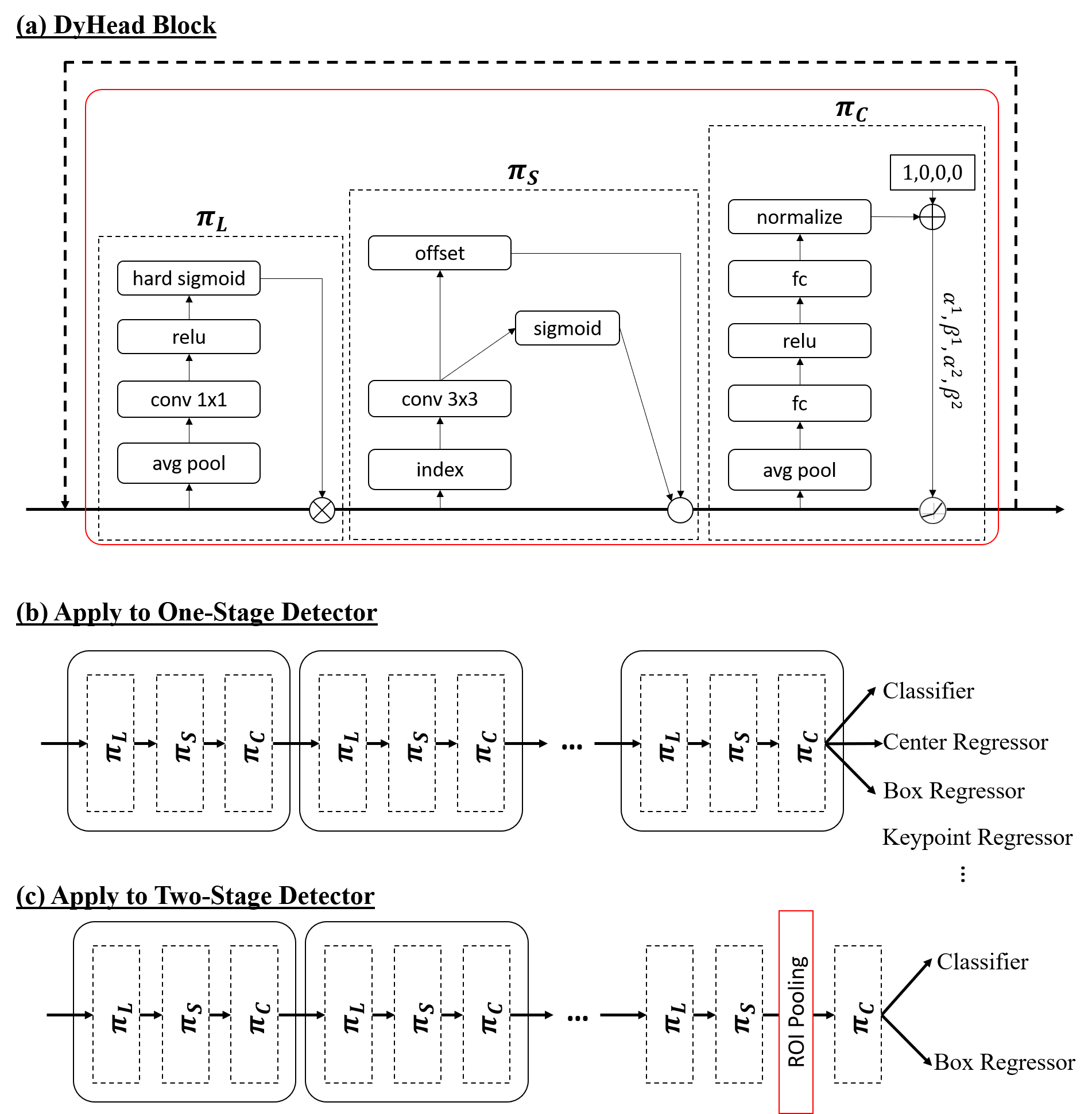
- DyHead를 서로 다른 탐지기(1단계 및 2단계)와 백본에 플러그인 형태로 적용할 수 있음을 보여준다.
- 효율적인 학습으로 COCO에서 DyHead가 상당한 AP 향상을 가져다 줌을 입증한다.
- 주의 모듈의 기여도와 기존 탐지기에 대한 일반화를 분석한다.
제안 방법
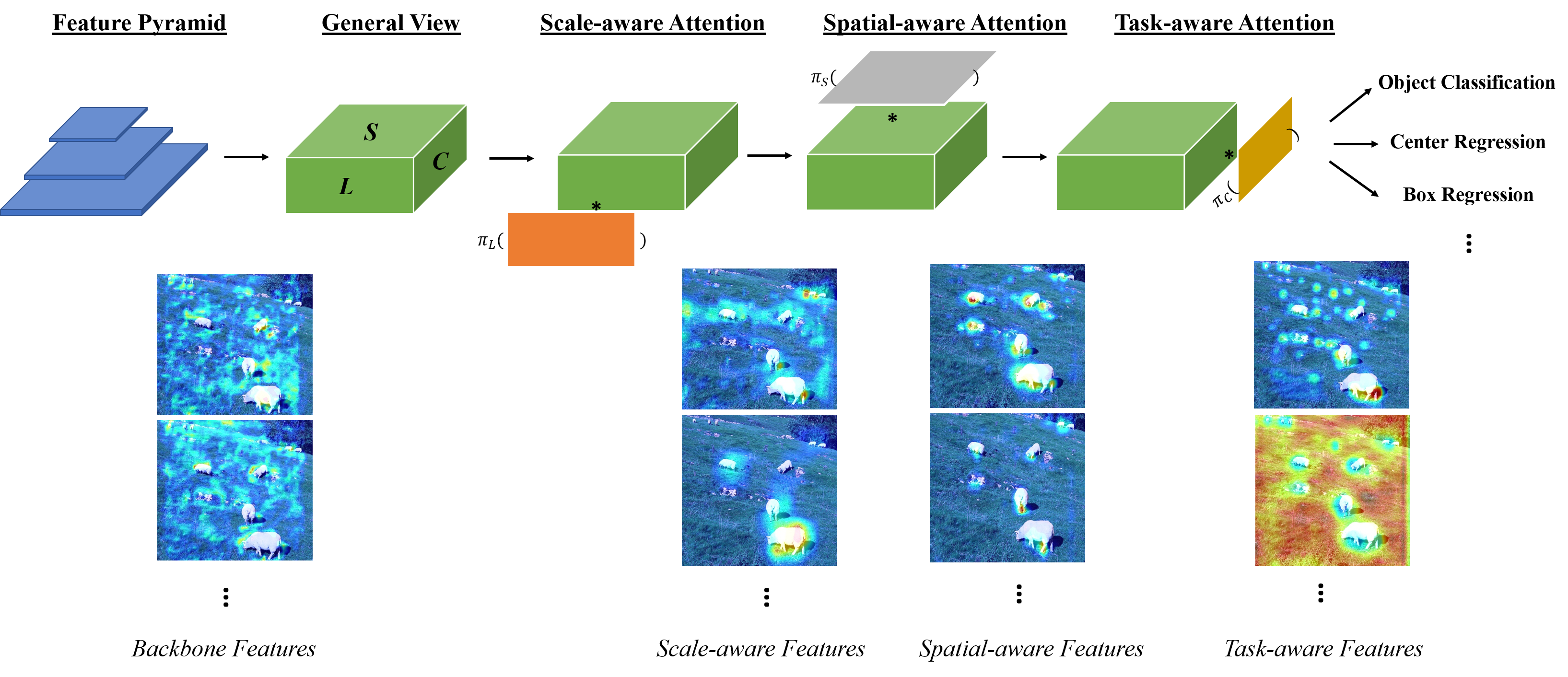
- 백본 출력은 L x S x C 형상의 3D 특징 텐서 F로 표현된다(레벨 x 공간 위치 x 채널).
- 전체 자기-주의를 L, S, C에서 각각 작동하는 세 가지 순차적인 주의로 분해하여 스케일-공간-작업 인식을 강제한다.
- Scale-aware attention: S와 C를 평균화한 뒤 1x1 conv를 통해 레벨별 가중치를 계산하고 hard-sigmoid 활성화를 따른다.
- Spatial-aware attention: 학습된 오프셋 및 중요도와 함께 변형 가능한 샘플링을 사용하여 식별 가능한 공간 영역에 희소하게 집중하고, 레벨 간 합산한다.
- Task-aware attention: 학습된 임계치를 통한 채널별 게이팅을 적용하여 분류, 경계 상자 회귀, 중심/키포인트 학습 등 다양한 작업에 유리하도록 한다.
- 다양한 탐지기 아키텍처에 맞게 DyHead를 플러그인 블록으로 적용하기 위해 여러 DyHead 블록을 쌓아 표현을 점진적으로 정제한다.
실험 결과
연구 질문
- RQ1스케일-공간-작업 인식 주의를 동시에 처리하는 단일 탐지 헤드가 서로 다른 탐지기와 백본에서 성능을 향상시키는가?
- RQ2개별 주의 구성요소(스케일, 공간, 작업)가 성능 향상에 얼마나 기여하며, 쌓았을 때 어떤 상호작용이 나타나는가?
- RQ3DyHead가 계산 효율적이어서 기존 헤드보다 학습 속도를 앞설 수 있으며 최첨단 정확도를 제공하는가?
- RQ4DyHead가 한 단계 및 두 단계 탐지기, 앵커 기반/앵커 프리/박스 기반/키포인트 기반 표현 전반에 대해 일반화되는가?
주요 결과
- DyHead는 기반 탐지기에 스케일-공간-작업 인식 모듈을 추가할 때 일관된 AP 이득을 제공한다(예: L, S, C 모듈에 대해 각각 AP가 0.9, 2.4, 1.3 만큼 증가).
- 전체 DyHead(세 가지 주의 모두 쌓음)는 기준선 대비 3.6 AP 향상을 달성한다.
- ResNeXt-101-DCN에서 DyHead는 COCO test-dev에서 54.0 AP를 달성하고, 트랜스포머 백본 및 추가 데이터로 COCO 결과가 60.6 AP에 도달한다.
- DyHead를 여러 탐지기(Faster R-CNN, RetinaNet, ATSS, FCOS, RepPoints)에 플러그인하면 AP가 전반적으로 약 1.2–3.2 포인트 향상된다.
- DyHead는 효율성을 입증한다: 2-block 구성만으로도 기준선을 능가하며 더 깊은 구성을 통해 비용/편익이 우수한 트레이드오프를 유지한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.