[논문 리뷰] Edit Probability for Scene Text Recognition
이 논문은 주어진 텍스트를 생성할 확률을 모델링하면서도 부족하거나 여분의 문자로 인한 시퀀스 정렬 오차를 고려하는, 어텐션 기반 스트리트 텍스트 인식을 위한 새로운 학습 목표인 편집 확률(Edit Probability, EP)을 제안한다. EP는 잘못 정렬된 문자에 집중하는 경향을 줄이고, 실제 오류 원인인 부족하거나 여분의 문자 위치에 초점을 맞추기 위해 기울기의 재가중을 수행함으로써 학습 혼란을 감소시키고 정확도를 향상시킨다. 이는 유의미한 추론 오버헤드 없이 IIIT-5K, SVT, ICDAR 벤치마크에서 최신 기술 수준의 성능을 달성한다.
We consider the scene text recognition problem under the attention-based encoder-decoder framework, which is the state of the art. The existing methods usually employ a frame-wise maximal likelihood loss to optimize the models. When we train the model, the misalignment between the ground truth strings and the attention's output sequences of probability distribution, which is caused by missing or superfluous characters, will confuse and mislead the training process, and consequently make the training costly and degrade the recognition accuracy. To handle this problem, we propose a novel method called edit probability (EP) for scene text recognition. EP tries to effectively estimate the probability of generating a string from the output sequence of probability distribution conditioned on the input image, while considering the possible occurrences of missing/superfluous characters. The advantage lies in that the training process can focus on the missing, superfluous and unrecognized characters, and thus the impact of the misalignment problem can be alleviated or even overcome. We conduct extensive experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets. Experimental results show that the EP can substantially boost scene text recognition performance.
연구 동기 및 목표
- 학습 중 부족하거나 여분의 문자로 인해 발생하는 어텐션 기반 스트리트 텍스트 인식의 정렬 불일치 문제를 해결하기 위해.
- 잘못 정렬된 문자가 아닌 실제 오류 원인인 부족하거나 여분의 문자에 기울기 역전파의 초점을 이동시킴으로써 학습 혼란과 비용을 줄이기 위해.
- 어텐션 출력 시퀀스와 진짜 문자열 간의 가능한 삽입 및 삭제를 고려하여 진짜 문자열을 생성할 확률을 추정하는 학습 목표를 개발하기 위해.
- 비용이 많이 드는 픽셀 수준의 지도 학습이나 유의미한 추론 시간 증가 없이 인식 정확도를 향상시키기 위해.
제안 방법
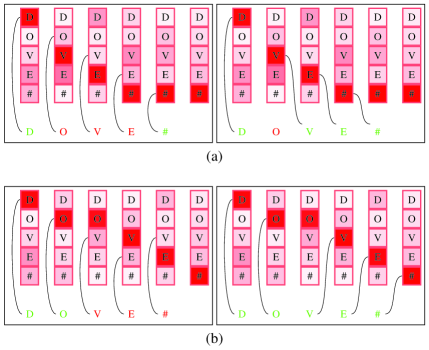
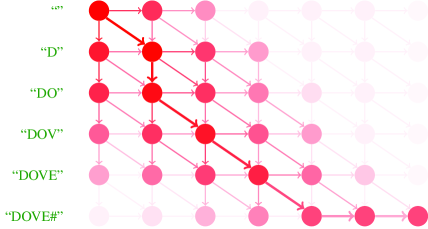
- EP는 어텐션 출력 시퀀스와 진짜 문자열 간의 모든 가능한 편집 연산(삽입, 삭제, 치환)을 고려하여 진짜 문자열을 생성할 확률을 모델링한다.
- 동적 프로그래밍을 사용하여 편집 확률 행렬을 계산하며, 각 항목 (i,j)는 진짜 문자열의 처음 i개 문자와 어텐션 출력의 처음 j개 확률 분포를 정렬할 확률을 나타낸다.
- 행렬 내에서 가장 가능성이 높은 편집 경로를 계산하여 역전파 과정에서 잘못 정렬된 문자가 아닌 부족하거나 여분의 문자 위치에 초점을 맞춘다.
- EP는 기존의 프레임 단위 최대우도 손실을 대체하는 새로운 손실 목표로 학습 과정에 통합되며, 표준 및 어텐션 기반 모델 모두와 호환된다.
- 조정 가능한 하이퍼파라미터 λ를 사용한 어휘 없는 예측 전략을 도입하고, 큰 어휘를 사용할 경우를 고려한 효율적인 EP-Trie 기반 추론 방법을 제안하여 디코딩 속도를 향상시켰다.
- IIIT-5K, SVT, ICDAR와 같은 표준 벤치마크를 사용하여 평가하였으며, 학습 비용과 추론 속도에 대한 분석 실험도 수행하였다.
실험 결과
연구 질문
- RQ1어 attention 출력과 진짜 문자열 간의 편집 연산을 모델링함으로써 스트리트 텍스트 인식에서 학습 안정성과 정확도에 어떤 영향을 미치는가?
- RQ2기울기 역전파 과정에서 부족하거나 여분의 문자로 인한 정렬 불일치의 영향을 줄일 수 있는 미분 가능한 편집 확률 목표는 가능한가?
- RQ3특히 어텐션 드리프트가 발생할 경우, 표준 프레임 단위 최대우도 학습에 비해 EP는 성능을 어느 정도 향상시키는가?
- RQ4큰 어휘를 사용할 경우, EP 기반 학습과 추론은 기존 방법에 비해 얼마나 효율적인가?
주요 결과
- EP는 표준 벤치마크에서 인식 정확도를 크게 향상시켜 IIIT-5K, SVT, ICDAR 데이터셋에서 최신 기술 수준의 성능을 달성한다.
- 배치 크기가 75일 때, EP 기반 방법의 학습 시간은 Shi의 기준 모델 대비 6.8ms, Cheng의 기준 모델 대비 7.0ms 증가할 뿐이며, 유의미한 증가가 없다.
- Hunspell 50k 어휘를 사용할 경우, λ = 0.98에서 성능이 최고에 이르며, λ가 1에 가까워질수록 과도한 보정으로 인해 정확도가 급격히 감소한다.
- EP-Trie 기반 추론 방법은 순열 기반 방법과 동일한 정확도를 달성하지만, 이미지당 추론 시간을 2.566초에서 0.11초로 단축시켰다.
- λ = 0.5를 사용한 어휘 없는 예측 전략은 어휘 없는 기준 모델과 동일한 정확도를 보였으며, 진짜 문자열과 관련된 어휘가 필요 없이도 제안된 방법의 효과성을 입증한다.
- 정렬 불일치가 발생할 경우, EP는 삽입/삭제를 고려함으로써 올바른 정렬에 더 높은 확률을 할당하여, 잘못 인식된 문자에 대한 오류 역전파를 줄인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.